 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Multiple-Image-Based Reflection Removal Algorithm Using Deep Neural Networks
Aug 10, 2022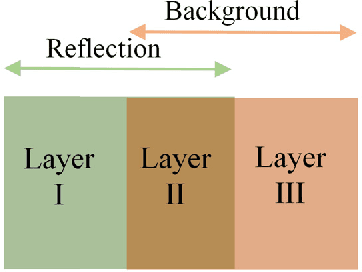


When imaging through a semi-reflective medium such as glass, the reflection of another scene can often be found in the captured images. It degrades the quality of the images and affects their subsequent analyses. In this paper, a novel deep neural network approach for solving the reflection problem in imaging is presented. Traditional reflection removal methods not only require long computation time for solving different optimization functions, their performance is also not guaranteed. As array cameras are readily available in nowadays imaging devices, we first suggest in this paper a multiple-image based depth estimation method using a convolutional neural network (CNN). The proposed network avoids the depth ambiguity problem due to the reflection in the image, and directly estimates the depths along the image edges. They are then used to classify the edges as belonging to the background or reflection. Since edges having similar depth values are error prone in the classification, they are removed from the reflection removal process. We suggest a generative adversarial network (GAN) to regenerate the removed background edges. Finally, the estimated background edge map is fed to another auto-encoder network to assist the extraction of the background from the original image. Experimental results show that the proposed reflection removal algorithm achieves superior performance both quantitatively and qualitatively as compared to the state-of-the-art methods. The proposed algorithm also shows much faster speed compared to the existing approaches using the traditional optimization methods.
SiPRNet: End-to-End Learning for Single-Shot Phase Retrieval
May 23, 2022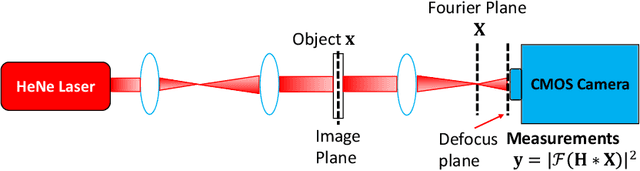
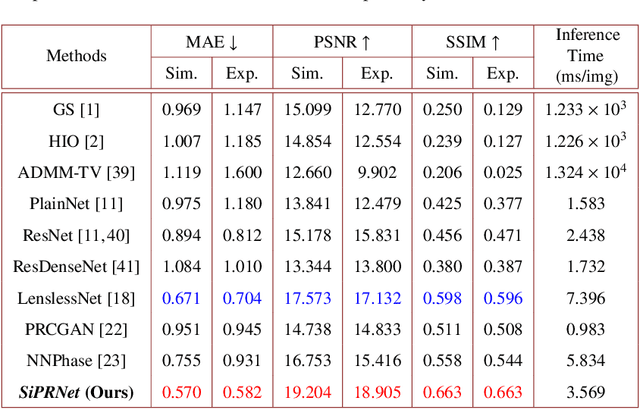
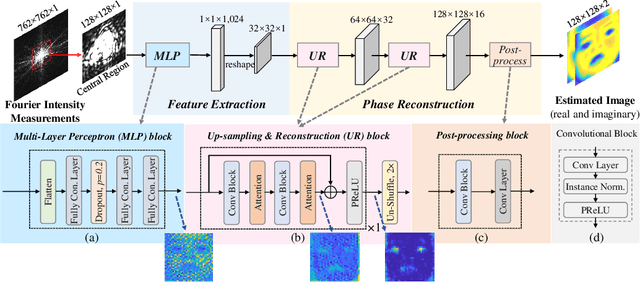
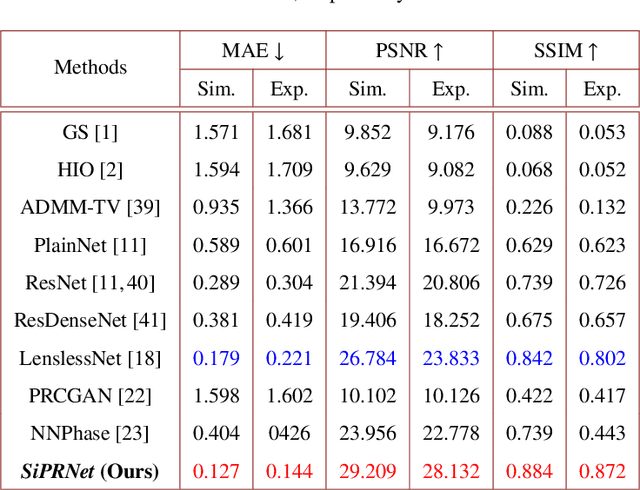
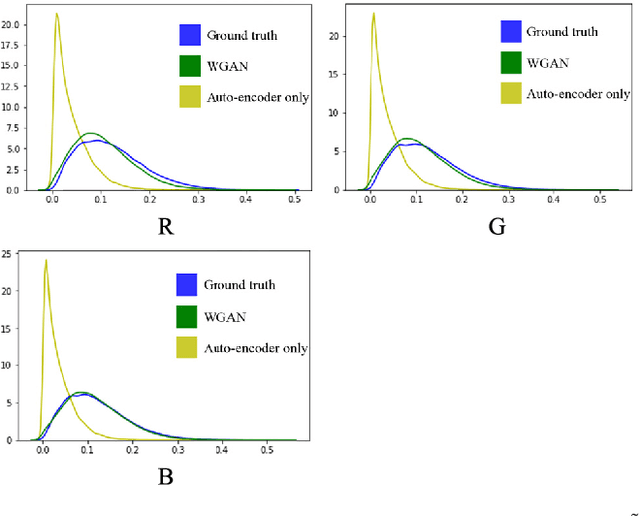
