 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplore Data Left Behind in Reinforcement Learning for Reasoning Language Models
Nov 06, 2025Reinforcement Learning with Verifiable Rewards (RLVR) has emerged as an effective approach for improving the reasoning abilities of large language models (LLMs). The Group Relative Policy Optimization (GRPO) family has demonstrated strong performance in training LLMs with RLVR. However, as models train longer and scale larger, more training prompts become residual prompts, those with zero variance rewards that provide no training signal. Consequently, fewer prompts contribute to training, reducing diversity and hindering effectiveness. To fully exploit these residual prompts, we propose the Explore Residual Prompts in Policy Optimization (ERPO) framework, which encourages exploration on residual prompts and reactivates their training signals. ERPO maintains a history tracker for each prompt and adaptively increases the sampling temperature for residual prompts that previously produced all correct responses. This encourages the model to generate more diverse reasoning traces, introducing incorrect responses that revive training signals. Empirical results on the Qwen2.5 series demonstrate that ERPO consistently surpasses strong baselines across multiple mathematical reasoning benchmarks.
RTBAgent: A LLM-based Agent System for Real-Time Bidding
Feb 02, 2025



Real-Time Bidding (RTB) enables advertisers to place competitive bids on impression opportunities instantaneously, striving for cost-effectiveness in a highly competitive landscape. Although RTB has widely benefited from the utilization of technologies such as deep learning and reinforcement learning, the reliability of related methods often encounters challenges due to the discrepancies between online and offline environments and the rapid fluctuations of online bidding. To handle these challenges, RTBAgent is proposed as the first RTB agent system based on large language models (LLMs), which synchronizes real competitive advertising bidding environments and obtains bidding prices through an integrated decision-making process. Specifically, obtaining reasoning ability through LLMs, RTBAgent is further tailored to be more professional for RTB via involved auxiliary modules, i.e., click-through rate estimation model, expert strategy knowledge, and daily reflection. In addition, we propose a two-step decision-making process and multi-memory retrieval mechanism, which enables RTBAgent to review historical decisions and transaction records and subsequently make decisions more adaptive to market changes in real-time bidding. Empirical testing with real advertising datasets demonstrates that RTBAgent significantly enhances profitability. The RTBAgent code will be publicly accessible at: https://github.com/CaiLeng/RTBAgent.
