 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Evaluation to Defense: Advancing Safety in Video Large Language Models
May 22, 2025



While the safety risks of image-based large language models have been extensively studied, their video-based counterparts (Video LLMs) remain critically under-examined. To systematically study this problem, we introduce \textbf{VideoSafetyBench (VSB-77k) - the first large-scale, culturally diverse benchmark for Video LLM safety}, which compromises 77,646 video-query pairs and spans 19 principal risk categories across 10 language communities. \textit{We reveal that integrating video modality degrades safety performance by an average of 42.3\%, exposing systemic risks in multimodal attack exploitation.} To address this vulnerability, we propose \textbf{VideoSafety-R1}, a dual-stage framework achieving unprecedented safety gains through two innovations: (1) Alarm Token-Guided Safety Fine-Tuning (AT-SFT) injects learnable alarm tokens into visual and textual sequences, enabling explicit harm perception across modalities via multitask objectives. (2) Then, Safety-Guided GRPO enhances defensive reasoning through dynamic policy optimization with rule-based rewards derived from dual-modality verification. These components synergize to shift safety alignment from passive harm recognition to active reasoning. The resulting framework achieves a 65.1\% improvement on VSB-Eval-HH, and improves by 59.1\%, 44.3\%, and 15.0\% on the image safety datasets MMBench, VLGuard, and FigStep, respectively. \textit{Our codes are available in the supplementary materials.} \textcolor{red}{Warning: This paper contains examples of harmful language and videos, and reader discretion is recommended.}
Hallucination Mitigation Prompts Long-term Video Understanding
Jun 17, 2024



Recently, multimodal large language models have made significant advancements in video understanding tasks. However, their ability to understand unprocessed long videos is very limited, primarily due to the difficulty in supporting the enormous memory overhead. Although existing methods achieve a balance between memory and information by aggregating frames, they inevitably introduce the severe hallucination issue. To address this issue, this paper constructs a comprehensive hallucination mitigation pipeline based on existing MLLMs. Specifically, we use the CLIP Score to guide the frame sampling process with questions, selecting key frames relevant to the question. Then, We inject question information into the queries of the image Q-former to obtain more important visual features. Finally, during the answer generation stage, we utilize chain-of-thought and in-context learning techniques to explicitly control the generation of answers. It is worth mentioning that for the breakpoint mode, we found that image understanding models achieved better results than video understanding models. Therefore, we aggregated the answers from both types of models using a comparison mechanism. Ultimately, We achieved 84.2\% and 62.9\% for the global and breakpoint modes respectively on the MovieChat dataset, surpassing the official baseline model by 29.1\% and 24.1\%. Moreover the proposed method won the third place in the CVPR LOVEU 2024 Long-Term Video Question Answering Challenge. The code is avaiable at https://github.com/lntzm/CVPR24Track-LongVideo
