 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAIM 2020: Scene Relighting and Illumination Estimation Challenge
Sep 27, 2020

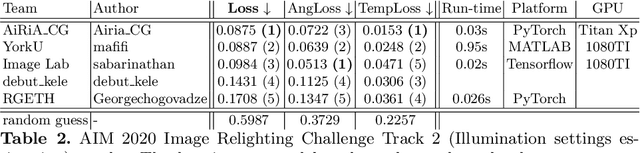

We review the AIM 2020 challenge on virtual image relighting and illumination estimation. This paper presents the novel VIDIT dataset used in the challenge and the different proposed solutions and final evaluation results over the 3 challenge tracks. The first track considered one-to-one relighting; the objective was to relight an input photo of a scene with a different color temperature and illuminant orientation (i.e., light source position). The goal of the second track was to estimate illumination settings, namely the color temperature and orientation, from a given image. Lastly, the third track dealt with any-to-any relighting, thus a generalization of the first track. The target color temperature and orientation, rather than being pre-determined, are instead given by a guide image. Participants were allowed to make use of their track 1 and 2 solutions for track 3. The tracks had 94, 52, and 56 registered participants, respectively, leading to 20 confirmed submissions in the final competition stage.
AIM 2020 Challenge on Real Image Super-Resolution: Methods and Results
Sep 25, 2020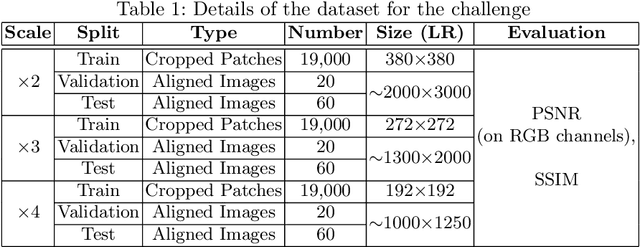
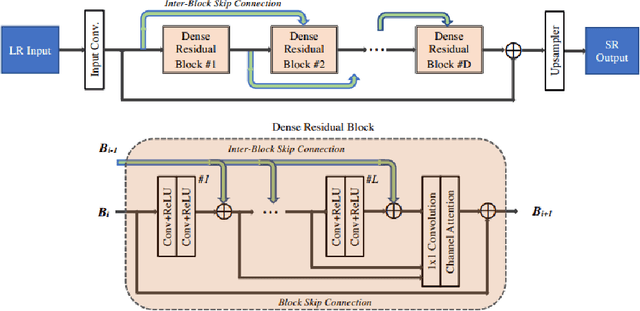
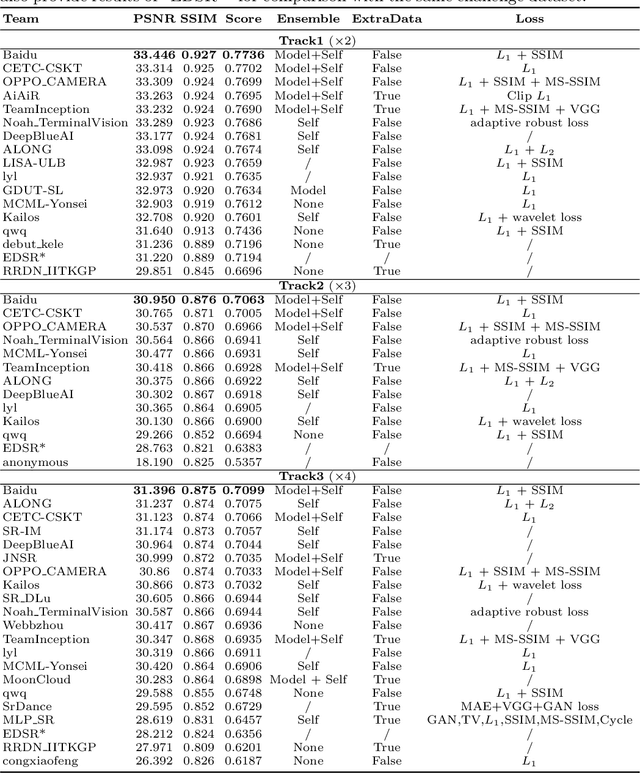
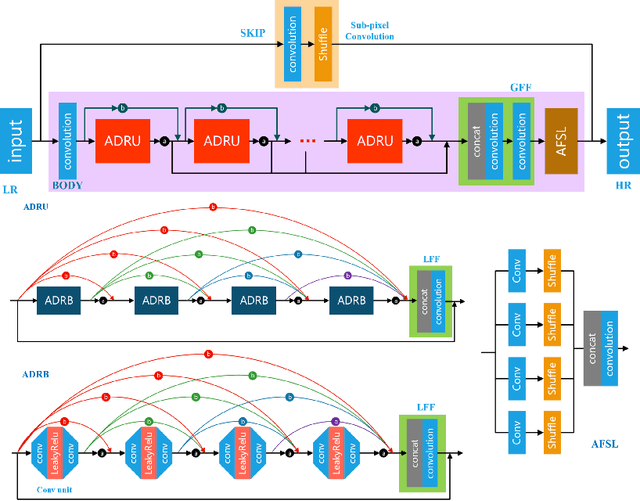
This paper introduces the real image Super-Resolution (SR) challenge that was part of the Advances in Image Manipulation (AIM) workshop, held in conjunction with ECCV 2020. This challenge involves three tracks to super-resolve an input image for $\times$2, $\times$3 and $\times$4 scaling factors, respectively. The goal is to attract more attention to realistic image degradation for the SR task, which is much more complicated and challenging, and contributes to real-world image super-resolution applications. 452 participants were registered for three tracks in total, and 24 teams submitted their results. They gauge the state-of-the-art approaches for real image SR in terms of PSNR and SSIM.
Deep Relighting Networks for Image Light Source Manipulation
Aug 19, 2020