NP$^2$L: Negative Pseudo Partial Labels Extraction for Graph Neural Networks
Oct 02, 2023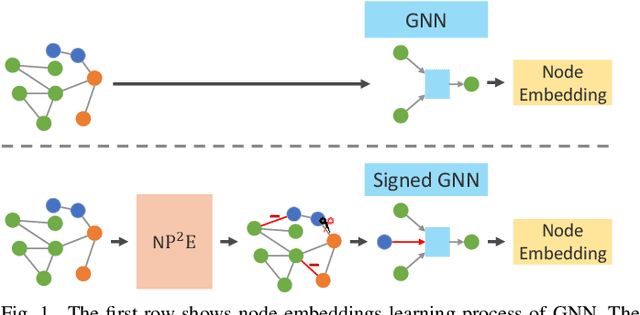
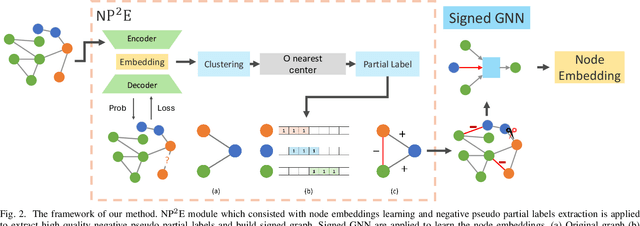
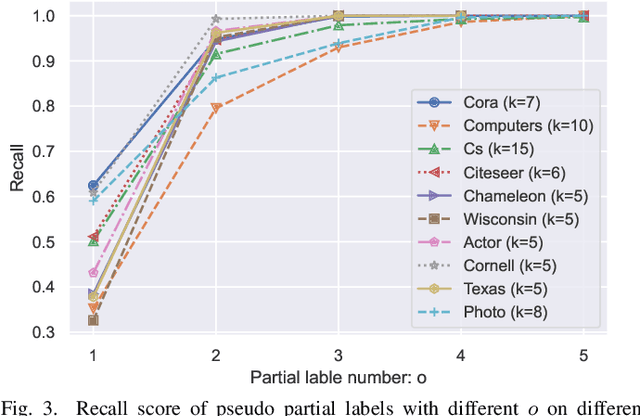
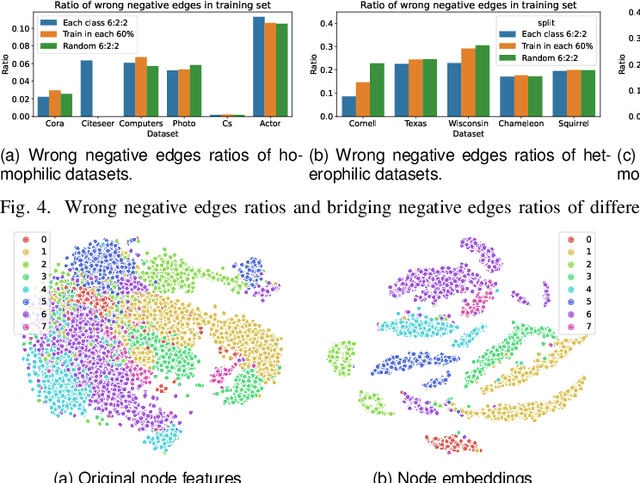
How to utilize the pseudo labels has always been a research hotspot in machine learning. However, most methods use pseudo labels as supervised training, and lack of valid assessing for their accuracy. Moreover, applications of pseudo labels in graph neural networks (GNNs) oversee the difference between graph learning and other machine learning tasks such as message passing mechanism. Aiming to address the first issue, we found through a large number of experiments that the pseudo labels are more accurate if they are selected by not overlapping partial labels and defined as negative node pairs relations. Therefore, considering the extraction based on pseudo and partial labels, negative edges are constructed between two nodes by the negative pseudo partial labels extraction (NP$^2$E) module. With that, a signed graph are built containing highly accurate pseudo labels information from the original graph, which effectively assists GNN in learning at the message-passing level, provide one solution to the second issue. Empirical results about link prediction and node classification tasks on several benchmark datasets demonstrate the effectiveness of our method. State-of-the-art performance is achieved on the both tasks.
PieTrack: An MOT solution based on synthetic data training and self-supervised domain adaptation
Jul 22, 2022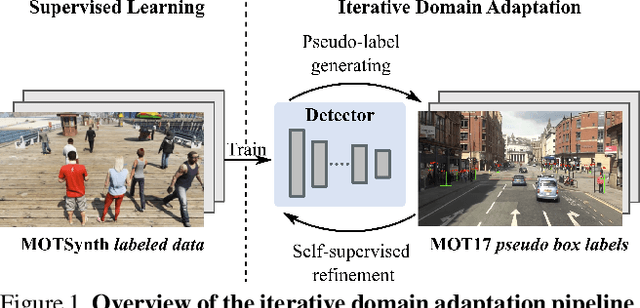
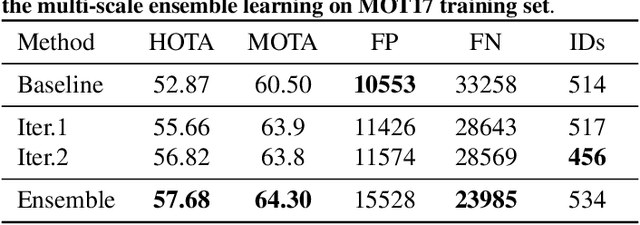
In order to cope with the increasing demand for labeling data and privacy issues with human detection, synthetic data has been used as a substitute and showing promising results in human detection and tracking tasks. We participate in the 7th Workshop on Benchmarking Multi-Target Tracking (BMTT), themed on "How Far Can Synthetic Data Take us"? Our solution, PieTrack, is developed based on synthetic data without using any pre-trained weights. We propose a self-supervised domain adaptation method that enables mitigating the domain shift issue between the synthetic (e.g., MOTSynth) and real data (e.g., MOT17) without involving extra human labels. By leveraging the proposed multi-scale ensemble inference, we achieved a final HOTA score of 58.7 on the MOT17 testing set, ranked third place in the challenge.
