 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRTBAgent: A LLM-based Agent System for Real-Time Bidding
Feb 02, 2025



Real-Time Bidding (RTB) enables advertisers to place competitive bids on impression opportunities instantaneously, striving for cost-effectiveness in a highly competitive landscape. Although RTB has widely benefited from the utilization of technologies such as deep learning and reinforcement learning, the reliability of related methods often encounters challenges due to the discrepancies between online and offline environments and the rapid fluctuations of online bidding. To handle these challenges, RTBAgent is proposed as the first RTB agent system based on large language models (LLMs), which synchronizes real competitive advertising bidding environments and obtains bidding prices through an integrated decision-making process. Specifically, obtaining reasoning ability through LLMs, RTBAgent is further tailored to be more professional for RTB via involved auxiliary modules, i.e., click-through rate estimation model, expert strategy knowledge, and daily reflection. In addition, we propose a two-step decision-making process and multi-memory retrieval mechanism, which enables RTBAgent to review historical decisions and transaction records and subsequently make decisions more adaptive to market changes in real-time bidding. Empirical testing with real advertising datasets demonstrates that RTBAgent significantly enhances profitability. The RTBAgent code will be publicly accessible at: https://github.com/CaiLeng/RTBAgent.
Qtrade AI at SemEval-2022 Task 11: An Unified Framework for Multilingual NER Task
Apr 14, 2022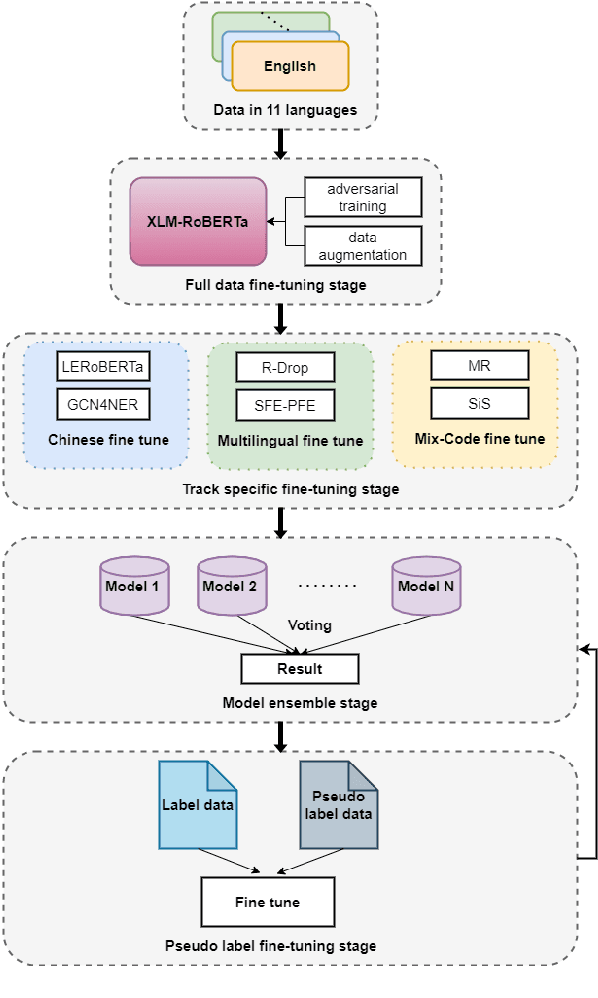
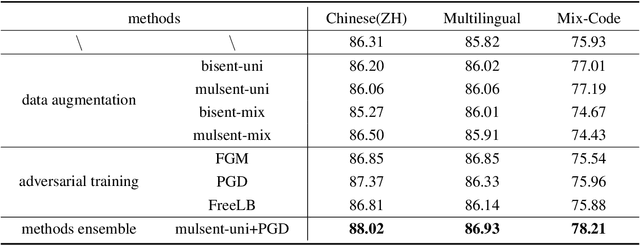
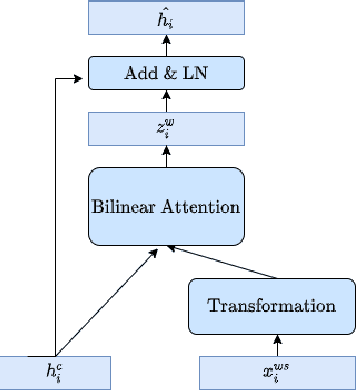
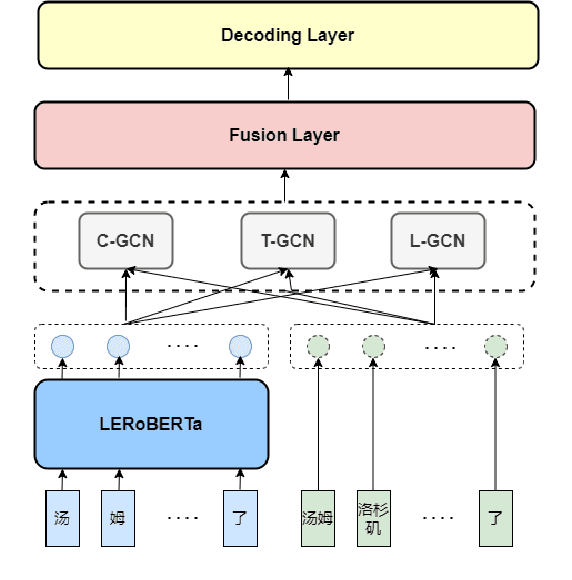
This paper describes our system, which placed third in the Multilingual Track (subtask 11), fourth in the Code-Mixed Track (subtask 12), and seventh in the Chinese Track (subtask 9) in the SemEval 2022 Task 11: MultiCoNER Multilingual Complex Named Entity Recognition. Our system's key contributions are as follows: 1) For multilingual NER tasks, we offer an unified framework with which one can easily execute single-language or multilingual NER tasks, 2) for low-resource code-mixed NER task, one can easily enhance his or her dataset through implementing several simple data augmentation methods and 3) for Chinese tasks, we propose a model that can capture Chinese lexical semantic, lexical border, and lexical graph structural information. Finally, our system achieves macro-f1 scores of 77.66, 84.35, and 74.00 on subtasks 11, 12, and 9, respectively, during the testing phase.
