 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging the Gap in XAI-Why Reliable Metrics Matter for Explainability and Compliance
Paper and Code
Feb 07, 2025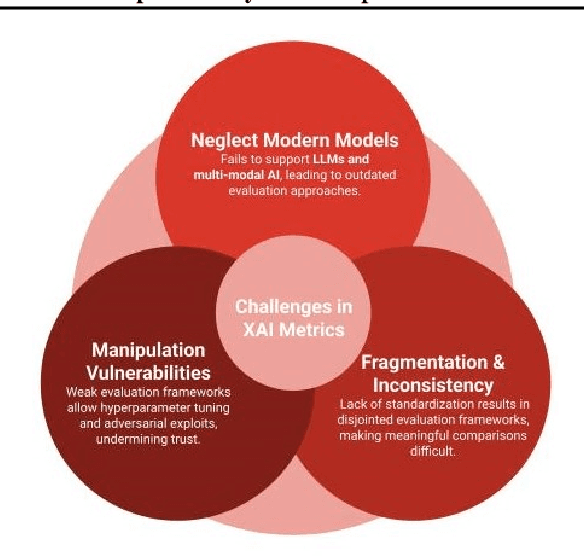
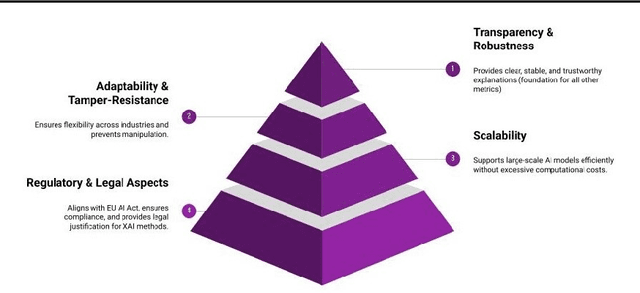
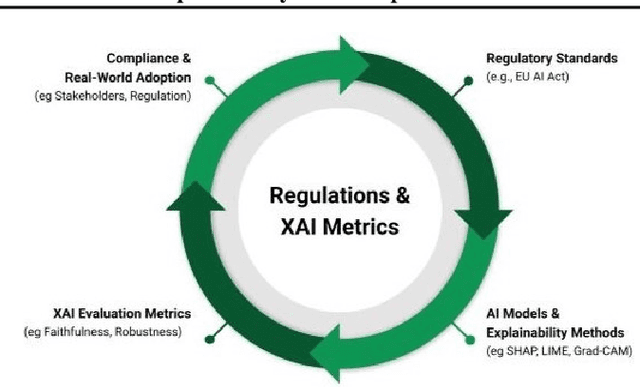
This position paper emphasizes the critical gap in the evaluation of Explainable AI (XAI) due to the lack of standardized and reliable metrics, which diminishes its practical value, trustworthiness, and ability to meet regulatory requirements. Current evaluation methods are often fragmented, subjective, and biased, making them prone to manipulation and complicating the assessment of complex models. A central issue is the absence of a ground truth for explanations, complicating comparisons across various XAI approaches. To address these challenges, we advocate for widespread research into developing robust, context-sensitive evaluation metrics. These metrics should be resistant to manipulation, relevant to each use case, and based on human judgment and real-world applicability. We also recommend creating domain-specific evaluation benchmarks that align with the user and regulatory needs of sectors such as healthcare and finance. By encouraging collaboration among academia, industry, and regulators, we can create standards that balance flexibility and consistency, ensuring XAI explanations are meaningful, trustworthy, and compliant with evolving regulations.