 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgexai_evals : A Framework for Evaluating Post-Hoc Local Explanation Methods
Feb 05, 2025



The growing complexity of machine learning and deep learning models has led to an increased reliance on opaque "black box" systems, making it difficult to understand the rationale behind predictions. This lack of transparency is particularly challenging in high-stakes applications where interpretability is as important as accuracy. Post-hoc explanation methods are commonly used to interpret these models, but they are seldom rigorously evaluated, raising concerns about their reliability. The Python package xai_evals addresses this by providing a comprehensive framework for generating, benchmarking, and evaluating explanation methods across both tabular and image data modalities. It integrates popular techniques like SHAP, LIME, Grad-CAM, Integrated Gradients (IG), and Backtrace, while supporting evaluation metrics such as faithfulness, sensitivity, and robustness. xai_evals enhances the interpretability of machine learning models, fostering transparency and trust in AI systems. The library is open-sourced at https://pypi.org/project/xai-evals/ .
DLBacktrace: A Model Agnostic Explainability for any Deep Learning Models
Nov 19, 2024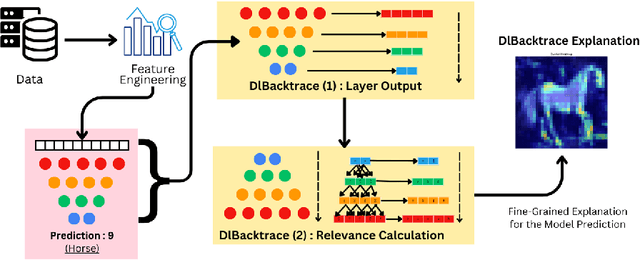
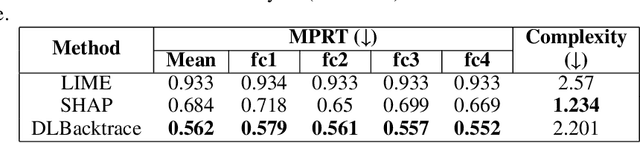
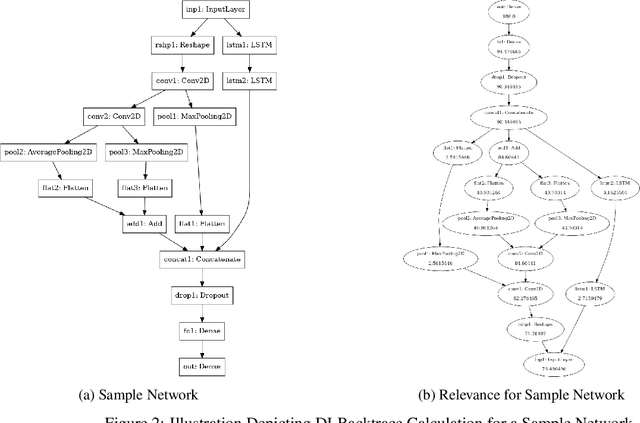
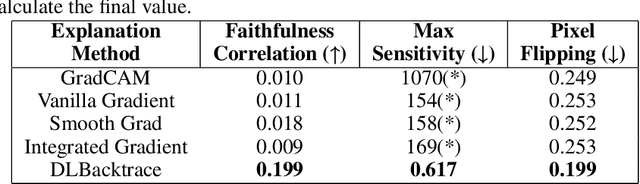
The rapid advancement of artificial intelligence has led to increasingly sophisticated deep learning models, which frequently operate as opaque 'black boxes' with limited transparency in their decision-making processes. This lack of interpretability presents considerable challenges, especially in high-stakes applications where understanding the rationale behind a model's outputs is as essential as the outputs themselves. This study addresses the pressing need for interpretability in AI systems, emphasizing its role in fostering trust, ensuring accountability, and promoting responsible deployment in mission-critical fields. To address the interpretability challenge in deep learning, we introduce DLBacktrace, an innovative technique developed by the AryaXAI team to illuminate model decisions across a wide array of domains, including simple Multi Layer Perceptron (MLPs), Convolutional Neural Networks (CNNs), Large Language Models (LLMs), Computer Vision Models, and more. We provide a comprehensive overview of the DLBacktrace algorithm and present benchmarking results, comparing its performance against established interpretability methods, such as SHAP, LIME, GradCAM, Integrated Gradients, SmoothGrad, and Attention Rollout, using diverse task-based metrics. The proposed DLBacktrace technique is compatible with various model architectures built in PyTorch and TensorFlow, supporting models like Llama 3.2, other NLP architectures such as BERT and LSTMs, computer vision models like ResNet and U-Net, as well as custom deep neural network (DNN) models for tabular data. This flexibility underscores DLBacktrace's adaptability and effectiveness in enhancing model transparency across a broad spectrum of applications. The library is open-sourced and available at https://github.com/AryaXAI/DLBacktrace .
