 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiview Self-Representation Learning across Heterogeneous Views
Feb 04, 2026Features of the same sample generated by different pretrained models often exhibit inherently distinct feature distributions because of discrepancies in the model pretraining objectives or architectures. Learning invariant representations from large-scale unlabeled visual data with various pretrained models in a fully unsupervised transfer manner remains a significant challenge. In this paper, we propose a multiview self-representation learning (MSRL) method in which invariant representations are learned by exploiting the self-representation property of features across heterogeneous views. The features are derived from large-scale unlabeled visual data through transfer learning with various pretrained models and are referred to as heterogeneous multiview data. An individual linear model is stacked on top of its corresponding frozen pretrained backbone. We introduce an information-passing mechanism that relies on self-representation learning to support feature aggregation over the outputs of the linear model. Moreover, an assignment probability distribution consistency scheme is presented to guide multiview self-representation learning by exploiting complementary information across different views. Consequently, representation invariance across different linear models is enforced through this scheme. In addition, we provide a theoretical analysis of the information-passing mechanism, the assignment probability distribution consistency and the incremental views. Extensive experiments with multiple benchmark visual datasets demonstrate that the proposed MSRL method consistently outperforms several state-of-the-art approaches.
RegionRAG: Region-level Retrieval-Augumented Generation for Visually-Rich Documents
Oct 31, 2025

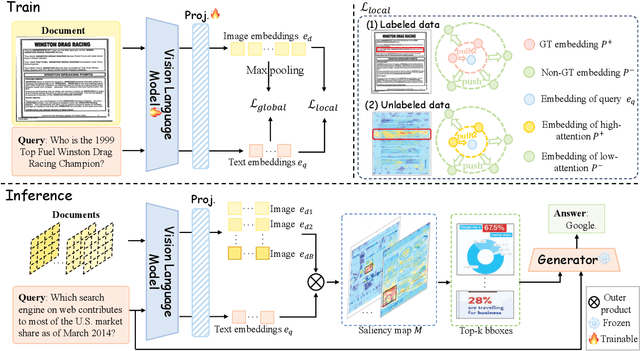

Multi-modal Retrieval-Augmented Generation (RAG) has become a critical method for empowering LLMs by leveraging candidate visual documents. However, current methods consider the entire document as the basic retrieval unit, introducing substantial irrelevant visual content in two ways: 1) Relevant documents often contain large regions unrelated to the query, diluting the focus on salient information; 2) Retrieving multiple documents to increase recall further introduces redundant and irrelevant documents. These redundant contexts distract the model's attention and further degrade the performance. To address this challenge, we propose \modelname, a novel framework that shifts the retrieval paradigm from the document level to the region level. During training, we design a hybrid supervision strategy from both labeled data and unlabeled data to pinpoint relevant patches. During inference, we propose a dynamic pipeline that intelligently groups salient patches into complete semantic regions. By delegating the task of identifying relevant regions to the retriever, \modelname enables the generator to focus solely on concise visual content relevant to queries, improving both efficiency and accuracy. Experiments on six benchmarks demonstrate that RegionRAG achieves state-of-the-art performance. Improves retrieval accuracy by 10.02\% in R@1 on average and increases question answering accuracy by 3.56\% while using only 71.42\% visual tokens compared to prior methods. The code will be available at https://github.com/Aeryn666/RegionRAG.
From Evaluation to Defense: Advancing Safety in Video Large Language Models
May 22, 2025



