 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Aggregate responses: Instance Level versus Bag Level Loss Functions
Paper and Code
Jan 20, 2024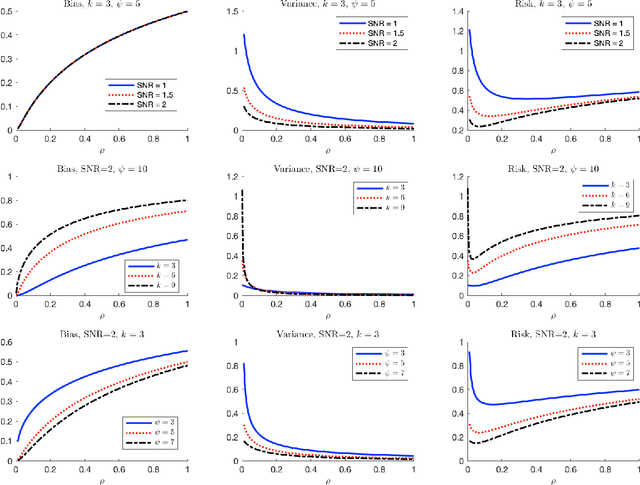
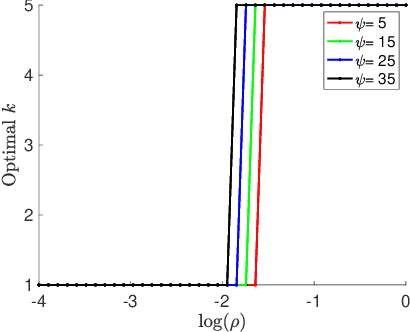
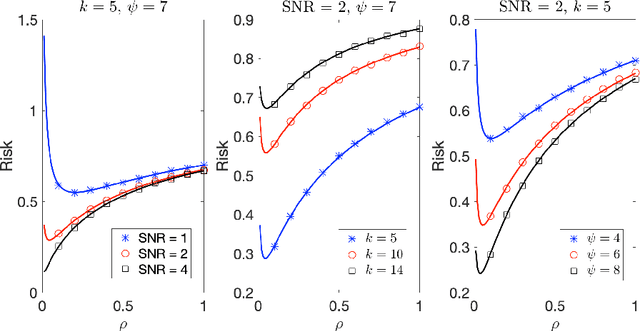
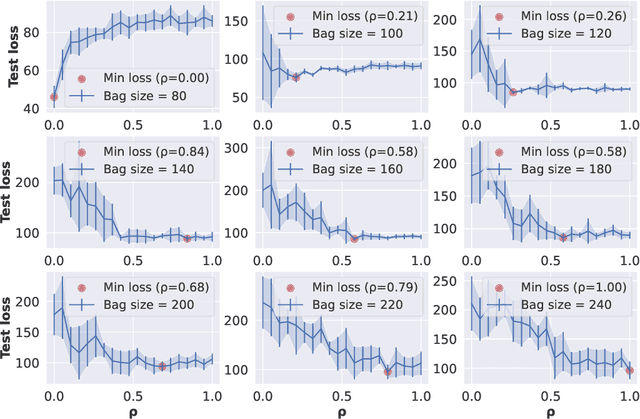
Due to the rise of privacy concerns, in many practical applications the training data is aggregated before being shared with the learner, in order to protect privacy of users' sensitive responses. In an aggregate learning framework, the dataset is grouped into bags of samples, where each bag is available only with an aggregate response, providing a summary of individuals' responses in that bag. In this paper, we study two natural loss functions for learning from aggregate responses: bag-level loss and the instance-level loss. In the former, the model is learnt by minimizing a loss between aggregate responses and aggregate model predictions, while in the latter the model aims to fit individual predictions to the aggregate responses. In this work, we show that the instance-level loss can be perceived as a regularized form of the bag-level loss. This observation lets us compare the two approaches with respect to bias and variance of the resulting estimators, and introduce a novel interpolating estimator which combines the two approaches. For linear regression tasks, we provide a precise characterization of the risk of the interpolating estimator in an asymptotic regime where the size of the training set grows in proportion to the features dimension. Our analysis allows us to theoretically understand the effect of different factors, such as bag size on the model prediction risk. In addition, we propose a mechanism for differentially private learning from aggregate responses and derive the optimal bag size in terms of prediction risk-privacy trade-off. We also carry out thorough experiments to corroborate our theory and show the efficacy of the interpolating estimator.