UNITE: Uncertainty-based Health Risk Prediction Leveraging Multi-sourced Data
Oct 22, 2020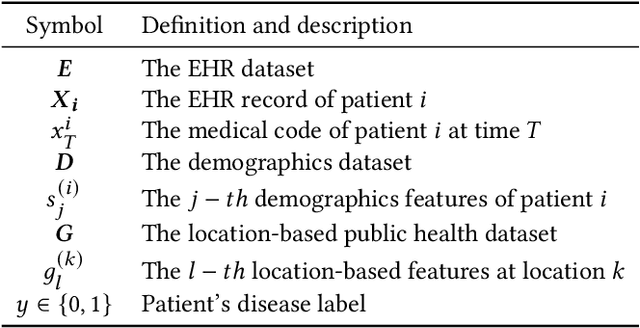
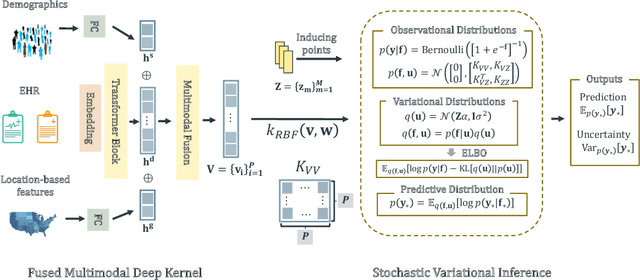
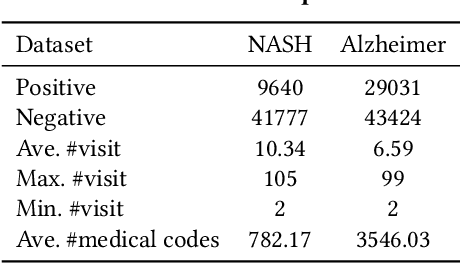
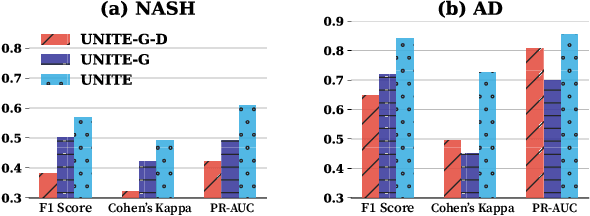
Successful health risk prediction demands accuracy and reliability of the model. Existing predictive models mainly depend on mining electronic health records (EHR) with advanced deep learning techniques to improve model accuracy. However, they all ignore the importance of publicly available online health data, especially socioeconomic status, environmental factors, and detailed demographic information for each location, which are all strong predictive signals and can definitely augment precision medicine. To achieve model reliability, the model needs to provide accurate prediction and uncertainty score of the prediction. However, existing uncertainty estimation approaches often failed in handling high-dimensional data, which are present in multi-sourced data. To fill the gap, we propose UNcertaInTy-based hEalth risk prediction (UNITE) model. Building upon an adaptive multimodal deep kernel and a stochastic variational inference module, UNITE provides accurate disease risk prediction and uncertainty estimation leveraging multi-sourced health data including EHR data, patient demographics, and public health data collected from the web. We evaluate UNITE on real-world disease risk prediction tasks: nonalcoholic fatty liver disease (NASH) and Alzheimer's disease (AD). UNITE achieves up to 0.841 in F1 score for AD detection, up to 0.609 in PR-AUC for NASH detection, and outperforms various state-of-the-art baselines by up to $19\%$ over the best baseline. We also show UNITE can model meaningful uncertainties and can provide evidence-based clinical support by clustering similar patients.
