 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Synthetic Data Boost the Training of Deep Acoustic Vehicle Counting Networks?
Jan 17, 2024
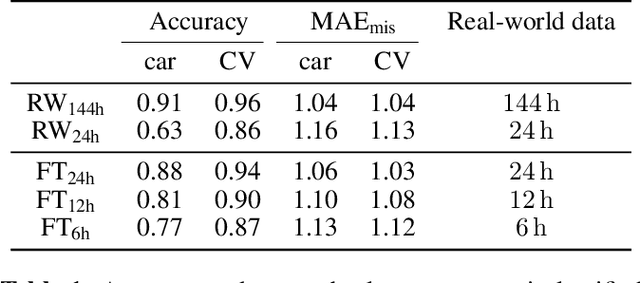
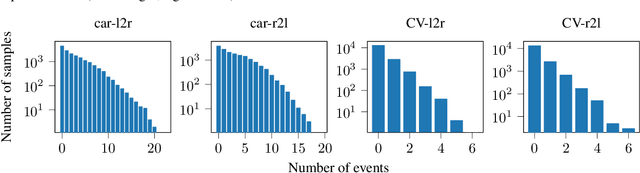
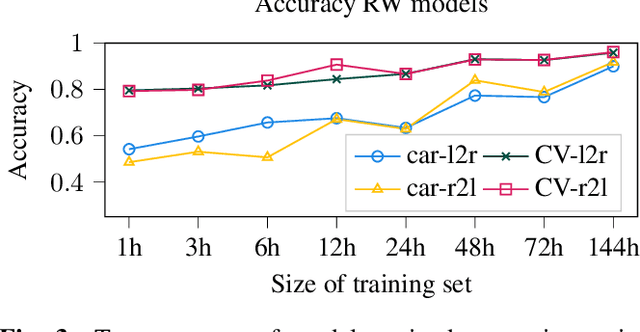
In the design of traffic monitoring solutions for optimizing the urban mobility infrastructure, acoustic vehicle counting models have received attention due to their cost effectiveness and energy efficiency. Although deep learning has proven effective for visual traffic monitoring, its use has not been thoroughly investigated in the audio domain, likely due to real-world data scarcity. In this work, we propose a novel approach to acoustic vehicle counting by developing: i) a traffic noise simulation framework to synthesize realistic vehicle pass-by events; ii) a strategy to mix synthetic and real data to train a deep-learning model for traffic counting. The proposed system is capable of simultaneously counting cars and commercial vehicles driving on a two-lane road, and identifying their direction of travel under moderate traffic density conditions. With only 24 hours of labeled real-world traffic noise, we are able to improve counting accuracy on real-world data from $63\%$ to $88\%$ for cars and from $86\%$ to $94\%$ for commercial vehicles.
Two vs. Four-Channel Sound Event Localization and Detection
Sep 23, 2023Sound event localization and detection (SELD) systems estimate both the direction-of-arrival (DOA) and class of sound sources over time. In the DCASE 2022 SELD Challenge (Task 3), models are designed to operate in a 4-channel setting. While beneficial to further the development of SELD systems using a multichannel recording setup such as first-order Ambisonics (FOA), most consumer electronics devices rarely are able to record using more than two channels. For this reason, in this work we investigate the performance of the DCASE 2022 SELD baseline model using three audio input representations: FOA, binaural, and stereo. We perform a novel comparative analysis illustrating the effect of these audio input representations on SELD performance. Crucially, we show that binaural and stereo (i.e. 2-channel) audio-based SELD models are still able to localize and detect sound sources laterally quite well, despite overall performance degrading as less audio information is provided. Further, we segment our analysis by scenes containing varying degrees of sound source polyphony to better understand the effect of audio input representation on localization and detection performance as scene conditions become increasingly complex.
