 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoPoster: A Highly Automatic and Content-aware Design System for Advertising Poster Generation
Aug 23, 2023



Advertising posters, a form of information presentation, combine visual and linguistic modalities. Creating a poster involves multiple steps and necessitates design experience and creativity. This paper introduces AutoPoster, a highly automatic and content-aware system for generating advertising posters. With only product images and titles as inputs, AutoPoster can automatically produce posters of varying sizes through four key stages: image cleaning and retargeting, layout generation, tagline generation, and style attribute prediction. To ensure visual harmony of posters, two content-aware models are incorporated for layout and tagline generation. Moreover, we propose a novel multi-task Style Attribute Predictor (SAP) to jointly predict visual style attributes. Meanwhile, to our knowledge, we propose the first poster generation dataset that includes visual attribute annotations for over 76k posters. Qualitative and quantitative outcomes from user studies and experiments substantiate the efficacy of our system and the aesthetic superiority of the generated posters compared to other poster generation methods.
TextPainter: Multimodal Text Image Generation with Visual-harmony and Text-comprehension for Poster Design
Aug 13, 2023Text design is one of the most critical procedures in poster design, as it relies heavily on the creativity and expertise of humans to design text images considering the visual harmony and text-semantic. This study introduces TextPainter, a novel multimodal approach that leverages contextual visual information and corresponding text semantics to generate text images. Specifically, TextPainter takes the global-local background image as a hint of style and guides the text image generation with visual harmony. Furthermore, we leverage the language model and introduce a text comprehension module to achieve both sentence-level and word-level style variations. Besides, we construct the PosterT80K dataset, consisting of about 80K posters annotated with sentence-level bounding boxes and text contents. We hope this dataset will pave the way for further research on multimodal text image generation. Extensive quantitative and qualitative experiments demonstrate that TextPainter can generate visually-and-semantically-harmonious text images for posters.
Face Parsing with RoI Tanh-Warping
Jun 04, 2019
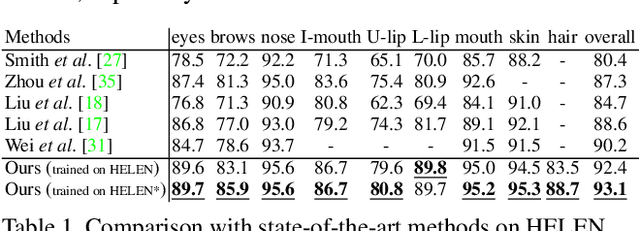


Face parsing computes pixel-wise label maps for different semantic components (e.g., hair, mouth, eyes) from face images. Existing face parsing literature have illustrated significant advantages by focusing on individual regions of interest (RoIs) for faces and facial components. However, the traditional crop-and-resize focusing mechanism ignores all contextual area outside the RoIs, and thus is not suitable when the component area is unpredictable, e.g. hair. Inspired by the physiological vision system of human, we propose a novel RoI Tanh-warping operator that combines the central vision and the peripheral vision together. It addresses the dilemma between a limited sized RoI for focusing and an unpredictable area of surrounding context for peripheral information. To this end, we propose a novel hybrid convolutional neural network for face parsing. It uses hierarchical local based method for inner facial components and global methods for outer facial components. The whole framework is simple and principled, and can be trained end-to-end. To facilitate future research of face parsing, we also manually relabel the training data of the HELEN dataset and will make it public. Experiments on both HELEN and LFW-PL benchmarks demonstrate that our method surpasses state-of-the-art methods.