 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDLBacktrace: A Model Agnostic Explainability for any Deep Learning Models
Paper and Code
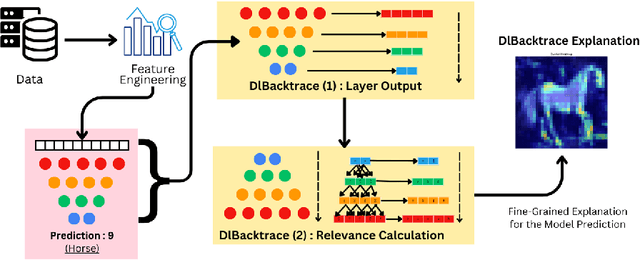
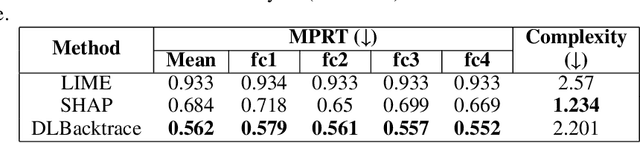
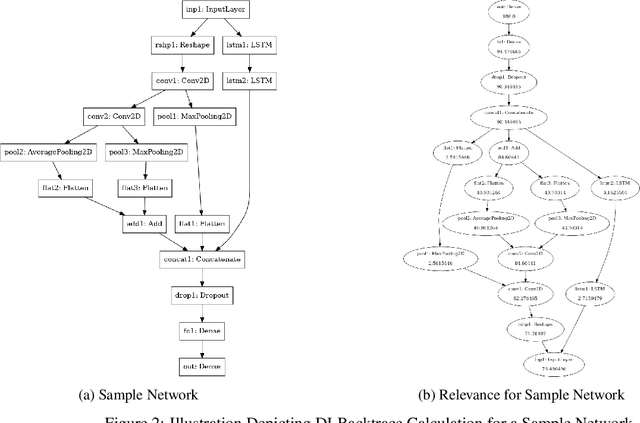
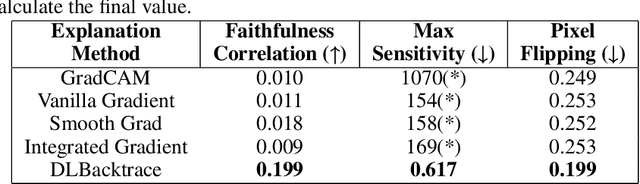
The rapid advancement of artificial intelligence has led to increasingly sophisticated deep learning models, which frequently operate as opaque 'black boxes' with limited transparency in their decision-making processes. This lack of interpretability presents considerable challenges, especially in high-stakes applications where understanding the rationale behind a model's outputs is as essential as the outputs themselves. This study addresses the pressing need for interpretability in AI systems, emphasizing its role in fostering trust, ensuring accountability, and promoting responsible deployment in mission-critical fields. To address the interpretability challenge in deep learning, we introduce DLBacktrace, an innovative technique developed by the AryaXAI team to illuminate model decisions across a wide array of domains, including simple Multi Layer Perceptron (MLPs), Convolutional Neural Networks (CNNs), Large Language Models (LLMs), Computer Vision Models, and more. We provide a comprehensive overview of the DLBacktrace algorithm and present benchmarking results, comparing its performance against established interpretability methods, such as SHAP, LIME, GradCAM, Integrated Gradients, SmoothGrad, and Attention Rollout, using diverse task-based metrics. The proposed DLBacktrace technique is compatible with various model architectures built in PyTorch and TensorFlow, supporting models like Llama 3.2, other NLP architectures such as BERT and LSTMs, computer vision models like ResNet and U-Net, as well as custom deep neural network (DNN) models for tabular data. This flexibility underscores DLBacktrace's adaptability and effectiveness in enhancing model transparency across a broad spectrum of applications. The library is open-sourced and available at https://github.com/AryaXAI/DLBacktrace .