Unsupervised Discriminative Learning of Sounds for Audio Event Classification
May 20, 2021
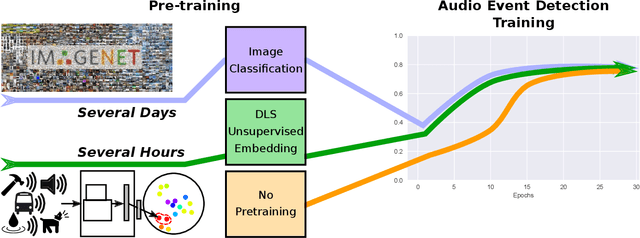

Recent progress in network-based audio event classification has shown the benefit of pre-training models on visual data such as ImageNet. While this process allows knowledge transfer across different domains, training a model on large-scale visual datasets is time consuming. On several audio event classification benchmarks, we show a fast and effective alternative that pre-trains the model unsupervised, only on audio data and yet delivers on-par performance with ImageNet pre-training. Furthermore, we show that our discriminative audio learning can be used to transfer knowledge across audio datasets and optionally include ImageNet pre-training.
Visualizing Classification Structure in Deep Neural Networks
Jul 12, 2020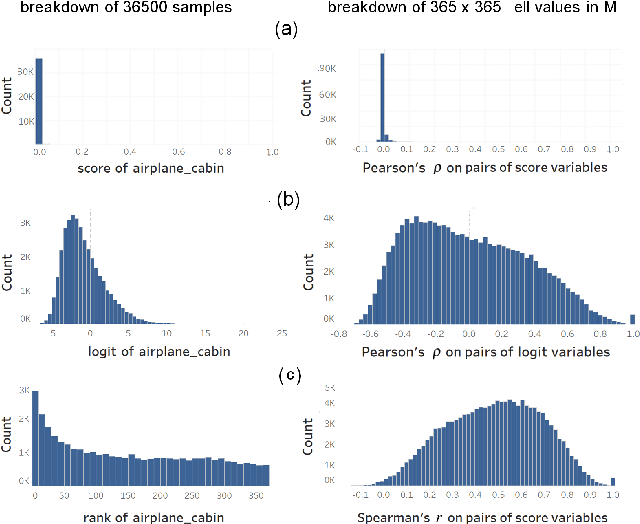
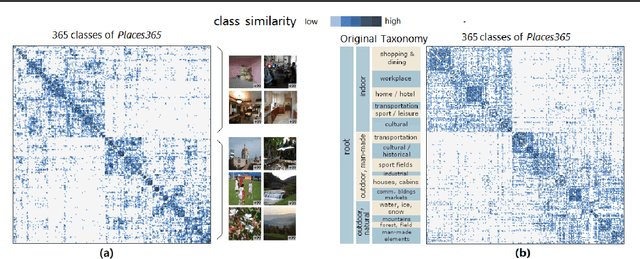
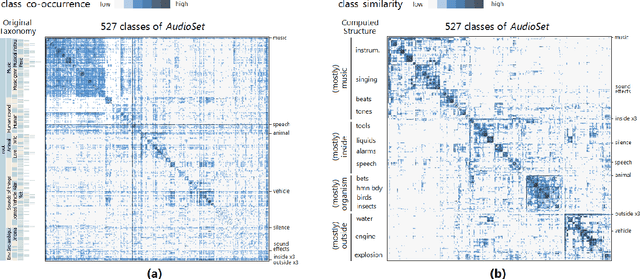
We propose a measure to compute class similarity in large-scale classification based on prediction scores. Such measure has not been formally pro-posed in the literature. We show how visualizing the class similarity matrix can reveal hierarchical structures and relationships that govern the classes. Through examples with various classifiers, we demonstrate how such structures can help in analyzing the classification behavior and in inferring potential corner cases. The source code for one example is available as a notebook at https://github.com/bilalsal/blocks
