 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan You Solve Closest String Faster than Exhaustive Search?
May 29, 2023We study the fundamental problem of finding the best string to represent a given set, in the form of the Closest String problem: Given a set $X \subseteq \Sigma^d$ of $n$ strings, find the string $x^*$ minimizing the radius of the smallest Hamming ball around $x^*$ that encloses all the strings in $X$. In this paper, we investigate whether the Closest String problem admits algorithms that are faster than the trivial exhaustive search algorithm. We obtain the following results for the two natural versions of the problem: $\bullet$ In the continuous Closest String problem, the goal is to find the solution string $x^*$ anywhere in $\Sigma^d$. For binary strings, the exhaustive search algorithm runs in time $O(2^d poly(nd))$ and we prove that it cannot be improved to time $O(2^{(1-\epsilon) d} poly(nd))$, for any $\epsilon > 0$, unless the Strong Exponential Time Hypothesis fails. $\bullet$ In the discrete Closest String problem, $x^*$ is required to be in the input set $X$. While this problem is clearly in polynomial time, its fine-grained complexity has been pinpointed to be quadratic time $n^{2 \pm o(1)}$ whenever the dimension is $\omega(\log n) < d < n^{o(1)}$. We complement this known hardness result with new algorithms, proving essentially that whenever $d$ falls out of this hard range, the discrete Closest String problem can be solved faster than exhaustive search. In the small-$d$ regime, our algorithm is based on a novel application of the inclusion-exclusion principle. Interestingly, all of our results apply (and some are even stronger) to the natural dual of the Closest String problem, called the Remotest String problem, where the task is to find a string maximizing the Hamming distance to all the strings in $X$.
On Complexity of 1-Center in Various Metrics
Dec 06, 2021We consider the classic 1-center problem: Given a set P of n points in a metric space find the point in P that minimizes the maximum distance to the other points of P. We study the complexity of this problem in d-dimensional $\ell_p$-metrics and in edit and Ulam metrics over strings of length d. Our results for the 1-center problem may be classified based on d as follows. $\bullet$ Small d: We provide the first linear-time algorithm for 1-center problem in fixed-dimensional $\ell_1$ metrics. On the other hand, assuming the hitting set conjecture (HSC), we show that when $d=\omega(\log n)$, no subquadratic algorithm can solve 1-center problem in any of the $\ell_p$-metrics, or in edit or Ulam metrics. $\bullet$ Large d. When $d=\Omega(n)$, we extend our conditional lower bound to rule out sub quartic algorithms for 1-center problem in edit metric (assuming Quantified SETH). On the other hand, we give a $(1+\epsilon)$-approximation for 1-center in Ulam metric with running time $\tilde{O_{\epsilon}}(nd+n^2\sqrt{d})$. We also strengthen some of the above lower bounds by allowing approximations or by reducing the dimension d, but only against a weaker class of algorithms which list all requisite solutions. Moreover, we extend one of our hardness results to rule out subquartic algorithms for the well-studied 1-median problem in the edit metric, where given a set of n strings each of length n, the goal is to find a string in the set that minimizes the sum of the edit distances to the rest of the strings in the set.
Impossibility Results for Grammar-Compressed Linear Algebra
Oct 27, 2020
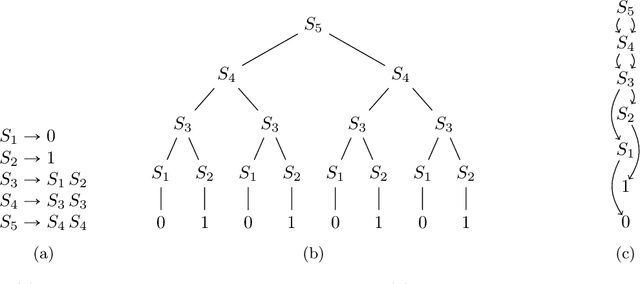
To handle vast amounts of data, it is natural and popular to compress vectors and matrices. When we compress a vector from size $N$ down to size $n \ll N$, it certainly makes it easier to store and transmit efficiently, but does it also make it easier to process? In this paper we consider lossless compression schemes, and ask if we can run our computations on the compressed data as efficiently as if the original data was that small. That is, if an operation has time complexity $T(\rm{inputsize})$, can we perform it on the compressed representation in time $T(n)$ rather than $T(N)$? We consider the most basic linear algebra operations: inner product, matrix-vector multiplication, and matrix multiplication. In particular, given two compressed vectors, can we compute their inner product in time $O(n)$? Or perhaps we must decompress first and then multiply, spending $\Omega(N)$ time? The answer depends on the compression scheme. While for simple ones such as Run-Length-Encoding (RLE) the inner product can be done in $O(n)$ time, we prove that this is impossible for compressions from a richer class: essentially $n^2$ or even larger runtimes are needed in the worst case (under complexity assumptions). This is the class of grammar-compressions containing most popular methods such as the Lempel-Ziv family. These schemes are more compressing than the simple RLE, but alas, we prove that performing computations on them is much harder.