 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsistency of Implicit and Explicit Features Matters for Monocular 3D Object Detection
Paper and Code
Jul 16, 2022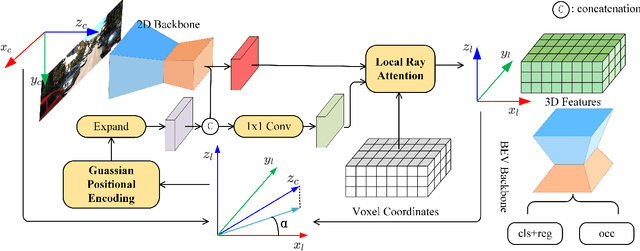
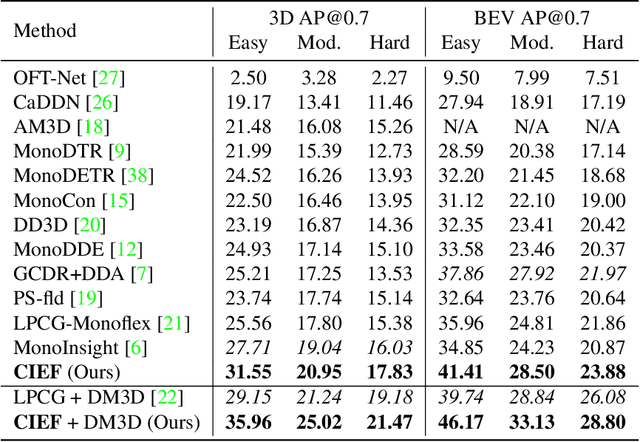
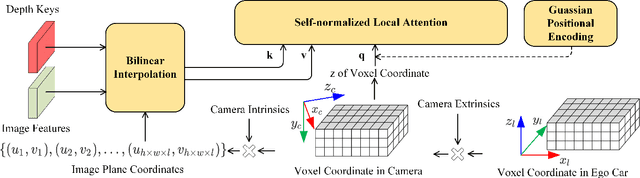
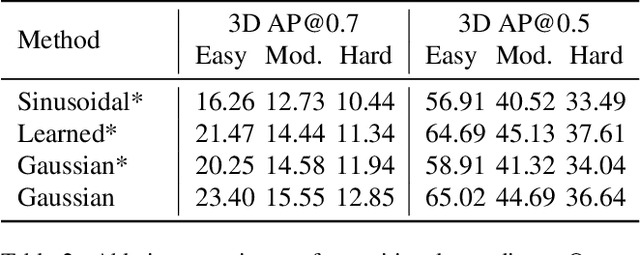
Monocular 3D object detection is a common solution for low-cost autonomous agents to perceive their surrounding environment. Monocular detection has progressed into two categories: (1)Direct methods that infer 3D bounding boxes directly from a frontal-view image; (2)3D intermedia representation methods that map image features to 3D space for subsequent 3D detection. The second category is standing out not only because 3D detection forges ahead at the mercy of more meaningful and representative features, but because of emerging SOTA end-to-end prediction and planning paradigms that require a bird's-eye-view feature map from a perception pipeline. However, in transforming to 3D representation, these methods do not guarantee that objects' implicit orientations and locations in latent space are consistent with those explicitly observed in Euclidean space, which will hurt model performance. Hence, we argue that the consistency of implicit and explicit features matters and present a novel monocular detection method, named CIEF, with the first orientation-aware image backbone to eliminate the disparity of implicit and explicit features in subsequent 3D representation. As a second contribution, we introduce a ray attention mechanism. In contrast to previous methods that repeat features along the projection ray or rely on another intermedia frustum point cloud, we directly transform image features to voxel representations with well-localized features. We also propose a handcrafted gaussian positional encoding function that outperforms the sinusoidal encoding function but maintains the benefit of being continuous. CIEF ranked 1st among all reported methods on both 3D and BEV detection benchmark of KITTI at submission time.