An Ontology-Aware Framework for Audio Event Classification
Jan 27, 2020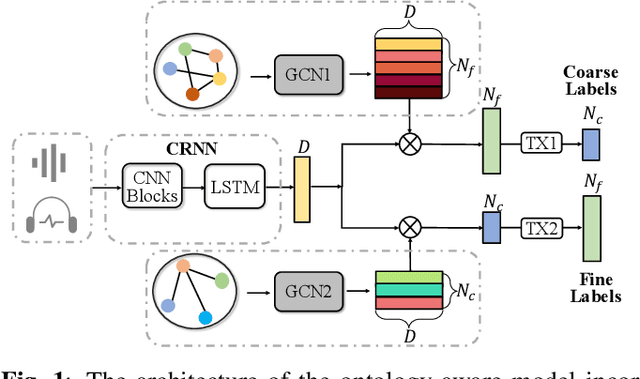
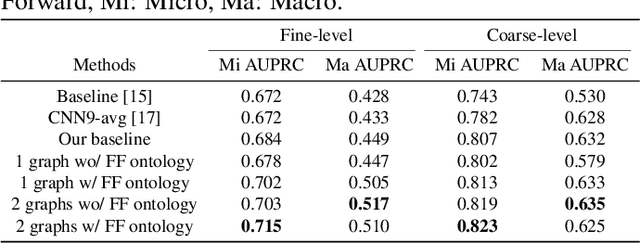
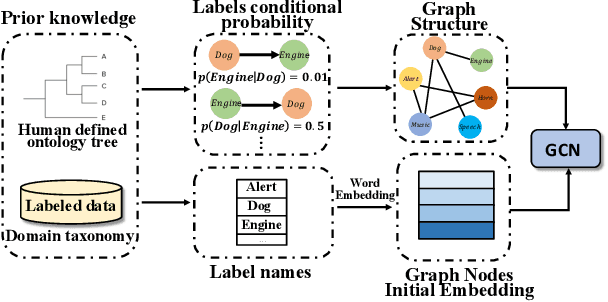
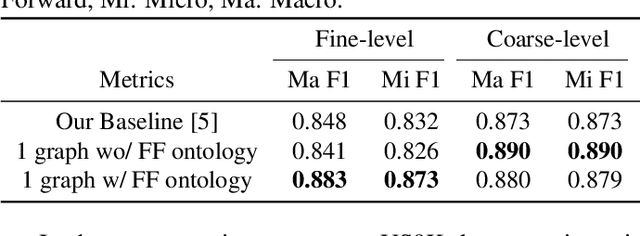
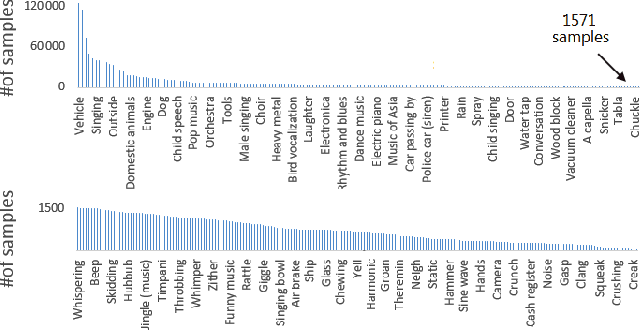
Recent advancements in audio event classification often ignore the structure and relation between the label classes available as prior information. This structure can be defined by ontology and augmented in the classifier as a form of domain knowledge. To capture such dependencies between the labels, we propose an ontology-aware neural network containing two components: feed-forward ontology layers and graph convolutional networks (GCN). The feed-forward ontology layers capture the intra-dependencies of labels between different levels of ontology. On the other hand, GCN mainly models inter-dependency structure of labels within an ontology level. The framework is evaluated on two benchmark datasets for single-label and multi-label audio event classification tasks. The results demonstrate the proposed solutions efficacy to capture and explore the ontology relations and improve the classification performance.
