 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$C$-$ΔΘ$: Circuit-Restricted Weight Arithmetic for Selective Refusal
Feb 04, 2026Modern deployments require LLMs to enforce safety policies at scale, yet many controls rely on inference-time interventions that add recurring compute cost and serving complexity. Activation steering is widely used, but it requires runtime hooks and scales cost with the number of generations; conditional variants improve selectivity by gating when steering is applied but still retain an inference-time control path. We ask whether selective refusal can be moved entirely offline: can a mechanistic understanding of category-specific refusal be distilled into a circuit-restricted weight update that deploys as a standard checkpoint? We propose C-Δθ: Circuit Restricted Weight Arithmetic, which (i) localizes refusal-causal computation as a sparse circuit using EAP-IG and (ii) computes a constrained weight update ΔθC supported only on that circuit (typically <5% of parameters). Applying ΔθC yields a drop-in edited checkpoint with no inference-time hooks, shifting cost from per-request intervention to a one-time offline update. We evaluate category-targeted selectivity and capability retention on refusal and utility benchmarks.
Beyond KL Divergence: Policy Optimization with Flexible Bregman Divergences for LLM Reasoning
Feb 04, 2026Policy optimization methods like Group Relative Policy Optimization (GRPO) and its variants have achieved strong results on mathematical reasoning and code generation tasks. Despite extensive exploration of reward processing strategies and training dynamics, all existing group-based methods exclusively use KL divergence for policy regularization, leaving the choice of divergence function unexplored. We introduce Group-Based Mirror Policy Optimization (GBMPO), a framework that extends group-based policy optimization to flexible Bregman divergences, including hand-designed alternatives (L2 in probability space) and learned neural mirror maps. On GSM8K mathematical reasoning, hand-designed ProbL2-GRPO achieves 86.7% accuracy, improving +5.5 points over the Dr. GRPO baseline. On MBPP code generation, neural mirror maps reach 60.1-60.8% pass@1, with random initialization already capturing most of the benefit. While evolutionary strategies meta-learning provides marginal accuracy improvements, its primary value lies in variance reduction ($\pm$0.2 versus $\pm$0.6) and efficiency gains (15% shorter responses on MBPP), suggesting that random initialization of neural mirror maps is sufficient for most practical applications. These results establish divergence choice as a critical, previously unexplored design dimension in group-based policy optimization for LLM reasoning.
Exploring Fine-Tuning for Tabular Foundation Models
Jan 14, 2026Tabular Foundation Models (TFMs) have recently shown strong in-context learning capabilities on structured data, achieving zero-shot performance comparable to traditional machine learning methods. We find that zero-shot TFMs already achieve strong performance, while the benefits of fine-tuning are highly model and data-dependent. Meta-learning and PEFT provide moderate gains under specific conditions, whereas full supervised fine-tuning (SFT) often reduces accuracy or calibration quality. This work presents the first comprehensive study of fine-tuning in TFMs across benchmarks including TALENT, OpenML-CC18, and TabZilla. We compare Zero-Shot, Meta-Learning, Supervised (SFT), and parameter-efficient (PEFT) approaches, analyzing how dataset factors such as imbalance, size, and dimensionality affect outcomes. Our findings cover performance, calibration, and fairness, offering practical guidelines on when fine-tuning is most beneficial and its limitations.
Interpretability as Alignment: Making Internal Understanding a Design Principle
Sep 10, 2025
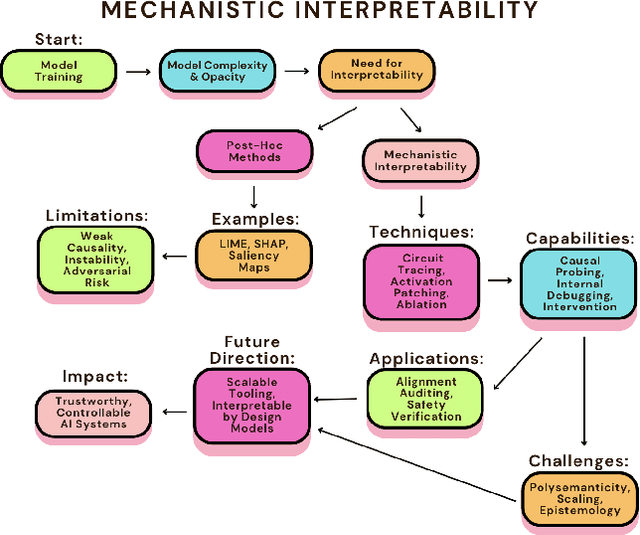


Large neural models are increasingly deployed in high-stakes settings, raising concerns about whether their behavior reliably aligns with human values. Interpretability provides a route to internal transparency by revealing the computations that drive outputs. We argue that interpretability especially mechanistic approaches should be treated as a design principle for alignment, not an auxiliary diagnostic tool. Post-hoc methods such as LIME or SHAP offer intuitive but correlational explanations, while mechanistic techniques like circuit tracing or activation patching yield causal insight into internal failures, including deceptive or misaligned reasoning that behavioral methods like RLHF, red teaming, or Constitutional AI may overlook. Despite these advantages, interpretability faces challenges of scalability, epistemic uncertainty, and mismatches between learned representations and human concepts. Our position is that progress on safe and trustworthy AI will depend on making interpretability a first-class objective of AI research and development, ensuring that systems are not only effective but also auditable, transparent, and aligned with human intent.