Labeled Data Generation with Inexact Supervision
Jun 08, 2021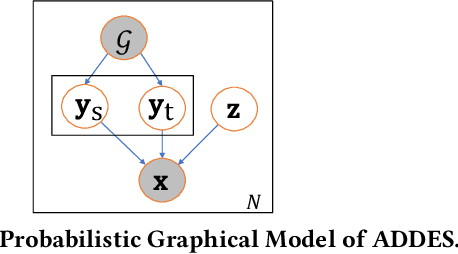
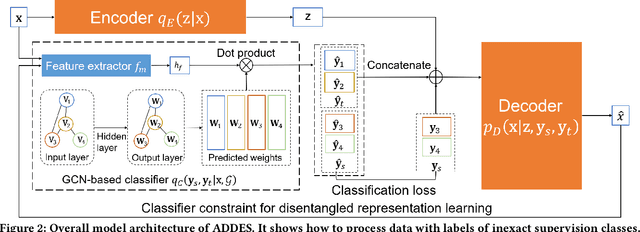
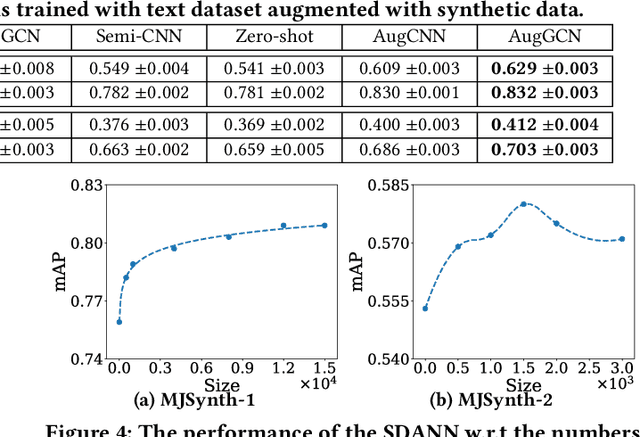
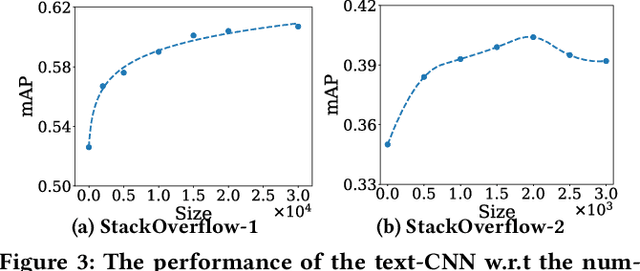
The recent advanced deep learning techniques have shown the promising results in various domains such as computer vision and natural language processing. The success of deep neural networks in supervised learning heavily relies on a large amount of labeled data. However, obtaining labeled data with target labels is often challenging due to various reasons such as cost of labeling and privacy issues, which challenges existing deep models. In spite of that, it is relatively easy to obtain data with \textit{inexact supervision}, i.e., having labels/tags related to the target task. For example, social media platforms are overwhelmed with billions of posts and images with self-customized tags, which are not the exact labels for target classification tasks but are usually related to the target labels. It is promising to leverage these tags (inexact supervision) and their relations with target classes to generate labeled data to facilitate the downstream classification tasks. However, the work on this is rather limited. Therefore, we study a novel problem of labeled data generation with inexact supervision. We propose a novel generative framework named as ADDES which can synthesize high-quality labeled data for target classification tasks by learning from data with inexact supervision and the relations between inexact supervision and target classes. Experimental results on image and text datasets demonstrate the effectiveness of the proposed ADDES for generating realistic labeled data from inexact supervision to facilitate the target classification task.
Explainable Multivariate Time Series Classification: A Deep Neural Network Which Learns To Attend To Important Variables As Well As Informative Time Intervals
Nov 23, 2020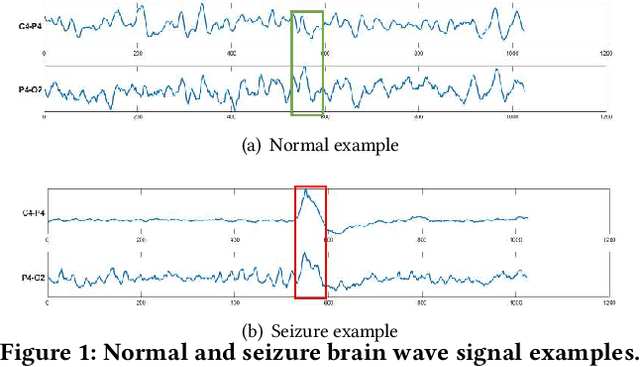

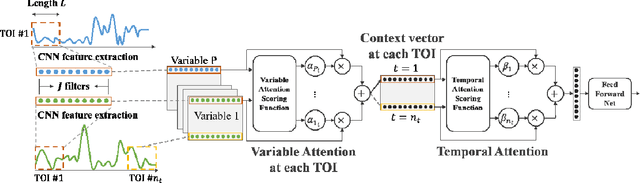

Time series data is prevalent in a wide variety of real-world applications and it calls for trustworthy and explainable models for people to understand and fully trust decisions made by AI solutions. We consider the problem of building explainable classifiers from multi-variate time series data. A key criterion to understand such predictive models involves elucidating and quantifying the contribution of time varying input variables to the classification. Hence, we introduce a novel, modular, convolution-based feature extraction and attention mechanism that simultaneously identifies the variables as well as time intervals which determine the classifier output. We present results of extensive experiments with several benchmark data sets that show that the proposed method outperforms the state-of-the-art baseline methods on multi-variate time series classification task. The results of our case studies demonstrate that the variables and time intervals identified by the proposed method make sense relative to available domain knowledge.