Self-supervised Attention Model for Weakly Labeled Audio Event Classification
Aug 07, 2019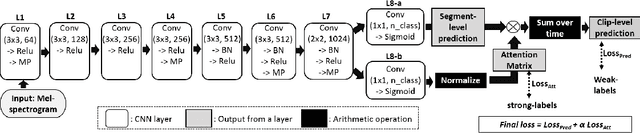

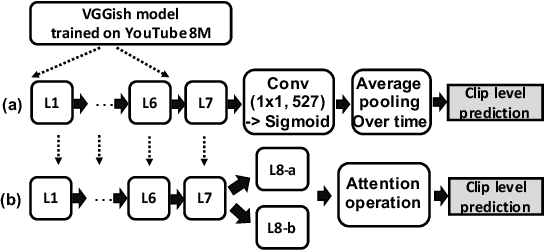
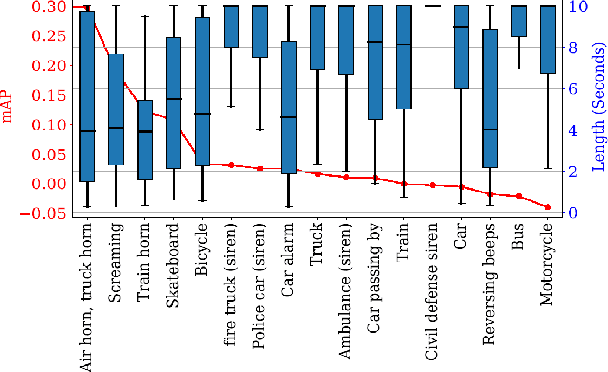
We describe a novel weakly labeled Audio Event Classification approach based on a self-supervised attention model. The weakly labeled framework is used to eliminate the need for expensive data labeling procedure and self-supervised attention is deployed to help a model distinguish between relevant and irrelevant parts of a weakly labeled audio clip in a more effective manner compared to prior attention models. We also propose a highly effective strongly supervised attention model when strong labels are available. This model also serves as an upper bound for the self-supervised model. The performances of the model with self-supervised attention training are comparable to the strongly supervised one which is trained using strong labels. We show that our self-supervised attention method is especially beneficial for short audio events. We achieve 8.8% and 17.6% relative mean average precision improvements over the current state-of-the-art systems for SL-DCASE-17 and balanced AudioSet.
An Ensemble of Transfer, Semi-supervised and Supervised Learning Methods for Pathological Heart Sound Classification
Oct 07, 2018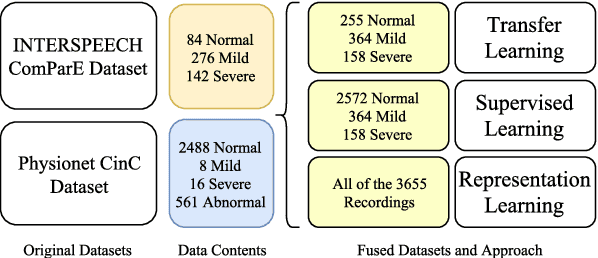
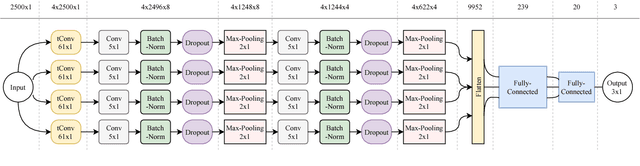

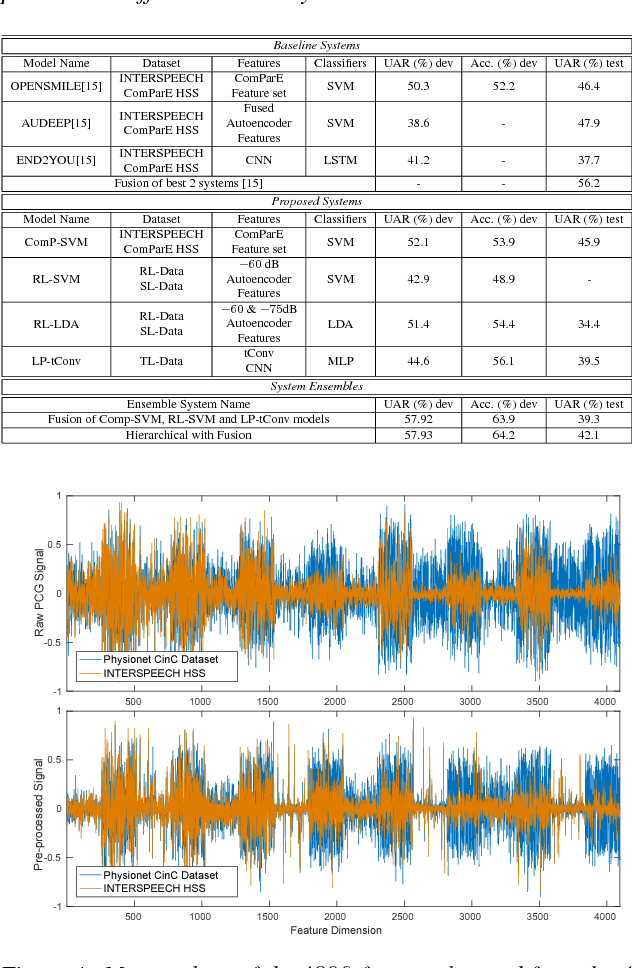
In this work, we propose an ensemble of classifiers to distinguish between various degrees of abnormalities of the heart using Phonocardiogram (PCG) signals acquired using digital stethoscopes in a clinical setting, for the INTERSPEECH 2018 Computational Paralinguistics (ComParE) Heart Beats SubChallenge. Our