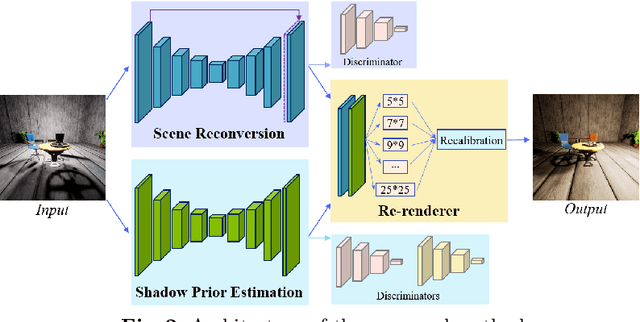
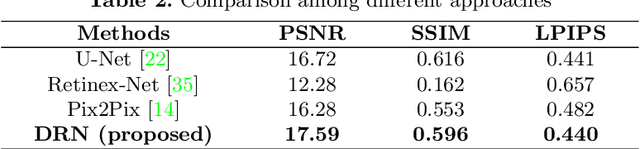
Manipulating the light source of given images is an interesting task and useful in various applications, including photography and cinematography. Existing methods usually require additional information like the geometric structure of the scene, which may not be available for most images. In this paper, we formulate the single image relighting task and propose a novel Deep Relighting Network (DRN) with three parts: 1) scene reconversion, which aims to reveal the primary scene structure through a deep auto-encoder network, 2) shadow prior estimation, to predict light effect from the new light direction through adversarial learning, and 3) re-renderer, to combine the primary structure with the reconstructed shadow view to form the required estimation under the target light source. Experimental results show that the proposed method outperforms other possible methods, both qualitatively and quantitatively. Specifically, the proposed DRN has achieved the best PSNR in the "AIM2020 - Any to one relighting challenge" of the 2020 ECCV conference.
DeepGIN: Deep Generative Inpainting Network for Extreme Image Inpainting
Aug 17, 2020
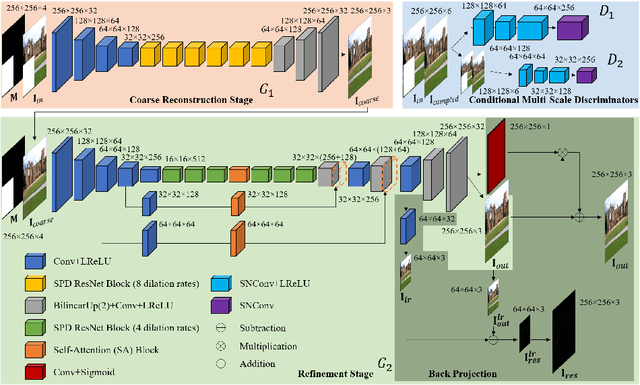
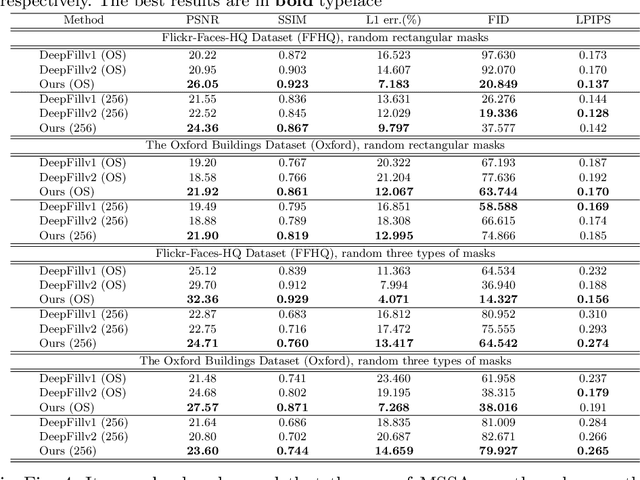
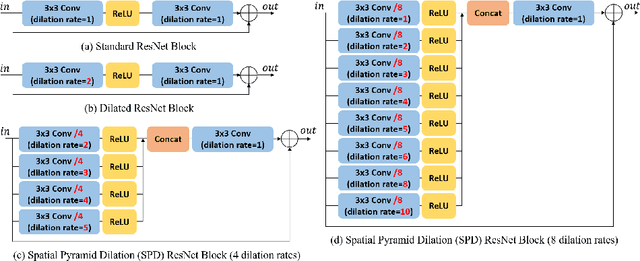
The degree of difficulty in image inpainting depends on the types and sizes of the missing parts. Existing image inpainting approaches usually encounter difficulties in completing the missing parts in the wild with pleasing visual and contextual results as they are trained for either dealing with one specific type of missing patterns (mask) or unilaterally assuming the shapes and/or sizes of the masked areas. We propose a deep generative inpainting network, named DeepGIN, to handle various types of masked images. We design a Spatial Pyramid Dilation (SPD) ResNet block to enable the use of distant features for reconstruction. We also employ Multi-Scale Self-Attention (MSSA) mechanism and Back Projection (BP) technique to enhance our inpainting results. Our DeepGIN outperforms the state-of-the-art approaches generally, including two publicly available datasets (FFHQ and Oxford Buildings), both quantitatively and qualitatively. We also demonstrate that our model is capable of completing masked images in the wild.
Unsupervised Real Image Super-Resolution via Generative Variational AutoEncoder
Apr 27, 2020
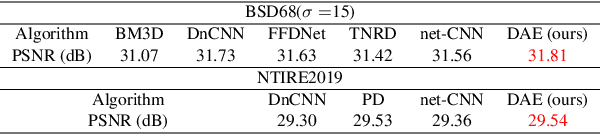
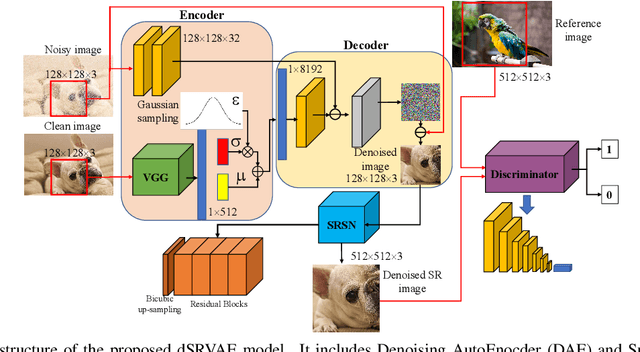