Traditional optimization algorithms have been developed to deal with the phase retrieval problem. However, multiple measurements with different random or non-random masks are needed for giving a satisfactory performance. This brings a burden to the implementation of the algorithms in practical systems. Even worse, expensive optical devices are required to implement the optical masks. Recently, deep learning, especially convolutional neural networks (CNN), has played important roles in various image reconstruction tasks. However, traditional CNN structure fails to reconstruct the original images from their Fourier measurements because of tremendous domain discrepancy. In this paper, we design a novel CNN structure, named SiPRNet, to recover a signal from a single Fourier intensity measurement. To effectively utilize the spectral information of the measurements, we propose a new Multi-Layer Perception block embedded with the dropout layer to extract the global representations. Two Up-sampling and Reconstruction blocks with self-attention are utilized to recover the signals from the extracted features. Extensive evaluations of the proposed model are performed using different testing datasets on both simulation and optical experimentation platforms. The results demonstrate that the proposed approach consistently outperforms other CNN-based and traditional optimization-based methods in single-shot maskless phase retrieval. The source codes of the proposed method have been released on Github: https://github.com/Qiustander/SiPRNet.
NTGAN: Learning Blind Image Denoising without Clean Reference
Sep 09, 2020

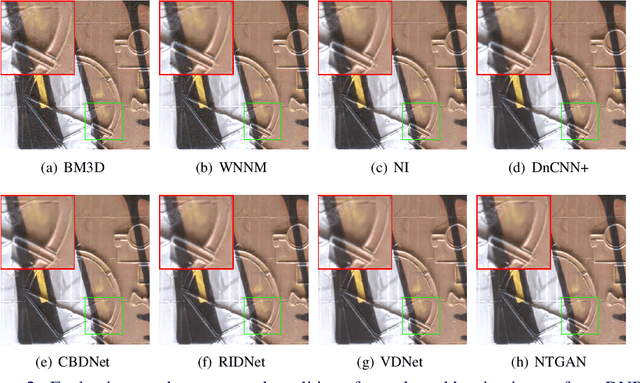
Recent studies on learning-based image denoising have achieved promising performance on various noise reduction tasks. Most of these deep denoisers are trained either under the supervision of clean references, or unsupervised on synthetic noise. The assumption with the synthetic noise leads to poor generalization when facing real photographs. To address this issue, we propose a novel deep unsupervised image-denoising method by regarding the noise reduction task as a special case of the noise transference task. Learning noise transference enables the network to acquire the denoising ability by only observing the corrupted samples. The results on real-world denoising benchmarks demonstrate that our proposed method achieves state-of-the-art performance on removing realistic noises, making it a potential solution to practical noise reduction problems.
