 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable Multivariate Time Series Classification: A Deep Neural Network Which Learns To Attend To Important Variables As Well As Informative Time Intervals
Nov 23, 2020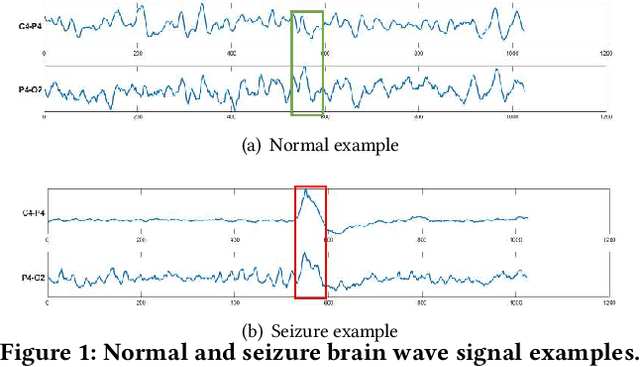

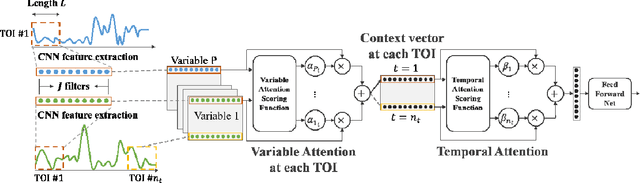

Time series data is prevalent in a wide variety of real-world applications and it calls for trustworthy and explainable models for people to understand and fully trust decisions made by AI solutions. We consider the problem of building explainable classifiers from multi-variate time series data. A key criterion to understand such predictive models involves elucidating and quantifying the contribution of time varying input variables to the classification. Hence, we introduce a novel, modular, convolution-based feature extraction and attention mechanism that simultaneously identifies the variables as well as time intervals which determine the classifier output. We present results of extensive experiments with several benchmark data sets that show that the proposed method outperforms the state-of-the-art baseline methods on multi-variate time series classification task. The results of our case studies demonstrate that the variables and time intervals identified by the proposed method make sense relative to available domain knowledge.
Node Injection Attacks on Graphs via Reinforcement Learning
Sep 14, 2019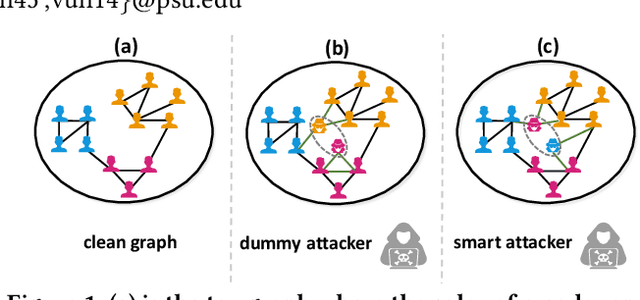
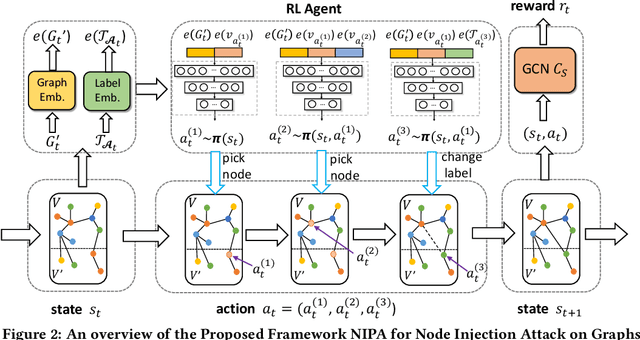
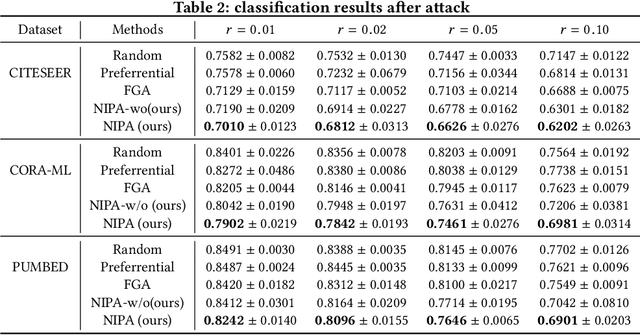
Real-world graph applications, such as advertisements and product recommendations make profits based on accurately classify the label of the nodes. However, in such scenarios, there are high incentives for the adversaries to attack such graph to reduce the node classification performance. Previous work on graph adversarial attacks focus on modifying existing graph structures, which is infeasible in most real-world applications. In contrast, it is more practical to inject adversarial nodes into existing graphs, which can also potentially reduce the performance of the classifier. In this paper, we study the novel node injection poisoning attacks problem which aims to poison the graph. We describe a reinforcement learning based method, namely NIPA, to sequentially modify the adversarial information of the injected nodes. We report the results of experiments using several benchmark data sets that show the superior performance of the proposed method NIPA, relative to the existing state-of-the-art methods.