Benefited from the deep learning, image Super-Resolution has been one of the most developing research fields in computer vision. Depending upon whether using a discriminator or not, a deep convolutional neural network can provide an image with high fidelity or better perceptual quality. Due to the lack of ground truth images in real life, people prefer a photo-realistic image with low fidelity to a blurry image with high fidelity. In this paper, we revisit the classic example based image super-resolution approaches and come up with a novel generative model for perceptual image super-resolution. Given that real images contain various noise and artifacts, we propose a joint image denoising and super-resolution model via Variational AutoEncoder. We come up with a conditional variational autoencoder to encode the reference for dense feature vector which can then be transferred to the decoder for target image denoising. With the aid of the discriminator, an additional overhead of super-resolution subnetwork is attached to super-resolve the denoised image with photo-realistic visual quality. We participated the NTIRE2020 Real Image Super-Resolution Challenge. Experimental results show that by using the proposed approach, we can obtain enlarged images with clean and pleasant features compared to other supervised methods. We also compared our approach with state-of-the-art methods on various datasets to demonstrate the efficiency of our proposed unsupervised super-resolution model.
* 9 pages, 7 figures, CVPR2020 NTIRE2020 Real Image Super-Resolution Challenge
Image Super-Resolution via Attention based Back Projection Networks
Oct 10, 2019