Deep Relighting Networks for Image Light Source Manipulation
Aug 19, 2020

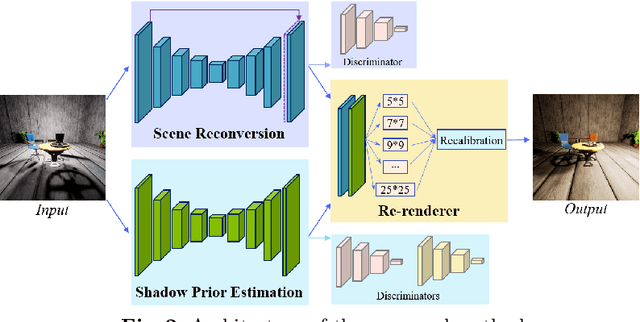
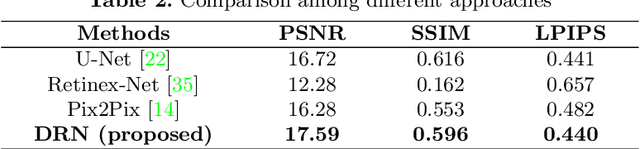
Manipulating the light source of given images is an interesting task and useful in various applications, including photography and cinematography. Existing methods usually require additional information like the geometric structure of the scene, which may not be available for most images. In this paper, we formulate the single image relighting task and propose a novel Deep Relighting Network (DRN) with three parts: 1) scene reconversion, which aims to reveal the primary scene structure through a deep auto-encoder network, 2) shadow prior estimation, to predict light effect from the new light direction through adversarial learning, and 3) re-renderer, to combine the primary structure with the reconstructed shadow view to form the required estimation under the target light source. Experimental results show that the proposed method outperforms other possible methods, both qualitatively and quantitatively. Specifically, the proposed DRN has achieved the best PSNR in the "AIM2020 - Any to one relighting challenge" of the 2020 ECCV conference.
Deep Multi-task Learning for Facial Expression Recognition and Synthesis Based on Selective Feature Sharing
Jul 09, 2020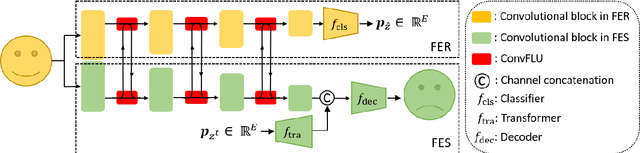
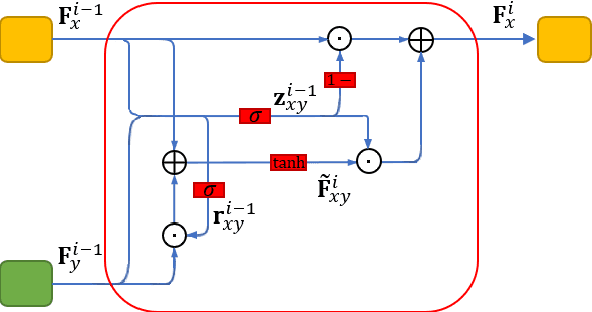
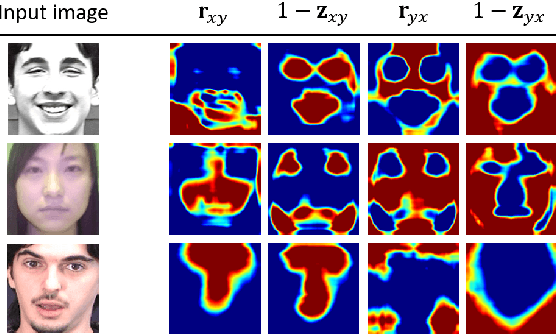
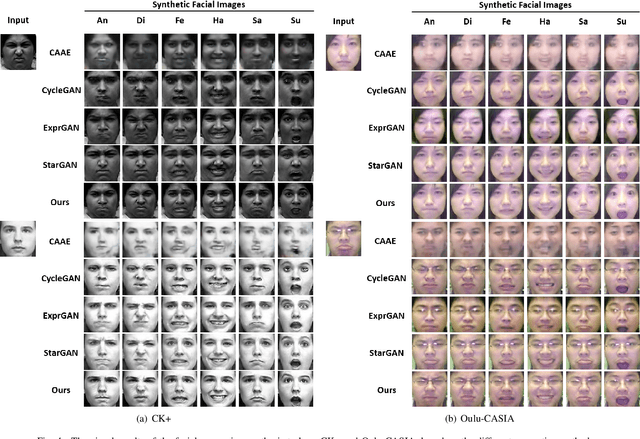
Multi-task learning is an effective learning strategy for deep-learning-based facial expression recognition tasks. However, most existing methods take into limited consideration the feature selection, when transferring information between different tasks, which may lead to task interference when training the multi-task networks. To address this problem, we propose a novel selective feature-sharing method, and establish a multi-task network for facial expression recognition and facial