 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-scale Sampling and Aggregation Network For High Dynamic Range Imaging
Aug 04, 2022

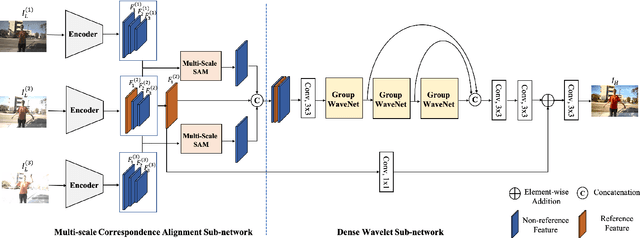
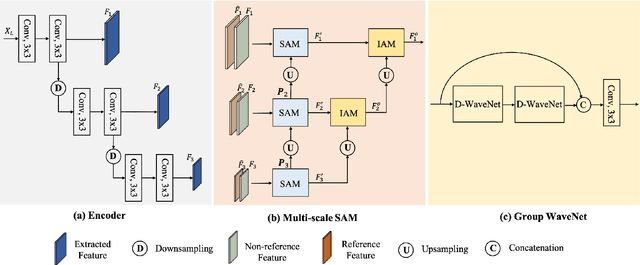
High dynamic range (HDR) imaging is a fundamental problem in image processing, which aims to generate well-exposed images, even in the presence of varying illumination in the scenes. In recent years, multi-exposure fusion methods have achieved remarkable results, which merge multiple low dynamic range (LDR) images, captured with different exposures, to generate corresponding HDR images. However, synthesizing HDR images in dynamic scenes is still challenging and in high demand. There are two challenges in producing HDR images: 1). Object motion between LDR images can easily cause undesirable ghosting artifacts in the generated results. 2). Under and overexposed regions often contain distorted image content, because of insufficient compensation for these regions in the merging stage. In this paper, we propose a multi-scale sampling and aggregation network for HDR imaging in dynamic scenes. To effectively alleviate the problems caused by small and large motions, our method implicitly aligns LDR images by sampling and aggregating high-correspondence features in a coarse-to-fine manner. Furthermore, we propose a densely connected network based on discrete wavelet transform for performance improvement, which decomposes the input into several non-overlapping frequency subbands and adaptively performs compensation in the wavelet domain. Experiments show that our proposed method can achieve state-of-the-art performances under diverse scenes, compared to other promising HDR imaging methods. In addition, the HDR images generated by our method contain cleaner and more detailed content, with fewer distortions, leading to better visual quality.
Deep Multi-task Learning for Facial Expression Recognition and Synthesis Based on Selective Feature Sharing
Jul 09, 2020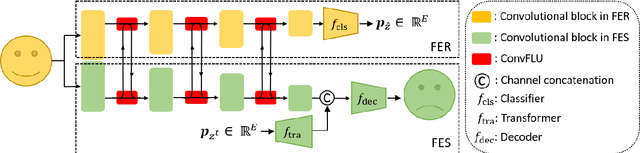
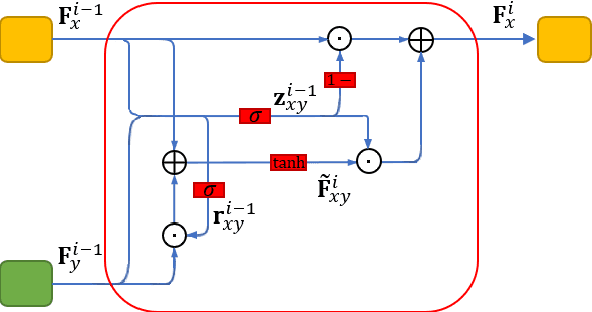
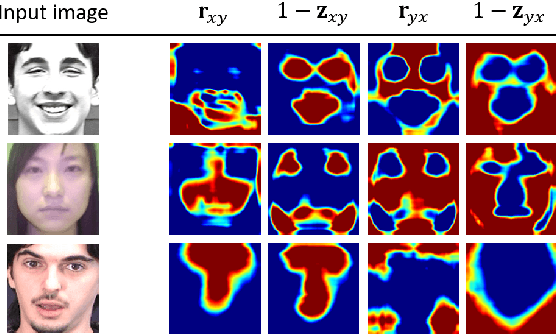
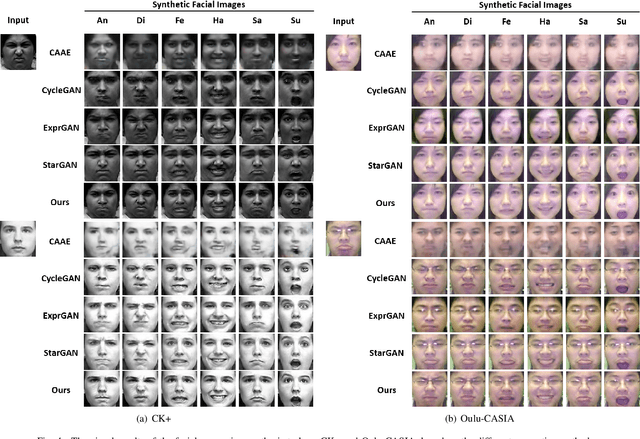
Multi-task learning is an effective learning strategy for deep-learning-based facial expression recognition tasks. However, most existing methods take into limited consideration the feature selection, when transferring information between different tasks, which may lead to task interference when training the multi-task networks. To address this problem, we propose a novel selective feature-sharing method, and establish a multi-task network for facial expression recognition and facial expression synthesis. The proposed method can effectively transfer beneficial features between different tasks, while filtering out useless and harmful information. Moreover, we employ the facial expression synthesis task to enlarge and balance the training dataset to further enhance the generalization ability of the proposed method. Experimental results show that the proposed method achieves state-of-the-art performance on those commonly used facial expression recognition benchmarks, which makes it a potential solution to real-world facial expression recognition problems.