Graph Convolutional Networks against Degree-Related Biases
Jun 28, 2020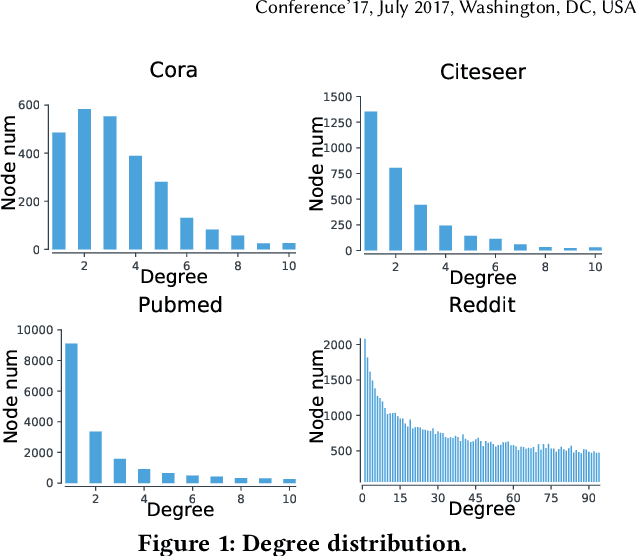
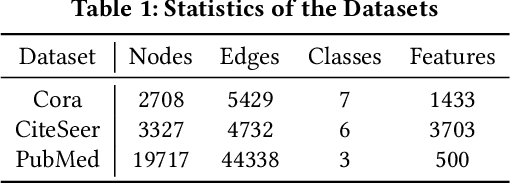
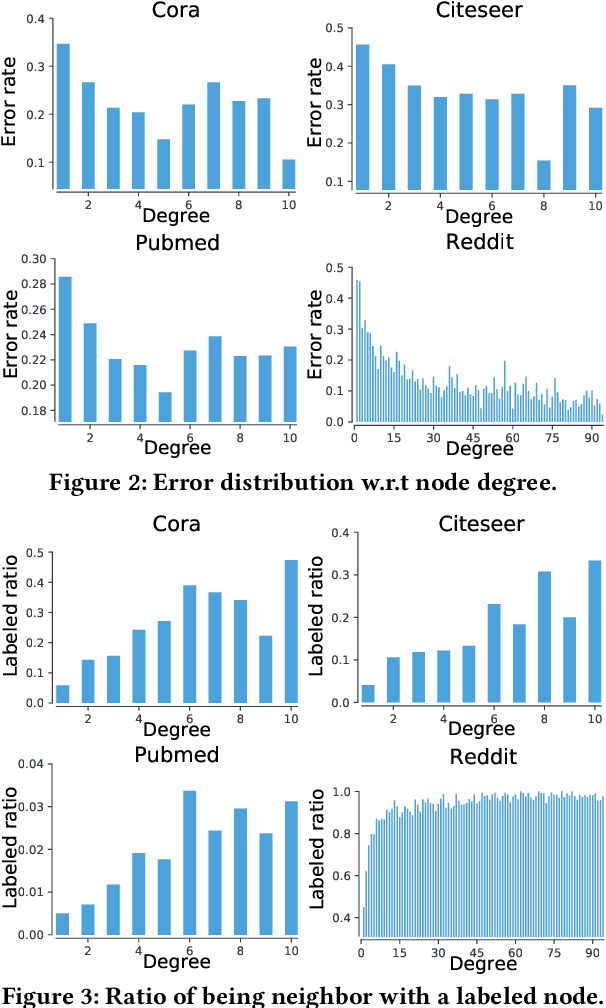
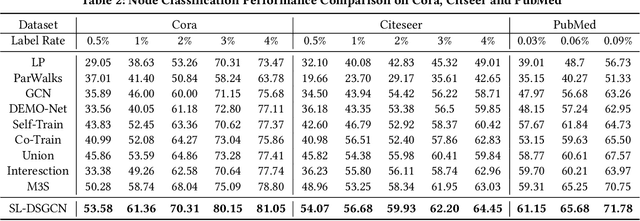
In recent years, Graph Convolutional Networks (GCNs) show competitive performance in different domains, such as social network analysis, recommendation, and smart city. However, training GCNs with insufficient supervision is very difficult. The performance of GCNs becomes unsatisfying with few labeled data. Although some pioneering work try to understand why GCNs work or fail, their analysis focus more on the entire model level. Profiling GCNs on different nodes is still underexplored. To address the limitations, we study GCNs with respect to the node degree distribution. We show that GCNs have a higher accuracy on nodes with larger degrees even if they are underrepresented in most graphs, with both empirical observation and theoretical proof. We then propose Self-Supervised-Learning Degree-Specific GCN (SL-DSGCN) which handles the degree-related biases of GCNs from model and data aspects. Firstly, we design a degree-specific GCN layer that models both discrepancies and similarities of nodes with different degrees, and reduces the inner model-aspect biases of GCNs caused by sharing the same parameters with all nodes. Secondly, we develop a self-supervised-learning algorithm that assigns pseudo labels