 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDFDRNN: A dual-feature based neural network for drug repositioning
Jul 16, 2024Drug repositioning is an economically efficient strategy used to discover new indications for existing drugs beyond their original approvals, expanding their applicability and usage to address challenges in disease treatment. In recent years, deep-learning techniques for drug repositioning have gained much attention. While most deep learning-based research methods focus on encoding drugs and diseases by extracting feature information from neighbors in the network, they often pay little attention to the potential relationships between the features of drugs and diseases, leading to imprecise encoding of drugs and diseases. To address this, we design a dual-feature drug repositioning neural network (DFDRNN) model to achieve precise encoding of drugs and diseases. DFDRNN uses two features to represent drugs and diseases: the similarity feature and the association feature. The model incorporates a self-attention mechanism to design two dual-feature extraction modules for achieving precisely encoding of drugs and diseases: the intra-domain dual-feature extraction (IntraDDFE) module and the inter-domain dual-feature extraction (InterDDFE) module. The IntraDDFE module extracts features from a single domain (drug or disease domain), while the InterDDFE module extracts features from the mixed domain (drug and disease domain). In particular, the feature is changed by InterDDFE, ensuring a precise encoding of drugs and diseases. Finally, a cross-dual-domain decoder is designed to predict drug-disease associations in both the drug and disease domains. Compared to six state-of-the-art methods, DFDRNN outperforms others on four benchmark datasets, with an average AUROC of 0.946 and an average AUPR of 0.597.
Convolutional Neural Networks Exploiting Attributes of Biological Neurons
Nov 14, 2023In this era of artificial intelligence, deep neural networks like Convolutional Neural Networks (CNNs) have emerged as front-runners, often surpassing human capabilities. These deep networks are often perceived as the panacea for all challenges. Unfortunately, a common downside of these networks is their ''black-box'' character, which does not necessarily mirror the operation of biological neural systems. Some even have millions/billions of learnable (tunable) parameters, and their training demands extensive data and time. Here, we integrate the principles of biological neurons in certain layer(s) of CNNs. Specifically, we explore the use of neuro-science-inspired computational models of the Lateral Geniculate Nucleus (LGN) and simple cells of the primary visual cortex. By leveraging such models, we aim to extract image features to use as input to CNNs, hoping to enhance training efficiency and achieve better accuracy. We aspire to enable shallow networks with a Push-Pull Combination of Receptive Fields (PP-CORF) model of simple cells as the foundation layer of CNNs to enhance their learning process and performance. To achieve this, we propose a two-tower CNN, one shallow tower and the other as ResNet 18. Rather than extracting the features blindly, it seeks to mimic how the brain perceives and extracts features. The proposed system exhibits a noticeable improvement in the performance (on an average of $5\%-10\%$) on CIFAR-10, CIFAR-100, and ImageNet-100 datasets compared to ResNet-18. We also check the efficiency of only the Push-Pull tower of the network.
Group-Feature (Sensor) Selection With Controlled Redundancy Using Neural Networks
Oct 31, 2023In this paper, we present a novel embedded feature selection method based on a Multi-layer Perceptron (MLP) network and generalize it for group-feature or sensor selection problems, which can control the level of redundancy among the selected features or groups. Additionally, we have generalized the group lasso penalty for feature selection to encompass a mechanism for selecting valuable group features while simultaneously maintaining a control over redundancy. We establish the monotonicity and convergence of the proposed algorithm, with a smoothed version of the penalty terms, under suitable assumptions. Experimental results on several benchmark datasets demonstrate the promising performance of the proposed methodology for both feature selection and group feature selection over some state-of-the-art methods.