Deep learning based image Super-Resolution (SR) has shown rapid development due to its ability of big data digestion. Generally, deeper and wider networks can extract richer feature maps and generate SR images with remarkable quality. However, the more complex network we have, the more time consumption is required for practical applications. It is important to have a simplified network for efficient image SR. In this paper, we propose an Attention based Back Projection Network (ABPN) for image super-resolution. Similar to some recent works, we believe that the back projection mechanism can be further developed for SR. Enhanced back projection blocks are suggested to iteratively update low- and high-resolution feature residues. Inspired by recent studies on attention models, we propose a Spatial Attention Block (SAB) to learn the cross-correlation across features at different layers. Based on the assumption that a good SR image should be close to the original LR image after down-sampling. We propose a Refined Back Projection Block (RBPB) for final reconstruction. Extensive experiments on some public and AIM2019 Image Super-Resolution Challenge datasets show that the proposed ABPN can provide state-of-the-art or even better performance in both quantitative and qualitative measurements.
* 9 pages, 7 figures, ABPN
Hierarchical Back Projection Network for Image Super-Resolution
Jun 20, 2019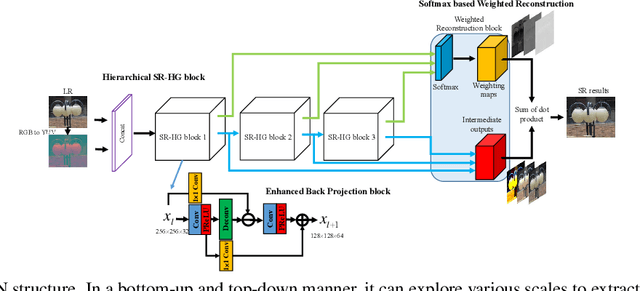

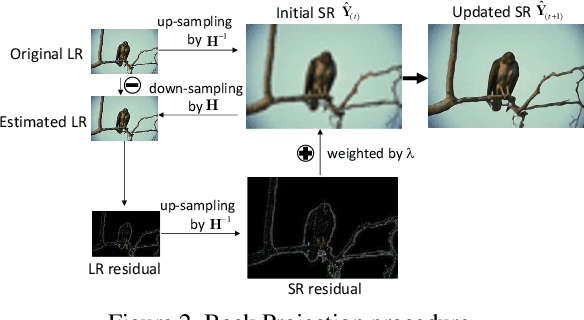

Deep learning based single image super-resolution methods use a large number of training datasets and have recently achieved great quality progress both quantitatively and qualitatively. Most deep networks focus on nonlinear mapping from low-resolution inputs to high-resolution outputs via residual learning without exploring the feature abstraction and analysis. We propose a Hierarchical Back Projection Network (HBPN), that cascades multiple HourGlass (HG) modules to bottom-up and top-down process features across all scales to capture various spatial correlations and then consolidates the best representation for reconstruction. We adopt the back projection blocks in our proposed network to provide the error correlated up and down-sampling process to replace simple deconvolution and pooling process for better estimation. A new Softmax based Weighted Reconstruction (WR) process is used to combine the outputs of HG modules to further improve super-resolution. Experimental results on various datasets (including the validation dataset, NTIRE2019, of the Real Image Super-resolution Challenge) show that our proposed approach can achieve and improve the performance of the state-of-the-art methods for different scaling factors.