with uncertainty scores on unlabeled nodes using a Bayesian neural network. Pseudo labels increase the chance of connecting to labeled neighbors for low-degree nodes, thus reducing the biases of GCNs from the data perspective. We further exploit uncertainty scores as dynamic weights on pseudo labels in the stochastic gradient descent for SL-DSGCN. We validate \ours on three benchmark datasets, and confirm SL-DSGCN not only outperforms state-of-the-art self-training/self-supervised-learning GCN methods, but also improves GCN accuracy dramatically for low-degree nodes.
An Ontology-Aware Framework for Audio Event Classification
Jan 27, 2020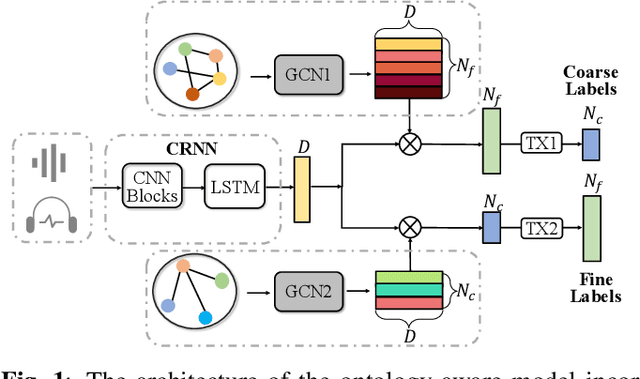
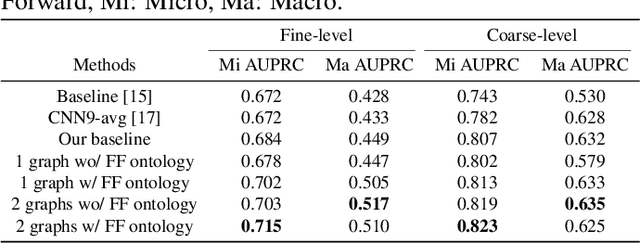
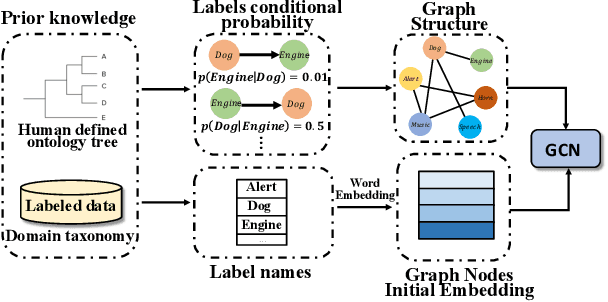
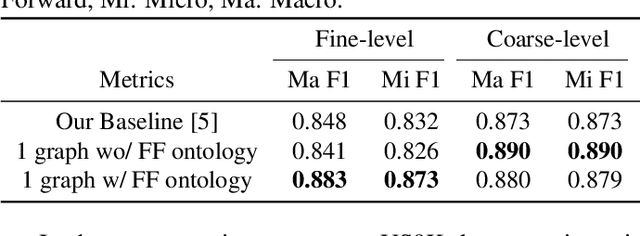
Recent advancements in audio event classification often ignore the structure and relation between the label classes available as prior information. This structure can be defined by ontology and augmented in the classifier as a form of domain knowledge. To capture such dependencies between the labels, we propose an ontology-aware neural network containing two components: feed-forward ontology layers and graph convolutional networks (GCN). The feed-forward ontology layers capture the intra-dependencies of labels between different levels of ontology. On the other hand, GCN mainly models inter-dependency structure of labels within an