Feature selection simultaneously preserving both class and cluster structures
Jul 08, 2023When a data set has significant differences in its class and cluster structure, selecting features aiming only at the discrimination of classes would lead to poor clustering performance, and similarly, feature selection aiming only at preserving cluster structures would lead to poor classification performance. To the best of our knowledge, a feature selection method that simultaneously considers class discrimination and cluster structure preservation is not available in the literature. In this paper, we have tried to bridge this gap by proposing a neural network-based feature selection method that focuses both on class discrimination and structure preservation in an integrated manner. In addition to assessing typical classification problems, we have investigated its effectiveness on band selection in hyperspectral images. Based on the results of the experiments, we may claim that the proposed feature/band selection can select a subset of features that is good for both classification and clustering.
Understanding the classes better with class-specific and rule-specific feature selection, and redundancy control in a fuzzy rule based framework
Aug 02, 2022

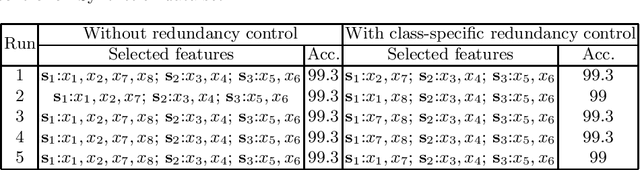

Recently, several studies have claimed that using class-specific feature subsets provides certain advantages over using a single feature subset for representing the data for a classification problem. Unlike traditional feature selection methods, the class-specific feature selection methods select an optimal feature subset for each class. Typically class-specific feature selection (CSFS) methods use one-versus-all split of the data set that leads to issues such as class imbalance, decision aggregation, and high computational overhead. We propose a class-specific feature selection method embedded in a fuzzy rule-based classifier, which is free from the drawbacks associated with most existing class-specific methods. Additionally, our method can be adapted to control the level of redundancy in the class-specific feature subsets by adding a suitable regularizer to the learning objective. Our method results in class-specific rules involving class-specific subsets. We also propose an extension where different rules of a particular class are defined by different feature subsets to model different substructures within the class. The effectiveness of the proposed method has been validated through experiments on three synthetic data sets.
An Adaptive Neuro-Fuzzy System with Integrated Feature Selection and Rule Extraction for High-Dimensional Classification Problems