Bridging the Gap in XAI-Why Reliable Metrics Matter for Explainability and Compliance
Feb 07, 2025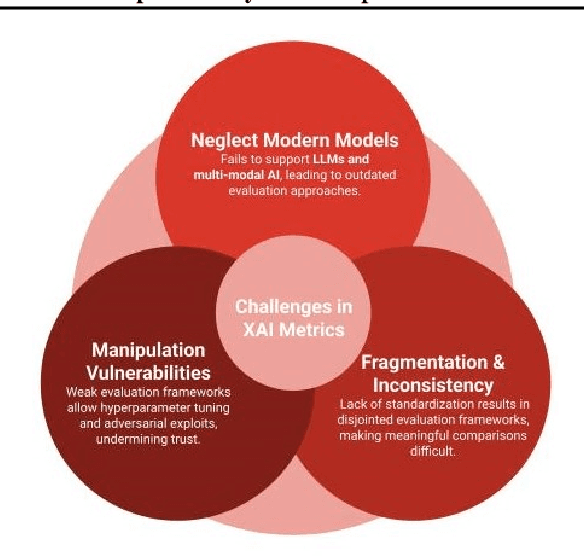
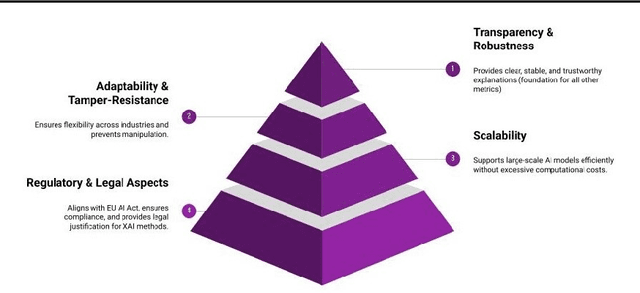
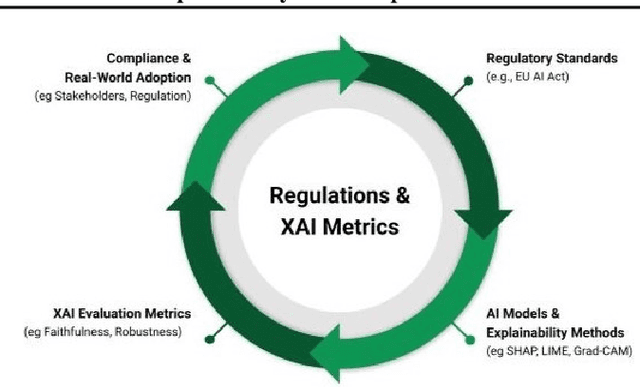
This position paper emphasizes the critical gap in the evaluation of Explainable AI (XAI) due to the lack of standardized and reliable metrics, which diminishes its practical value, trustworthiness, and ability to meet regulatory requirements. Current evaluation methods are often fragmented, subjective, and biased, making them prone to manipulation and complicating the assessment of complex models. A central issue is the absence of a ground truth for explanations, complicating comparisons across various XAI approaches. To address these challenges, we advocate for widespread research into developing robust, context-sensitive evaluation metrics. These metrics should be resistant to manipulation, relevant to each use case, and based on human judgment and real-world applicability. We also recommend creating domain-specific evaluation benchmarks that align with the user and regulatory needs of sectors such as healthcare and finance. By encouraging collaboration among academia, industry, and regulators, we can create standards that balance flexibility and consistency, ensuring XAI explanations are meaningful, trustworthy, and compliant with evolving regulations.