While the safety risks of image-based large language models have been extensively studied, their video-based counterparts (Video LLMs) remain critically under-examined. To systematically study this problem, we introduce \textbf{VideoSafetyBench (VSB-77k) - the first large-scale, culturally diverse benchmark for Video LLM safety}, which compromises 77,646 video-query pairs and spans 19 principal risk categories across 10 language communities. \textit{We reveal that integrating video modality degrades safety performance by an average of 42.3\%, exposing systemic risks in multimodal attack exploitation.} To address this vulnerability, we propose \textbf{VideoSafety-R1}, a dual-stage framework achieving unprecedented safety gains through two innovations: (1) Alarm Token-Guided Safety Fine-Tuning (AT-SFT) injects learnable alarm tokens into visual and textual sequences, enabling explicit harm perception across modalities via multitask objectives. (2) Then, Safety-Guided GRPO enhances defensive reasoning through dynamic policy optimization with rule-based rewards derived from dual-modality verification. These components synergize to shift safety alignment from passive harm recognition to active reasoning. The resulting framework achieves a 65.1\% improvement on VSB-Eval-HH, and improves by 59.1\%, 44.3\%, and 15.0\% on the image safety datasets MMBench, VLGuard, and FigStep, respectively. \textit{Our codes are available in the supplementary materials.} \textcolor{red}{Warning: This paper contains examples of harmful language and videos, and reader discretion is recommended.}
PosterMaker: Towards High-Quality Product Poster Generation with Accurate Text Rendering
Apr 09, 2025Product posters, which integrate subject, scene, and text, are crucial promotional tools for attracting customers. Creating such posters using modern image generation methods is valuable, while the main challenge lies in accurately rendering text, especially for complex writing systems like Chinese, which contains over 10,000 individual characters. In this work, we identify the key to precise text rendering as constructing a character-discriminative visual feature as a control signal. Based on this insight, we propose a robust character-wise representation as control and we develop TextRenderNet, which achieves a high text rendering accuracy of over 90%. Another challenge in poster generation is maintaining the fidelity of user-specific products. We address this by introducing SceneGenNet, an inpainting-based model, and propose subject fidelity feedback learning to further enhance fidelity. Based on TextRenderNet and SceneGenNet, we present PosterMaker, an end-to-end generation framework. To optimize PosterMaker efficiently, we implement a two-stage training strategy that decouples text rendering and background generation learning. Experimental results show that PosterMaker outperforms existing baselines by a remarkable margin, which demonstrates its effectiveness.
Hybrid-Level Instruction Injection for Video Token Compression in Multi-modal Large Language Models
Mar 20, 2025Recent Multi-modal Large Language Models (MLLMs) have been challenged by the computational overhead resulting from massive video frames, often alleviated through compression strategies. However, the visual content is not equally contributed to user instructions, existing strategies (\eg, average pool) inevitably lead to the loss of potentially useful information. To tackle this, we propose the Hybrid-level Instruction Injection Strategy for Conditional Token Compression in MLLMs (HICom), utilizing the instruction as a condition to guide the compression from both local and global levels. This encourages the compression to retain the maximum amount of user-focused information while reducing visual tokens to minimize computational burden. Specifically, the instruction condition is injected into the grouped visual tokens at the local level and the learnable tokens at the global level, and we conduct the attention mechanism to complete the conditional compression. From the hybrid-level compression, the instruction-relevant visual parts are highlighted while the temporal-spatial structure is also preserved for easier understanding of LLMs. To further unleash the potential of HICom, we introduce a new conditional pre-training stage with our proposed dataset HICom-248K. Experiments show that our HICom can obtain distinguished video understanding ability with fewer tokens, increasing the performance by 2.43\% average on three multiple-choice QA benchmarks and saving 78.8\% tokens compared with the SOTA method. The code is available at https://github.com/lntzm/HICom.
Hallucination Mitigation Prompts Long-term Video Understanding
Jun 17, 2024



Recently, multimodal large language models have made significant advancements in video understanding tasks. However, their ability to understand unprocessed long videos is very limited, primarily due to the difficulty in supporting the enormous memory overhead. Although existing methods achieve a balance between memory and information by aggregating frames, they inevitably introduce the severe hallucination issue. To address this issue, this paper constructs a comprehensive hallucination mitigation pipeline based on existing MLLMs. Specifically, we use the CLIP Score to guide the frame sampling process with questions, selecting key frames relevant to the question. Then, We inject question information into the queries of the image Q-former to obtain more important visual features. Finally, during the answer generation stage, we utilize chain-of-thought and in-context learning techniques to explicitly control the generation of answers. It is worth mentioning that for the breakpoint mode, we found that image understanding models achieved better results than video understanding models. Therefore, we aggregated the answers from both types of models using a comparison mechanism. Ultimately, We achieved 84.2\% and 62.9\% for the global and breakpoint modes respectively on the MovieChat dataset, surpassing the official baseline model by 29.1\% and 24.1\%. Moreover the proposed method won the third place in the CVPR LOVEU 2024 Long-Term Video Question Answering Challenge. The code is avaiable at https://github.com/lntzm/CVPR24Track-LongVideo
TextPainter: Multimodal Text Image Generation with Visual-harmony and Text-comprehension for Poster Design
Aug 13, 2023Text design is one of the most critical procedures in poster design, as it relies heavily on the creativity and expertise of humans to design text images considering the visual harmony and text-semantic. This study introduces TextPainter, a novel multimodal approach that leverages contextual visual information and corresponding text semantics to generate text images. Specifically, TextPainter takes the global-local background image as a hint of style and guides the text image generation with visual harmony. Furthermore, we leverage the language model and introduce a text comprehension module to achieve both sentence-level and word-level style variations. Besides, we construct the PosterT80K dataset, consisting of about 80K posters annotated with sentence-level bounding boxes and text contents. We hope this dataset will pave the way for further research on multimodal text image generation. Extensive quantitative and qualitative experiments demonstrate that TextPainter can generate visually-and-semantically-harmonious text images for posters.
Bridging the Gap Between Vision Transformers and Convolutional Neural Networks on Small Datasets
Oct 12, 2022
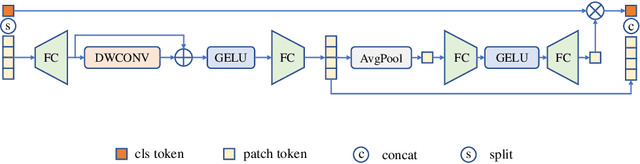