ontology level. The framework is evaluated on two benchmark datasets for single-label and multi-label audio event classification tasks. The results demonstrate the proposed solutions efficacy to capture and explore the ontology relations and improve the classification performance.
Ginger Cannot Cure Cancer: Battling Fake Health News with a Comprehensive Data Repository
Jan 27, 2020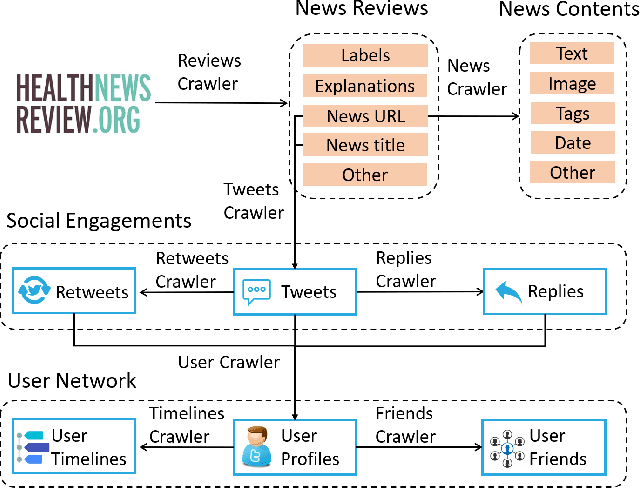
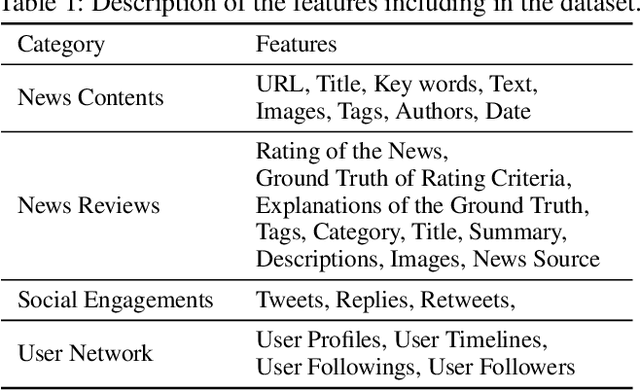

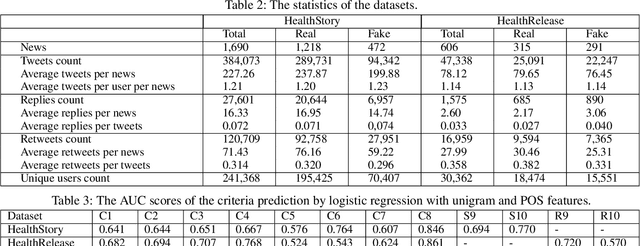
Nowadays, Internet is a primary source of attaining health information. Massive fake health news which is spreading over the Internet, has become a severe threat to public health. Numerous studies and research works have been done in fake news detection domain, however, few of them are designed to cope with the challenges in health news. For instance, the development of explainable is required for fake health news detection. To mitigate these problems, we construct a comprehensive repository, FakeHealth, which includes news contents with rich features, news reviews with detailed explanations, social engagements and a user-user social network. Moreover, exploratory analyses are conducted to understand the characteristics of the datasets, analyze useful patterns and validate the quality of the datasets for health fake news detection. We also discuss the novel and potential future research directions for the health fake news detection.