Domain Adaptive Learning Based on Sample-Dependent and Learnable Kernels
Feb 18, 2021
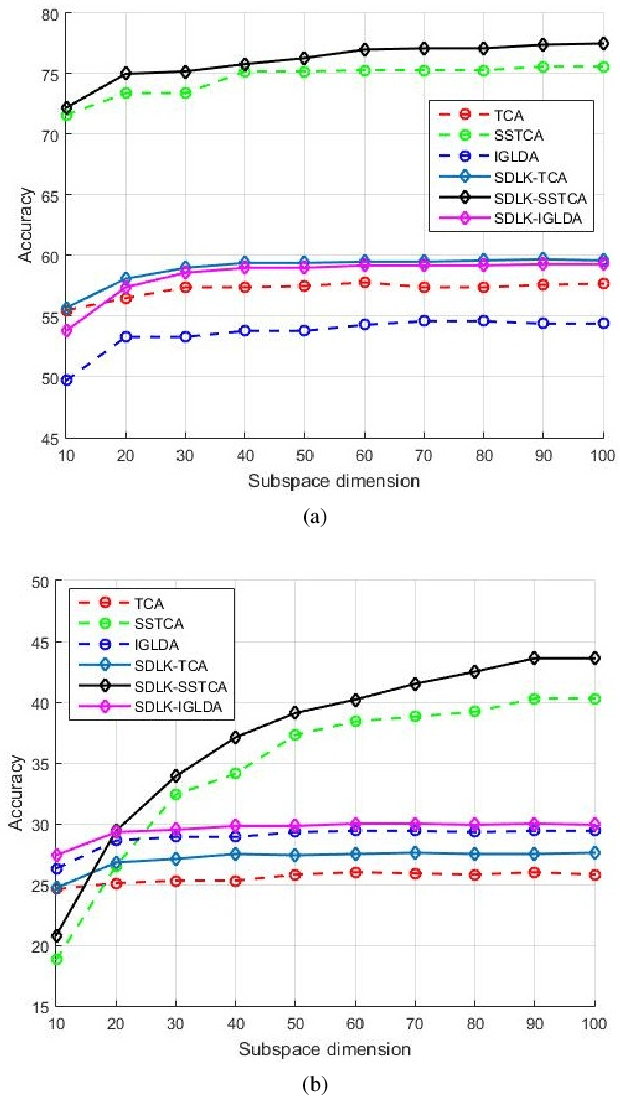

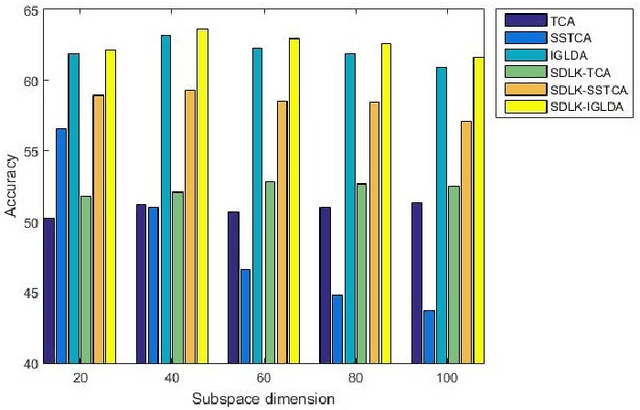
Reproducing Kernel Hilbert Space (RKHS) is the common mathematical platform for various kernel methods in machine learning. The purpose of kernel learning is to learn an appropriate RKHS according to different machine learning scenarios and training samples. Because RKHS is uniquely generated by the kernel function, kernel learning can be regarded as kernel function learning. This paper proposes a Domain Adaptive Learning method based on Sample-Dependent and Learnable Kernels (SDLK-DAL). The first contribution of our work is to propose a sample-dependent and learnable Positive Definite Quadratic Kernel function (PDQK) framework. Unlike learning the exponential parameter of Gaussian kernel function or the coefficient of kernel combinations, the proposed PDQK is a positive definite quadratic function, in which the symmetric positive semi-definite matrix is the learnable part in machine learning applications. The second contribution lies on that we apply PDQK to Domain Adaptive Learning (DAL). Our approach learns the PDQK through minimizing the mean discrepancy between the data of source domain and target domain and then transforms the data into an optimized RKHS generated by PDQK. We conduct a series of experiments that the RKHS determined by PDQK replaces those in several state-of-the-art DAL algorithms, and our approach achieves better performance.