Longitudinal Deep Kernel Gaussian Process Regression
Jun 09, 2020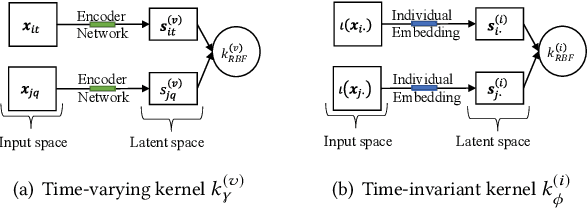
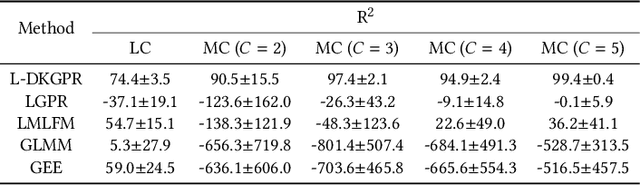
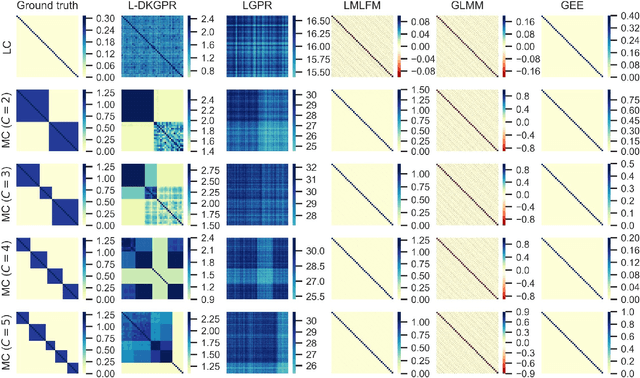

Gaussian processes offer an attractive framework for predictive modeling from longitudinal data, i.e., irregularly sampled, sparse observations from a set of individuals over time. However, such methods have two key shortcomings: (i) They rely on ad hoc heuristics or expensive trial and error to choose the effective kernels, and (ii) They fail to handle multilevel correlation structure in the data. We introduce Longitudinal deep kernel Gaussian process regression (L-DKGPR), which to the best of our knowledge, is the only method to overcome these limitations by fully automating the discovery of complex multilevel correlation structure from longitudinal data. Specifically, L-DKGPR eliminates the need for ad hoc heuristics or trial and error using a novel adaptation of deep kernel learning that combines the expressive power of deep neural networks with the flexibility of non-parametric kernel methods. L-DKGPR effectively learns the multilevel correlation with a novel addictive kernel that simultaneously accommodates both time-varying and the time-invariant effects. We derive an efficient algorithm to train L-DKGPR using latent space inducing points and variational inference. Results of extensive experiments on several benchmark data sets demonstrate that L-DKGPR significantly outperforms the state-of-the-art longitudinal data analysis (LDA) methods.
LMLFM: Longitudinal Multi-Level Factorization Machine
Nov 21, 2019



We consider the problem of learning predictive models from longitudinal data, consisting of irregularly repeated, sparse observations from a set of individuals over time. Such data often exhibit {\em longitudinal correlation} (LC) (correlations among observations for each individual over time), {\em cluster correlation} (CC) (correlations among individuals that have similar characteristics), or both. These correlations are often accounted for using {\em mixed effects models} that include {\em fixed effects} and {\em random effects}, where the fixed effects capture the regression parameters that are shared by all individuals, whereas random effects capture those parameters that vary across individuals. However, the current state-of-the-art methods are unable to select the most predictive fixed effects and random effects from a large number of variables, while accounting for complex correlation structure in the data and non-linear interactions among the variables. We propose Longitudinal Multi-Level Factorization Machine (LMLFM), to the best of our knowledge, the first model to address these challenges in learning predictive models from longitudinal data. We establish the convergence properties, and analyze the computational complexity, of LMLFM. We present results of experiments with both simulated and real-world longitudinal data which show that LMLFM outperforms the state-of-the-art methods in terms of predictive accuracy, variable selection ability, and scalability to data with large number of variables. The code and supplemental material is available at \url{https://github.com/junjieliang672/LMLFM}.
Top-N-Rank: A Scalable List-wise Ranking Method for Recommender Systems
Dec 19, 2018

We propose Top-N-Rank, a novel family of list-wise Learning-to-Rank models for reliably recommending the N top-ranked items. The proposed models optimize a variant of the widely used discounted cumulative gain (DCG) objective function which differs from DCG in two important aspects: (i) It limits the evaluation of DCG only on the top N items in the ranked lists, thereby eliminating the impact of low-ranked items on the learned ranking function; and (ii) it incorporates weights that allow the model to leverage multiple types of implicit feedback with differing levels of reliability or trustworthiness. Because the resulting objective function is non-smooth and hence challenging to optimize, we consider two smooth approximations of the objective function, using the traditional sigmoid function and the rectified linear unit (ReLU). We propose a family of learning-to-rank algorithms (Top-N-Rank) that work with any smooth objective function. Then, a more efficient variant, Top-N-Rank.ReLU, is introduced, which effectively exploits the properties of ReLU function to reduce the computational complexity of Top-N-Rank from quadratic to linear in the average number of items rated by users. The results of our experiments using two widely used benchmarks, namely, the MovieLens data set and the Amazon Video Games data set demonstrate that: (i) The `top-N truncation' of the objective function substantially improves the ranking quality of the top N recommendations; (ii) using the ReLU for smoothing the objective function yields significant improvement in both ranking quality as well as runtime as compared to using the sigmoid; and (iii) Top-N-Rank.ReLU substantially outperforms the well-performing list-wise ranking methods in terms of ranking quality.