MEGAN: A Generative Adversarial Network for Multi-View Network Embedding
Aug 20, 2019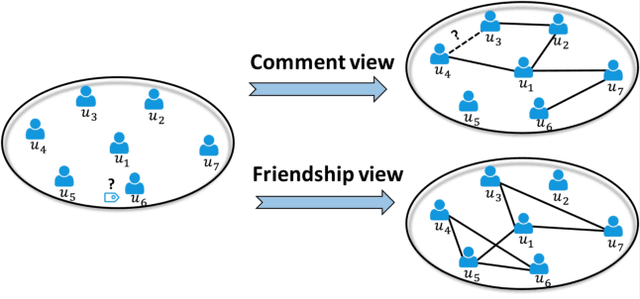
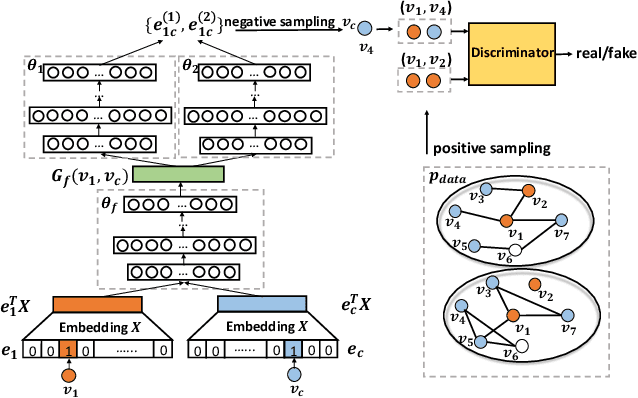
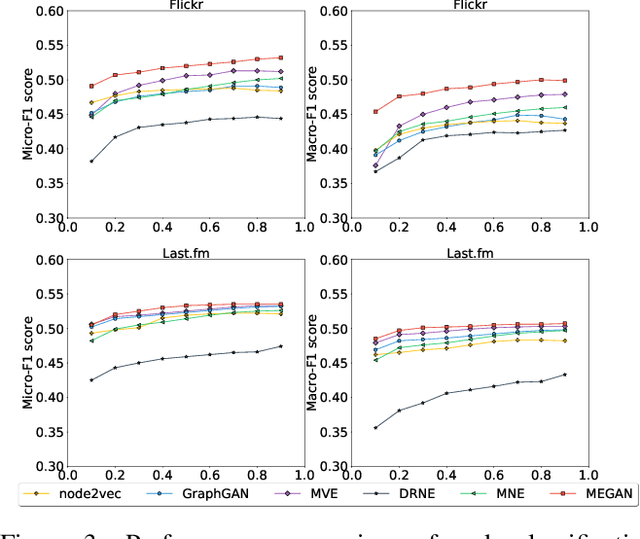
Data from many real-world applications can be naturally represented by multi-view networks where the different views encode different types of relationships (e.g., friendship, shared interests in music, etc.) between real-world individuals or entities. There is an urgent need for methods to obtain low-dimensional, information preserving and typically nonlinear embeddings of such multi-view networks. However, most of the work on multi-view learning focuses on data that lack a network structure, and most of the work on network embeddings has focused primarily on single-view networks. Against this background, we consider the multi-view network representation learning problem, i.e., the problem of constructing low-dimensional information preserving embeddings of multi-view networks. Specifically, we investigate a novel Generative Adversarial Network (GAN) framework for Multi-View Network Embedding, namely MEGAN, aimed at preserving the information from the individual network views, while accounting for connectivity across (and hence complementarity of and correlations between) different views. The results of our experiments on two real-world multi-view data sets show that the embeddings obtained using MEGAN outperform the state-of-the-art methods on node classification, link prediction and visualization tasks.