Jan 10, 2022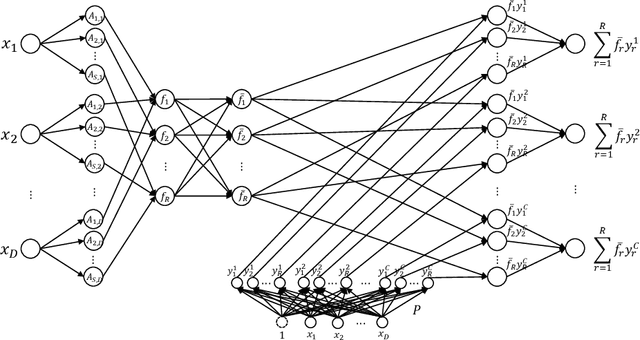
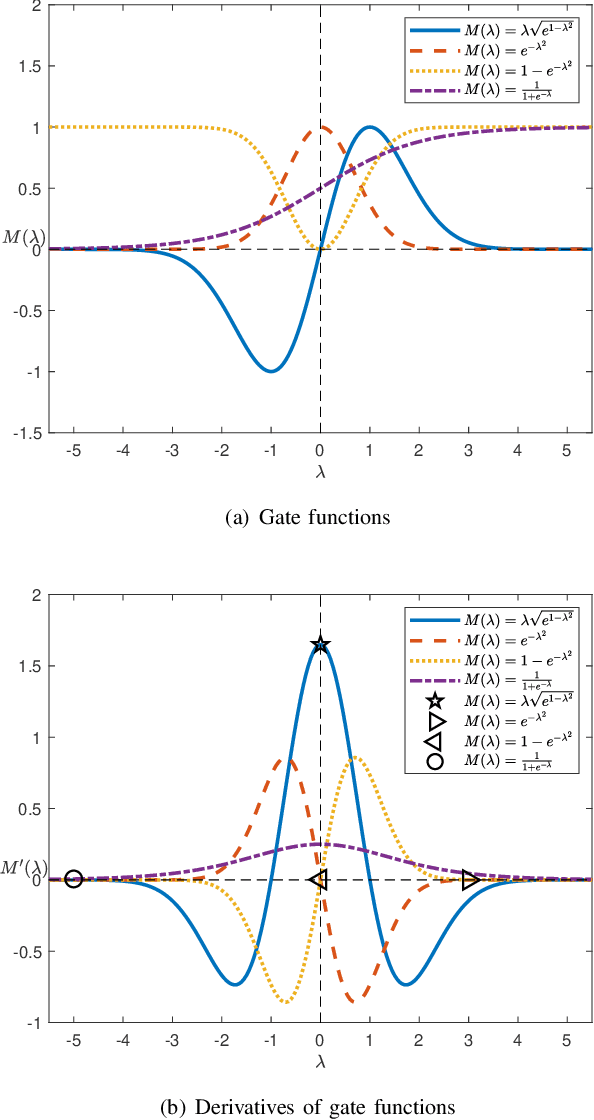


A major limitation of fuzzy or neuro-fuzzy systems is their failure to deal with high-dimensional datasets. This happens primarily due to the use of T-norm, particularly, product or minimum (or a softer version of it). Thus, there are hardly any work dealing with datasets with dimensions more than hundred or so. Here, we propose a neuro-fuzzy framework that can handle datasets with dimensions even more than 7000! In this context, we propose an adaptive softmin (Ada-softmin) which effectively overcomes the drawbacks of ``numeric underflow" and ``fake minimum" that arise for existing fuzzy systems while dealing with high-dimensional problems. We call it an Adaptive Takagi-Sugeno-Kang (AdaTSK) fuzzy system. We then equip the AdaTSK system to perform feature selection and rule extraction in an integrated manner. In this context, a novel gate function is introduced and embedded only in the consequent parts, which can determine the useful features and rules, in two successive phases of learning. Unlike conventional fuzzy rule bases, we design an enhanced fuzzy rule base (En-FRB), which maintains adequate rules but does not grow the number of rules exponentially with dimension that typically happens for fuzzy neural networks. The integrated Feature Selection and Rule Extraction AdaTSK (FSRE-AdaTSK) system consists of three sequential phases: (i) feature selection, (ii) rule extraction, and (iii) fine tuning. The effectiveness of the FSRE-AdaTSK is demonstrated on 19 datasets of which five are in more than 2000 dimension including two with dimension greater than 7000. This may be the first time fuzzy systems are realized for classification involving more than 7000 input features.
Nonlinear Dimensionality Reduction for Data Visualization: An Unsupervised Fuzzy Rule-based Approach
Apr 08, 2020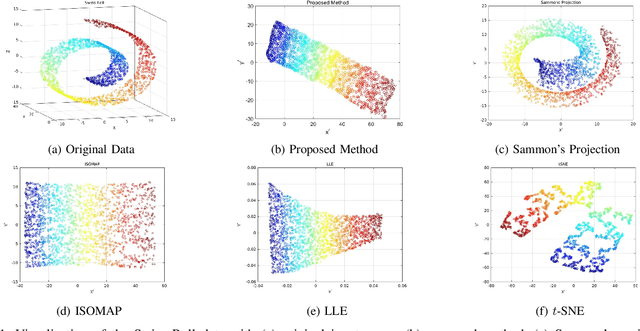
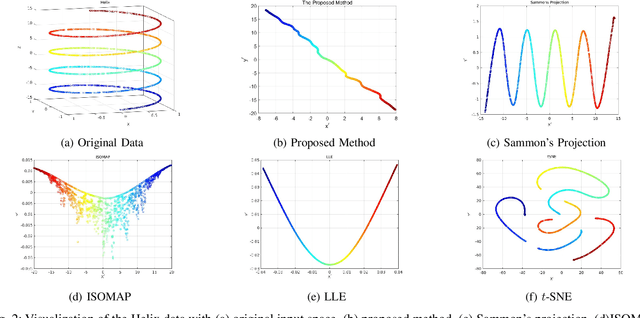
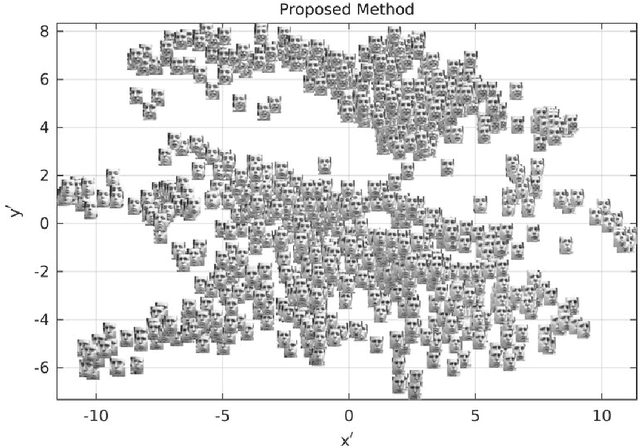
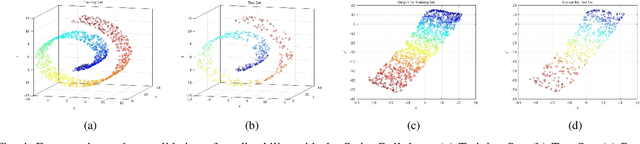
Here, we propose an unsupervised fuzzy rule-based dimensionality reduction method primarily for data visualization. It considers the following important issues relevant to dimensionality reduction-based data visualization: (i) preservation of neighborhood relationships, (ii) handling data on a non-linear manifold, (iii) the capability of predicting projections for new test data points, (iv) interpretability of the system, and (v) the ability to reject test points if required. For