Joint Modeling of Local and Global Temporal Dynamics for Multivariate Time Series Forecasting with Missing Values
Nov 22, 2019
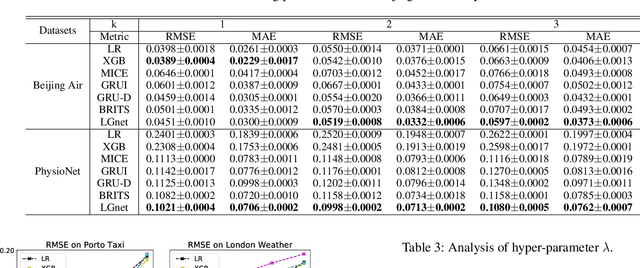
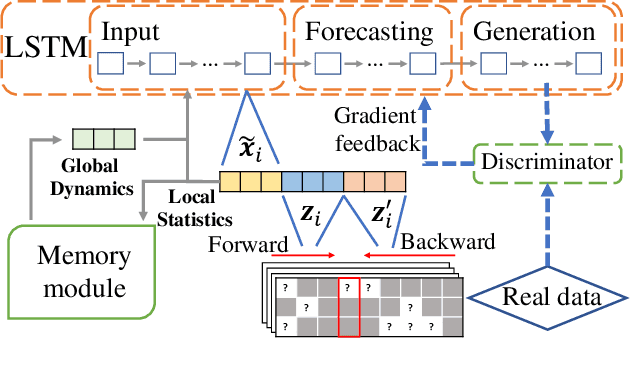
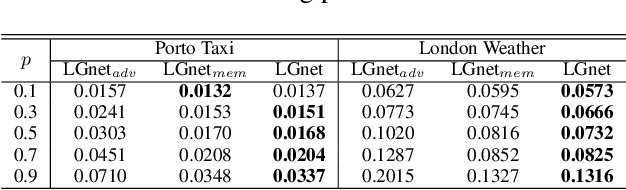
Multivariate time series (MTS) forecasting is widely used in various domains, such as meteorology and traffic. Due to limitations on data collection, transmission, and storage, real-world MTS data usually contains missing values, making it infeasible to apply existing MTS forecasting models such as linear regression and recurrent neural networks. Though many efforts have been devoted to this problem, most of them solely rely on local dependencies for imputing missing values, which ignores global temporal dynamics. Local dependencies/patterns would become less useful when the missing ratio is high, or the data have consecutive missing values; while exploring global patterns can alleviate such problems. Thus, jointly modeling local and global temporal dynamics is very promising for MTS forecasting with missing values. However, work in this direction is rather limited. Therefore, we study a novel problem of MTS forecasting with missing values by jointly exploring local and global temporal dynamics. We propose a new framework LGnet, which leverages memory network to explore global patterns given estimations from local perspectives. We further introduce adversarial training to enhance the modeling of global temporal distribution. Experimental results on real-world datasets show the effectiveness of LGnet for MTS forecasting with missing values and its robustness under various missing ratios.