HCDIR: End-to-end Hate Context Detection, and Intensity Reduction model for online comments
Dec 20, 2023



Warning: This paper contains examples of the language that some people may find offensive. Detecting and reducing hateful, abusive, offensive comments is a critical and challenging task on social media. Moreover, few studies aim to mitigate the intensity of hate speech. While studies have shown that context-level semantics are crucial for detecting hateful comments, most of this research focuses on English due to the ample datasets available. In contrast, low-resource languages, like Indian languages, remain under-researched because of limited datasets. Contrary to hate speech detection, hate intensity reduction remains unexplored in high-resource and low-resource languages. In this paper, we propose a novel end-to-end model, HCDIR, for Hate Context Detection, and Hate Intensity Reduction in social media posts. First, we fine-tuned several pre-trained language models to detect hateful comments to ascertain the best-performing hateful comments detection model. Then, we identified the contextual hateful words. Identification of such hateful words is justified through the state-of-the-art explainable learning model, i.e., Integrated Gradient (IG). Lastly, the Masked Language Modeling (MLM) model has been employed to capture domain-specific nuances to reduce hate intensity. We masked the 50\% hateful words of the comments identified as hateful and predicted the alternative words for these masked terms to generate convincing sentences. An optimal replacement for the original hate comments from the feasible sentences is preferred. Extensive experiments have been conducted on several recent datasets using automatic metric-based evaluation (BERTScore) and thorough human evaluation. To enhance the faithfulness in human evaluation, we arranged a group of three human annotators with varied expertise.
Convolutional Neural Networks Exploiting Attributes of Biological Neurons
Nov 14, 2023In this era of artificial intelligence, deep neural networks like Convolutional Neural Networks (CNNs) have emerged as front-runners, often surpassing human capabilities. These deep networks are often perceived as the panacea for all challenges. Unfortunately, a common downside of these networks is their ''black-box'' character, which does not necessarily mirror the operation of biological neural systems. Some even have millions/billions of learnable (tunable) parameters, and their training demands extensive data and time. Here, we integrate the principles of biological neurons in certain layer(s) of CNNs. Specifically, we explore the use of neuro-science-inspired computational models of the Lateral Geniculate Nucleus (LGN) and simple cells of the primary visual cortex. By leveraging such models, we aim to extract image features to use as input to CNNs, hoping to enhance training efficiency and achieve better accuracy. We aspire to enable shallow networks with a Push-Pull Combination of Receptive Fields (PP-CORF) model of simple cells as the foundation layer of CNNs to enhance their learning process and performance. To achieve this, we propose a two-tower CNN, one shallow tower and the other as ResNet 18. Rather than extracting the features blindly, it seeks to mimic how the brain perceives and extracts features. The proposed system exhibits a noticeable improvement in the performance (on an average of $5\%-10\%$) on CIFAR-10, CIFAR-100, and ImageNet-100 datasets compared to ResNet-18. We also check the efficiency of only the Push-Pull tower of the network.