An Adaptive Subspace Self-Organizing Map (ASSOM) Imbalanced Learning and Its Applications in EEG
May 26, 2019
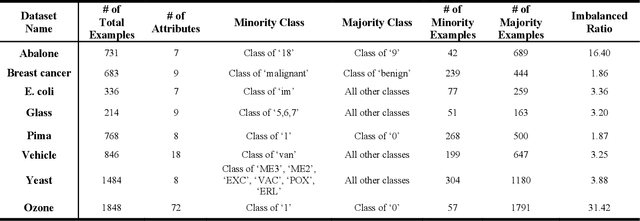
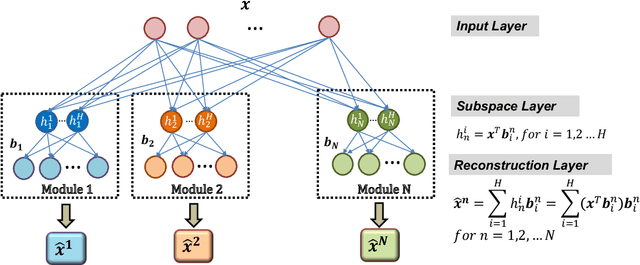

This paper presents a novel oversampling technique that addresses highly imbalanced benchmark and electroencephalogram (EEG) data distributions. Presently, conventional machine learning technologies do not adequately address imbalanced data with an anomalous class distribution and underrepresented data. To balance the class distributions, an adaptive subspace self-organizing map (ASSOM) that combines a local mapping scheme and the globally competitive rule is proposed to artificially generate synthetic samples that focus on minority class samples and its application in EEG. The ASSOM is configured with feature-invariant characteristics, including translation, scaling, and rotation, and it retains the independence of the basis vectors in each module. Specifically, basis vectors that are generated via each ASSOM module can avoid generating repeated representative features that only increase the computational load. Several benchmark experimental results demonstrate that the proposed ASSOM method incorporating a supervised learning approach could be superior to other existing oversampling techniques, and two EEG applications present the improvement of classification accuracy using the proposed ASSOM method.
Multi-View Network Embedding Via Graph Factorization Clustering and Co-Regularized Multi-View Agreement
Nov 08, 2018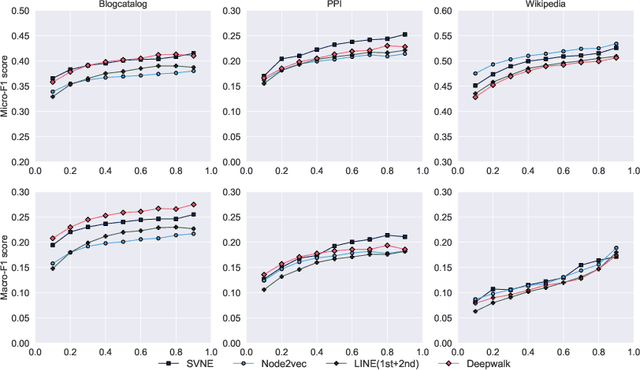
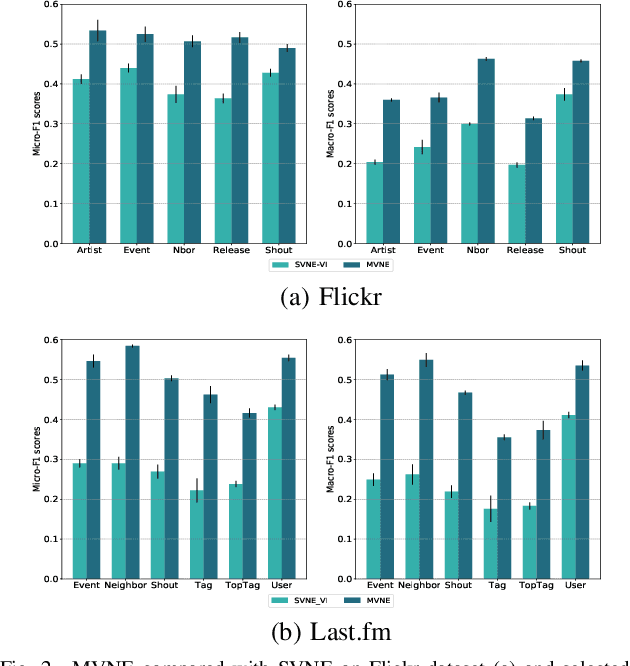
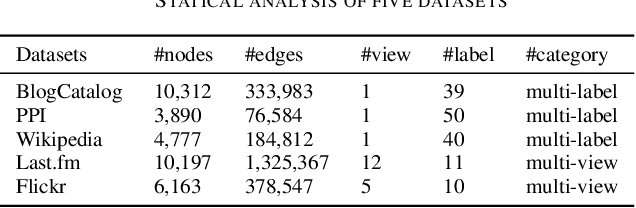
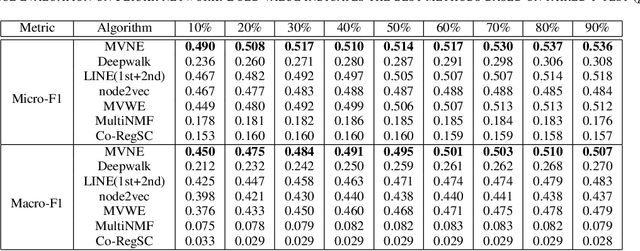
Real-world social networks and digital platforms are comprised of individuals (nodes) that are linked to other individuals or entities through multiple types of relationships (links). Sub-networks of such a network based on each type of link correspond to distinct views of the underlying network. In real-world applications, each node is typically linked to only a small subset of other nodes. Hence, practical approaches to problems such as node labeling have to cope with the resulting sparse networks. While low-dimensional network embeddings offer a promising approach to this problem, most of the current network embedding methods focus primarily on single view networks. We introduce a novel multi-view network embedding (MVNE) algorithm for constructing low-dimensional node embeddings from