LMLFM: Longitudinal Multi-Level Factorization Machine
Nov 21, 2019



We consider the problem of learning predictive models from longitudinal data, consisting of irregularly repeated, sparse observations from a set of individuals over time. Such data often exhibit {\em longitudinal correlation} (LC) (correlations among observations for each individual over time), {\em cluster correlation} (CC) (correlations among individuals that have similar characteristics), or both. These correlations are often accounted for using {\em mixed effects models} that include {\em fixed effects} and {\em random effects}, where the fixed effects capture the regression parameters that are shared by all individuals, whereas random effects capture those parameters that vary across individuals. However, the current state-of-the-art methods are unable to select the most predictive fixed effects and random effects from a large number of variables, while accounting for complex correlation structure in the data and non-linear interactions among the variables. We propose Longitudinal Multi-Level Factorization Machine (LMLFM), to the best of our knowledge, the first model to address these challenges in learning predictive models from longitudinal data. We establish the convergence properties, and analyze the computational complexity, of LMLFM. We present results of experiments with both simulated and real-world longitudinal data which show that LMLFM outperforms the state-of-the-art methods in terms of predictive accuracy, variable selection ability, and scalability to data with large number of variables. The code and supplemental material is available at \url{https://github.com/junjieliang672/LMLFM}.
Node Injection Attacks on Graphs via Reinforcement Learning
Sep 14, 2019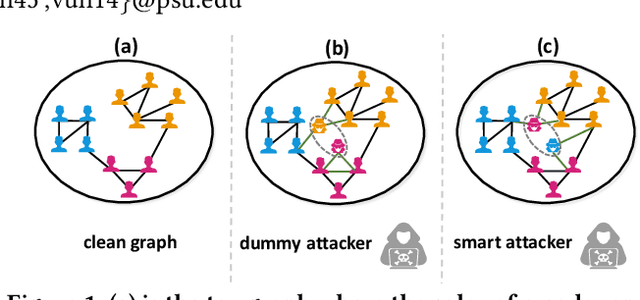
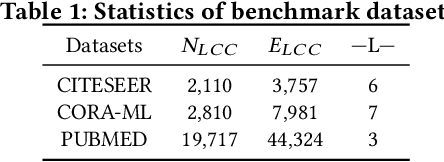
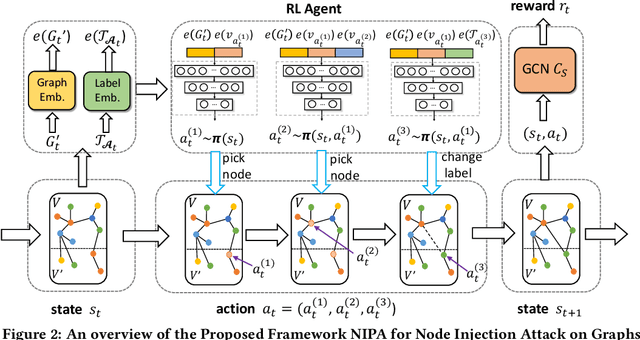
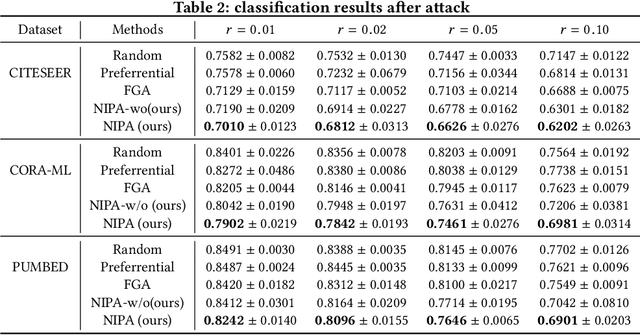
Real-world graph applications, such as advertisements and product recommendations make profits based on accurately classify the label of the nodes. However, in such scenarios, there are high incentives for the adversaries to attack such graph to reduce the node classification performance. Previous work on graph adversarial attacks focus on modifying existing graph structures, which is infeasible in most real-world applications. In contrast, it is more practical to inject adversarial nodes into existing graphs, which can also potentially reduce the performance of the classifier. In this paper, we study the novel node injection poisoning attacks problem which aims to poison the graph. We describe a reinforcement learning based method, namely NIPA, to sequentially modify the adversarial information of the injected nodes. We report the results of experiments using several benchmark data sets that show the superior performance of the proposed method NIPA, relative to the existing state-of-the-art methods.