this, we use a first-order Takagi-Sugeno type model. We generate rule antecedents using clusters in the input data. In this context, we also propose a new variant of the Geodesic c-means clustering algorithm. We estimate the rule parameters by minimizing an error function that preserves the inter-point geodesic distances (distances over the manifold) as Euclidean distances on the projected space. We apply the proposed method on three synthetic and three real-world data sets and visually compare the results with four other standard data visualization methods. The obtained results show that the proposed method behaves desirably and performs better than or comparable to the methods compared with. The proposed method is found to be robust to the initial conditions. The predictability of the proposed method for test points is validated by experiments. We also assess the ability of our method to reject output points when it should. Then, we extend this concept to provide a general framework for learning an unsupervised fuzzy model for data projection with different objective functions. To the best of our knowledge, this is the first attempt to manifold learning using unsupervised fuzzy modeling.
An Adaptive Subspace Self-Organizing Map (ASSOM) Imbalanced Learning and Its Applications in EEG
May 26, 2019
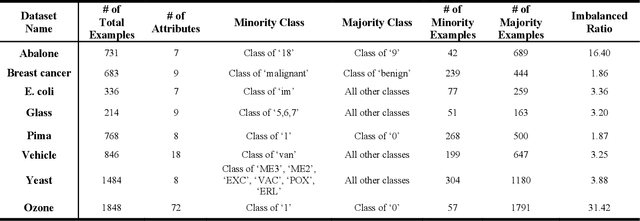
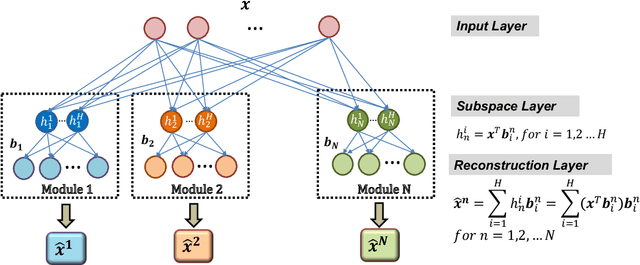

This paper presents a novel oversampling technique that addresses highly imbalanced benchmark and electroencephalogram (EEG) data distributions. Presently, conventional machine learning technologies do not adequately address imbalanced data with an anomalous class distribution and underrepresented data. To balance the class distributions, an adaptive subspace self-organizing map (ASSOM) that combines a local mapping scheme and the globally competitive rule is proposed to artificially generate synthetic samples that focus on minority class samples and its application in EEG. The ASSOM is configured with feature-invariant characteristics, including translation, scaling, and rotation, and it retains the independence of the basis vectors in each module. Specifically, basis vectors that are generated via each ASSOM module can avoid generating repeated representative features that only increase the computational load. Several benchmark experimental results demonstrate that the proposed ASSOM method incorporating a supervised learning approach could be superior to other existing oversampling techniques, and two EEG applications present the improvement of classification accuracy using the proposed ASSOM method.