xai_evals : A Framework for Evaluating Post-Hoc Local Explanation Methods
Feb 05, 2025



The growing complexity of machine learning and deep learning models has led to an increased reliance on opaque "black box" systems, making it difficult to understand the rationale behind predictions. This lack of transparency is particularly challenging in high-stakes applications where interpretability is as important as accuracy. Post-hoc explanation methods are commonly used to interpret these models, but they are seldom rigorously evaluated, raising concerns about their reliability. The Python package xai_evals addresses this by providing a comprehensive framework for generating, benchmarking, and evaluating explanation methods across both tabular and image data modalities. It integrates popular techniques like SHAP, LIME, Grad-CAM, Integrated Gradients (IG), and Backtrace, while supporting evaluation metrics such as faithfulness, sensitivity, and robustness. xai_evals enhances the interpretability of machine learning models, fostering transparency and trust in AI systems. The library is open-sourced at https://pypi.org/project/xai-evals/ .
DLBacktrace: A Model Agnostic Explainability for any Deep Learning Models
Nov 19, 2024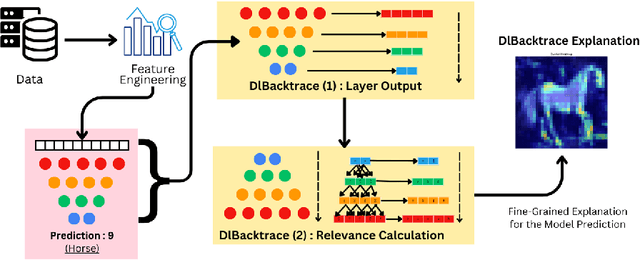
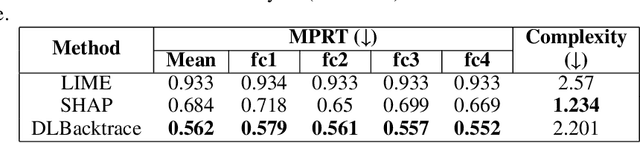
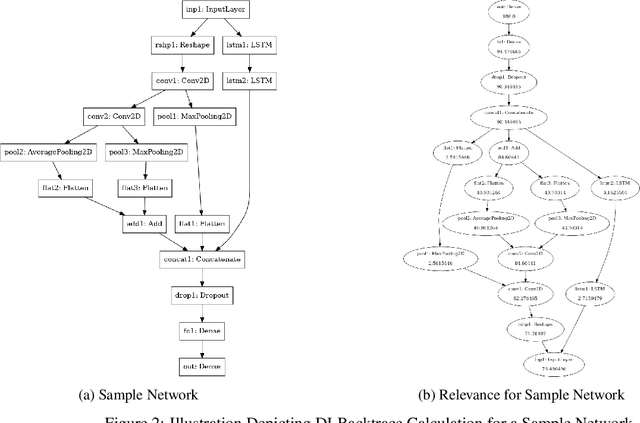
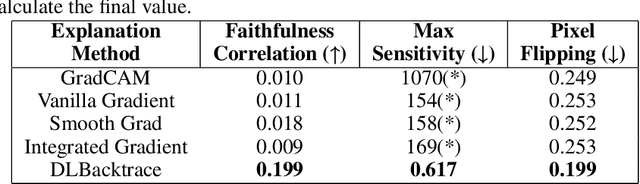
The rapid advancement of artificial intelligence has led to increasingly sophisticated deep learning models, which frequently operate as opaque 'black boxes' with limited transparency in their decision-making processes. This lack of interpretability presents considerable challenges, especially in high-stakes applications where understanding the rationale behind a model's outputs is as essential as the outputs themselves. This study addresses the pressing need for interpretability in AI systems, emphasizing its role in fostering trust, ensuring accountability, and promoting responsible deployment in mission-critical fields. To address the interpretability challenge in deep learning, we introduce DLBacktrace, an innovative technique developed by the AryaXAI team to illuminate model decisions across a wide array of domains, including simple Multi Layer Perceptron (MLPs), Convolutional Neural Networks (CNNs), Large Language Models (LLMs), Computer Vision Models, and more. We provide a comprehensive overview of the DLBacktrace algorithm and present benchmarking results, comparing its performance against established interpretability methods, such as SHAP, LIME, GradCAM, Integrated Gradients, SmoothGrad, and Attention Rollout, using diverse task-based metrics. The proposed DLBacktrace technique is compatible with various model architectures built in PyTorch and TensorFlow, supporting models like Llama 3.2, other NLP architectures such as BERT and LSTMs, computer vision models like ResNet and U-Net, as well as custom deep neural network (DNN) models for tabular data. This flexibility underscores DLBacktrace's adaptability and effectiveness in enhancing model transparency across a broad spectrum of applications. The library is open-sourced and available at https://github.com/AryaXAI/DLBacktrace .