multi-view networks. MVNE adapts and extends an approach to single view network embedding (SVNE) using graph factorization clustering (GFC) to the multi-view setting using an objective function that maximizes the agreement between views based on both the local and global structure of the underlying multi-view graph. Our experiments with several benchmark real-world single view networks show that GFC-based SVNE yields network embeddings that are competitive with or superior to those produced by the state-of-the-art single view network embedding methods when the embeddings are used for labeling unlabeled nodes in the networks. Our experiments with several multi-view networks show that MVNE substantially outperforms the single view methods on integrated view and the state-of-the-art multi-view methods. We further show that even when the goal is to predict labels of nodes within a single target view, MVNE outperforms its single-view counterpart suggesting that the MVNE is able to extract the information that is useful for labeling nodes in the target view from the all of the views.
Compositional Stochastic Average Gradient for Machine Learning and Related Applications
Sep 07, 2018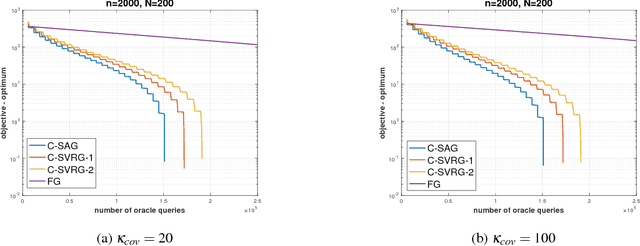
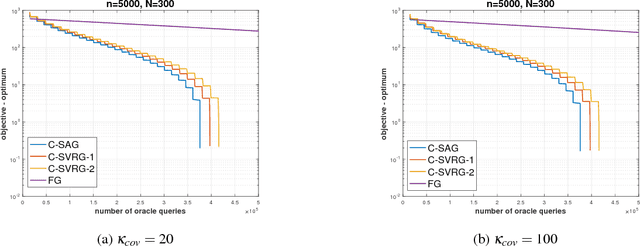
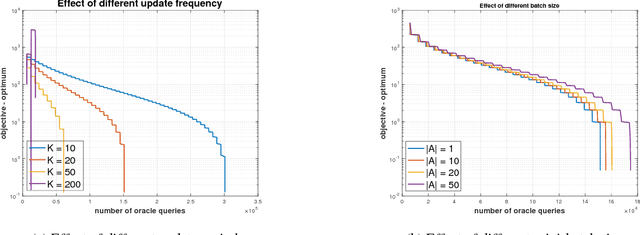
Many machine learning, statistical inference, and portfolio optimization problems require minimization of a composition of expected value functions (CEVF). Of particular interest is the finite-sum versions of such compositional optimization problems (FS-CEVF). Compositional stochastic variance reduced gradient (C-SVRG) methods that combine stochastic compositional gradient descent (SCGD) and stochastic variance reduced gradient descent (SVRG) methods are the state-of-the-art methods for FS-CEVF problems. We introduce compositional stochastic average gradient descent (C-SAG) a novel extension of the stochastic average gradient method (SAG) to minimize composition of finite-sum functions. C-SAG, like SAG, estimates gradient by incorporating memory of previous gradient information. We present theoretical analyses of C-SAG which show that C-SAG, like SAG, and C-SVRG, achieves a linear convergence rate when the objective function is strongly convex; However, C-CAG achieves lower oracle query complexity per iteration than C-SVRG. Finally, we present results of experiments showing that C-SAG converges substantially faster than full gradient (FG), as well as C-SVRG.