Land cover classification using fuzzy rules and aggregation of contextual information through evidence theory
Nov 23, 2009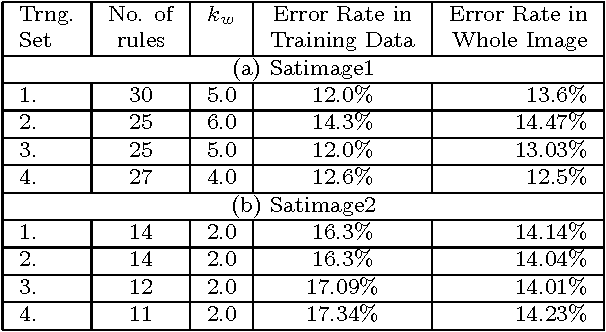
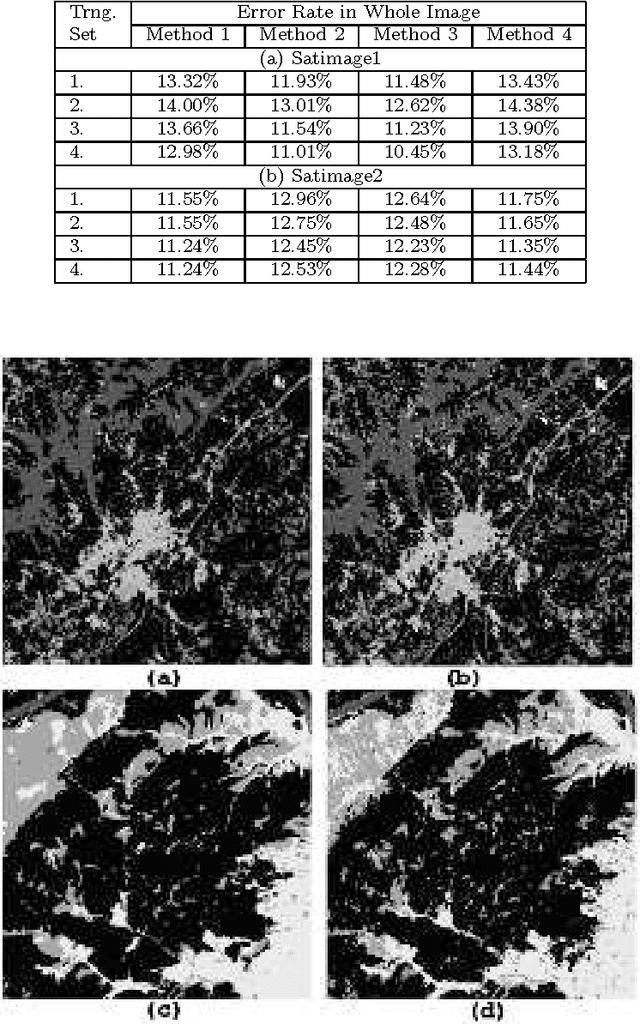
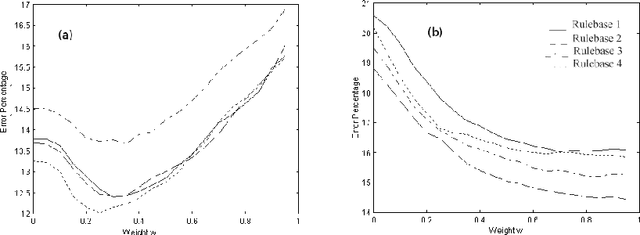
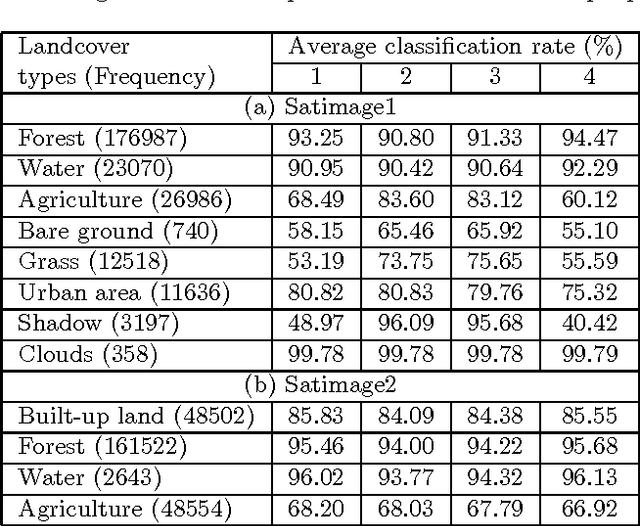
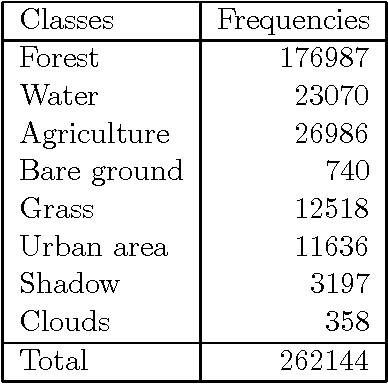
Land cover classification using multispectral satellite image is a very challenging task with numerous practical applications. We propose a multi-stage classifier that involves fuzzy rule extraction from the training data and then generation of a possibilistic label vector for each pixel using the fuzzy rule base. To exploit the spatial correlation of land cover types we propose four different information aggregation methods which use the possibilistic class label of a pixel and those of its eight spatial neighbors for making the final classification decision. Three of the aggregation methods use Dempster-Shafer theory of evidence while the remaining one is modeled after the fuzzy k-NN rule. The proposed methods are tested with two benchmark seven channel satellite images and the results are found to be quite satisfactory. They are also compared with a Markov random field (MRF) model-based contextual classification method and found to perform consistently better.
* 14 pages, 2 figures
Designing fuzzy rule based classifier using self-organizing feature map for analysis of multispectral satellite images
Nov 23, 2009
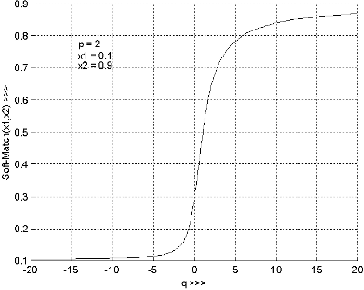

We propose a novel scheme for designing fuzzy rule based classifier. An SOFM based method is used for generating a set of prototypes which is used to generate a set of fuzzy rules. Each rule represents a region in the feature space that we call the context of the rule. The rules are tuned with respect to their context. We justified that the reasoning scheme may be different in different context leading to context sensitive inferencing. To realize context sensitive inferencing we used a softmin operator with a tunable parameter. The proposed scheme is tested on several multispectral satellite image data sets and the performance is found to be much better than the results reported in the literature.
* 23 pages, 7 figures