expression synthesis. The proposed method can effectively transfer beneficial features between different tasks, while filtering out useless and harmful information. Moreover, we employ the facial expression synthesis task to enlarge and balance the training dataset to further enhance the generalization ability of the proposed method. Experimental results show that the proposed method achieves state-of-the-art performance on those commonly used facial expression recognition benchmarks, which makes it a potential solution to real-world facial expression recognition problems.
Enhancement of a CNN-Based Denoiser Based on Spatial and Spectral Analysis
Jun 28, 2020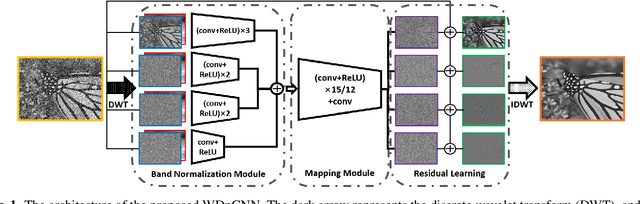


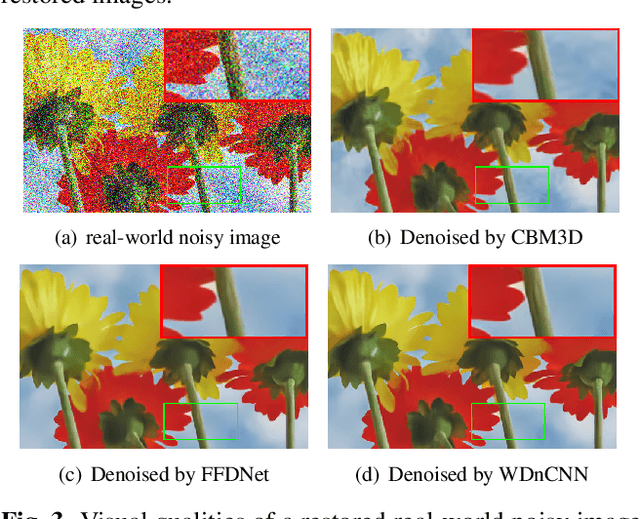
Convolutional neural network (CNN)-based image denoising methods have been widely studied recently, because of their high-speed processing capability and good visual quality. However, most of the existing CNN-based denoisers learn the image prior from the spatial domain, and suffer from the problem of spatially variant noise, which limits their performance in real-world image denoising tasks. In this paper, we propose a discrete wavelet denoising CNN (WDnCNN), which restores images corrupted by various noise with a single model. Since most of the content or energy of natural images resides in the low-frequency spectrum, their transformed coefficients in the frequency domain are highly imbalanced. To address this issue, we present a band normalization module (BNM) to normalize the coefficients from different parts of the frequency spectrum. Moreover, we employ a band discriminative training (BDT) criterion to enhance the model regression. We evaluate the proposed WDnCNN, and compare it with other state-of-the-art denoisers. Experimental results show that WDnCNN achieves promising performance in both synthetic and real noise reduction, making it a potential solution to many practical image denoising applications.