 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Adaptive Learning Based on Sample-Dependent and Learnable Kernels
Feb 18, 2021
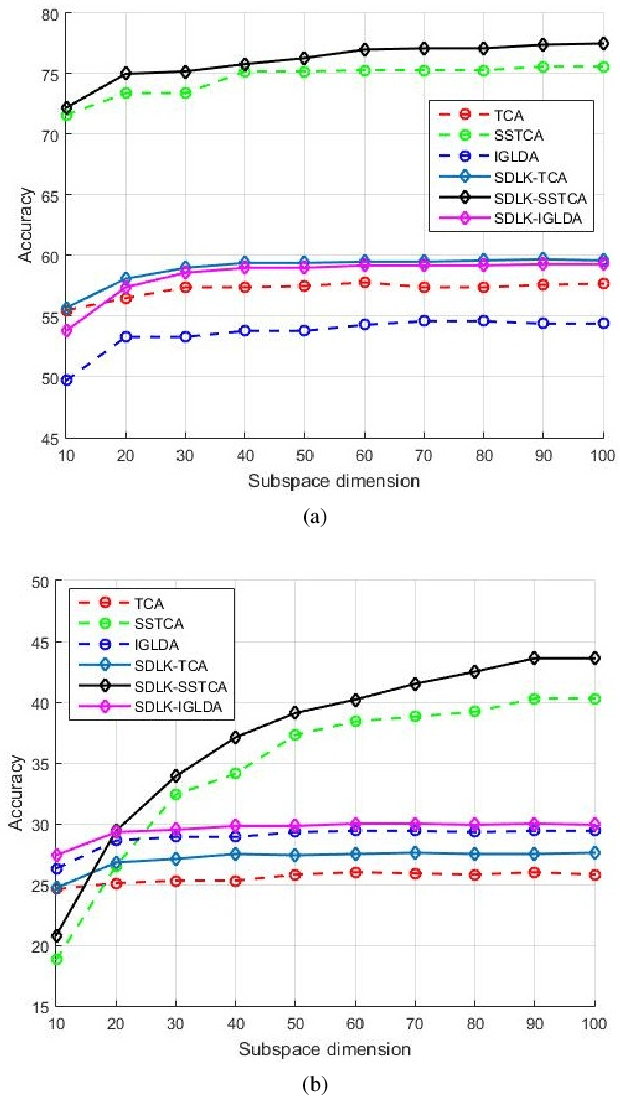

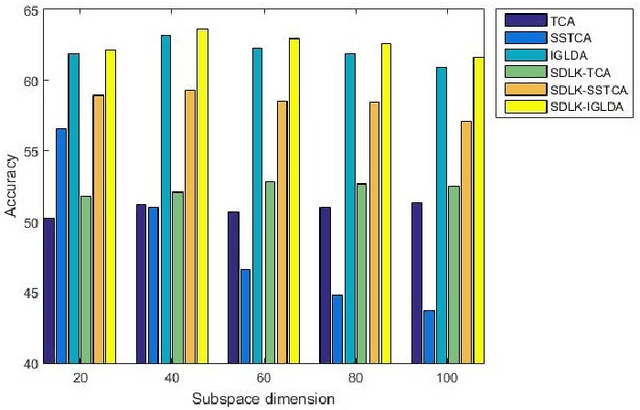
Reproducing Kernel Hilbert Space (RKHS) is the common mathematical platform for various kernel methods in machine learning. The purpose of kernel learning is to learn an appropriate RKHS according to different machine learning scenarios and training samples. Because RKHS is uniquely generated by the kernel function, kernel learning can be regarded as kernel function learning. This paper proposes a Domain Adaptive Learning method based on Sample-Dependent and Learnable Kernels (SDLK-DAL). The first contribution of our work is to propose a sample-dependent and learnable Positive Definite Quadratic Kernel function (PDQK) framework. Unlike learning the exponential parameter of Gaussian kernel function or the coefficient of kernel combinations, the proposed PDQK is a positive definite quadratic function, in which the symmetric positive semi-definite matrix is the learnable part in machine learning applications. The second contribution lies on that we apply PDQK to Domain Adaptive Learning (DAL). Our approach learns the PDQK through minimizing the mean discrepancy between the data of source domain and target domain and then transforms the data into an optimized RKHS generated by PDQK. We conduct a series of experiments that the RKHS determined by PDQK replaces those in several state-of-the-art DAL algorithms, and our approach achieves better performance.