There still remains an extreme performance gap between Vision Transformers (ViTs) and Convolutional Neural Networks (CNNs) when training from scratch on small datasets, which is concluded to the lack of inductive bias. In this paper, we further consider this problem and point out two weaknesses of ViTs in inductive biases, that is, the spatial relevance and diverse channel representation. First, on spatial aspect, objects are locally compact and relevant, thus fine-grained feature needs to be extracted from a token and its neighbors. While the lack of data hinders ViTs to attend the spatial relevance. Second, on channel aspect, representation exhibits diversity on different channels. But the scarce data can not enable ViTs to learn strong enough representation for accurate recognition. To this end, we propose Dynamic Hybrid Vision Transformer (DHVT) as the solution to enhance the two inductive biases. On spatial aspect, we adopt a hybrid structure, in which convolution is integrated into patch embedding and multi-layer perceptron module, forcing the model to capture the token features as well as their neighboring features. On channel aspect, we introduce a dynamic feature aggregation module in MLP and a brand new "head token" design in multi-head self-attention module to help re-calibrate channel representation and make different channel group representation interacts with each other. The fusion of weak channel representation forms a strong enough representation for classification. With this design, we successfully eliminate the performance gap between CNNs and ViTs, and our DHVT achieves a series of state-of-the-art performance with a lightweight model, 85.68% on CIFAR-100 with 22.8M parameters, 82.3% on ImageNet-1K with 24.0M parameters. Code is available at https://github.com/ArieSeirack/DHVT.
Geometry Aligned Variational Transformer for Image-conditioned Layout Generation
Sep 02, 2022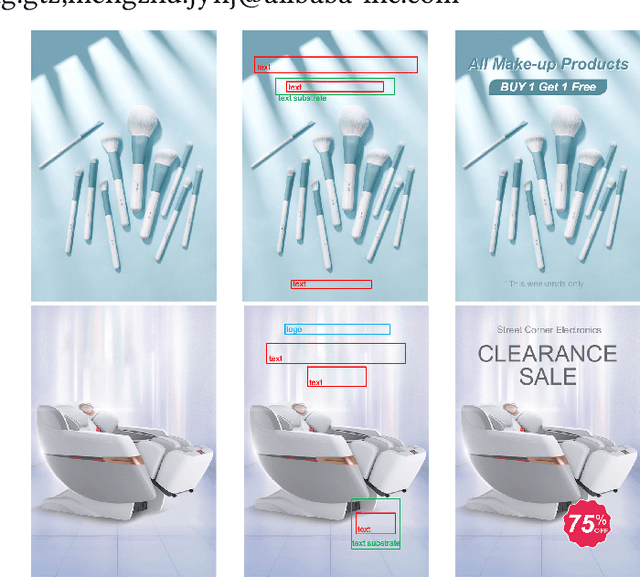
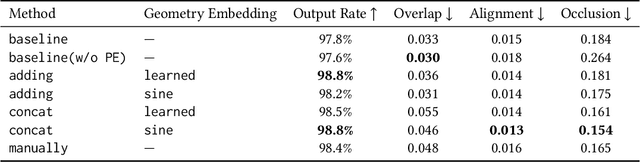
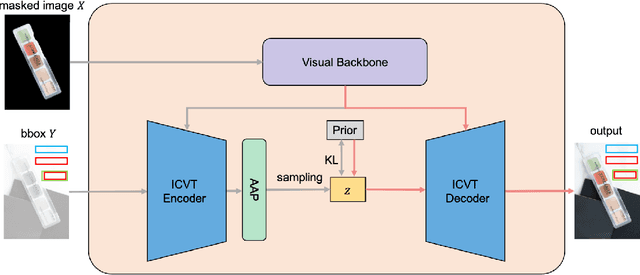

Layout generation is a novel task in computer vision, which combines the challenges in both object localization and aesthetic appraisal, widely used in advertisements, posters, and slides design. An accurate and pleasant layout should consider both the intra-domain relationship within layout elements and the inter-domain relationship between layout elements and the image. However, most previous methods simply focus on image-content-agnostic layout generation, without leveraging the complex visual information from the image. To this end, we explore a novel paradigm entitled image-conditioned layout generation, which aims to add text overlays to an image in a semantically coherent manner. Specifically, we propose an Image-Conditioned Variational Transformer (ICVT) that autoregressively generates various layouts in an image. First, self-attention mechanism is adopted to model the contextual relationship within layout elements, while cross-attention mechanism is used to fuse the visual information of conditional images. Subsequently, we take them as building blocks of conditional variational autoencoder (CVAE), which demonstrates appealing diversity. Second, in order to alleviate the gap between layout elements domain and visual domain, we design a Geometry Alignment module, in which the geometric information of the image is aligned with the layout representation. In addition, we construct a large-scale advertisement poster layout designing dataset with delicate layout and saliency map annotations. Experimental results show that our model can adaptively generate layouts in the non-intrusive area of the image, resulting in a harmonious layout design.