HyperNTF: A Hypergraph Regularized Nonnegative Tensor Factorization for Dimensionality Reduction
Jan 26, 2021

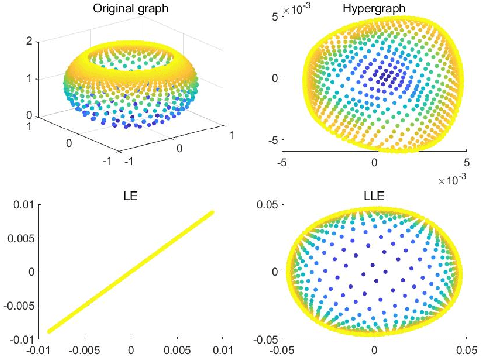
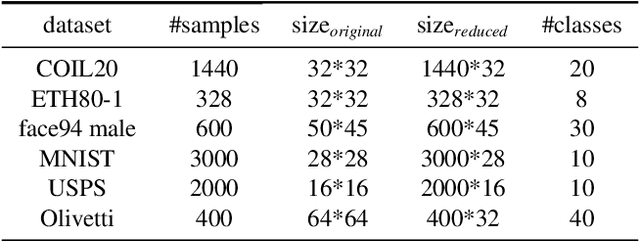
Most methods for dimensionality reduction are based on either tensor representation or local geometry learning. However, the tensor-based methods severely rely on the assumption of global and multilinear structures in high-dimensional data; and the manifold learning methods suffer from the out-of-sample problem. In this paper, bridging the tensor decomposition and manifold learning, we propose a novel method, called Hypergraph Regularized Nonnegative Tensor Factorization (HyperNTF). HyperNTF can preserve nonnegativity in tensor factorization, and uncover the higher-order relationship among the nearest neighborhoods. Clustering analysis with HyperNTF has low computation and storage costs. The experiments on four synthetic data show a desirable property of hypergraph in uncovering the high-order correlation to unfold the curved manifolds. Moreover, the numerical experiments on six real datasets suggest that HyperNTF robustly outperforms state-of-the-art algorithms in clustering analysis.
Riemannian-based Discriminant Analysis for Feature Extraction and Classification
Jan 26, 2021
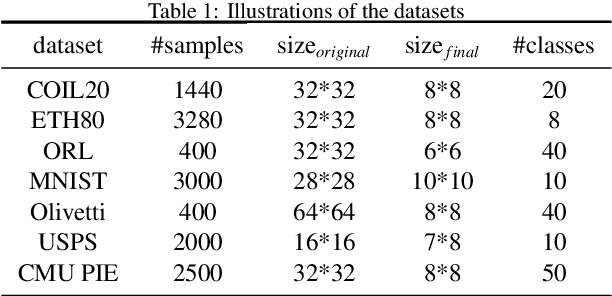
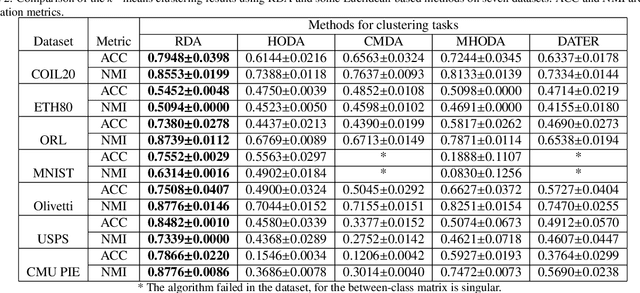
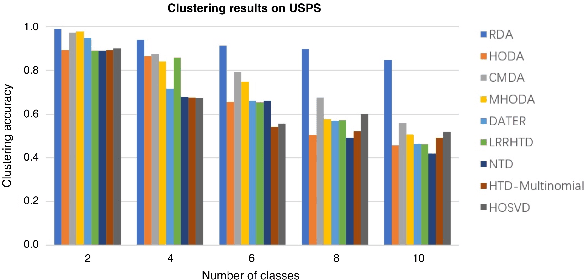
Discriminant analysis, as a widely used approach in machine learning to extract low-dimensional features from the high-dimensional data, applies the Fisher discriminant criterion to find the orthogonal discriminant projection subspace. But most of the Euclidean-based algorithms for discriminant analysis are easily convergent to a spurious local minima and hardly obtain an unique solution. To address such problem, in this study we propose a novel method named Riemannian-based Discriminant Analysis (RDA), which transforms the traditional Euclidean-based methods to the Riemannian manifold space. In RDA, the second-order geometry of trust-region methods is utilized to learn the discriminant bases. To validate the efficiency and effectiveness of RDA, we conduct a variety of experiments on image classification tasks. The numerical results suggest that RDA can extract statistically significant features and robustly outperform state-of-the-art algorithms in classification tasks.