primary classification framework constitutes a convolutional neural network with 1D-CNN time-convolution (tConv) layers, which uses features transferred from a model trained on the 2016 Physionet Heart Sound Database. We also employ a Representation Learning (RL) approach to generate features in an unsupervised manner using Deep Recurrent Autoencoders and use Support Vector Machine (SVM) and Linear Discriminant Analysis (LDA) classifiers. Finally, we utilize an SVM classifier on a high-dimensional segment-level feature extracted using various functionals on short-term acoustic features, i.e., Low-Level Descriptors (LLD). An ensemble of the three different approaches provides a relative improvement of 11.13% compared to our best single sub-system in terms of the Unweighted Average Recall (UAR) performance metric on the evaluation dataset.
Deep Multiple Instance Feature Learning via Variational Autoencoder
Jul 06, 2018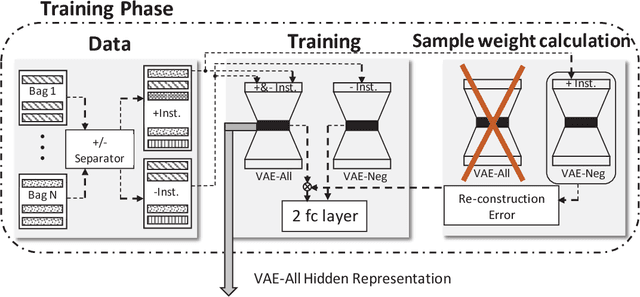

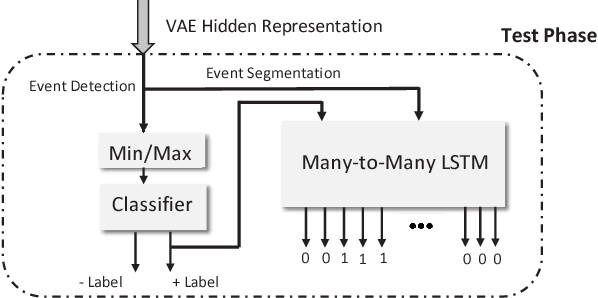
We describe a novel weakly supervised deep learning framework that combines both the discriminative and generative models to learn meaningful representation in the multiple instance learning (MIL) setting. MIL is a weakly supervised learning problem where labels are associated with groups of instances (referred as bags) instead of individual instances. To address the essential challenge in MIL problems raised from the uncertainty of positive instances label, we use a discriminative model regularized by variational autoencoders (VAEs) to maximize the differences between latent representations of all instances and negative instances. As a result, the hidden layer of the variational autoencoder learns meaningful representation. This representation can effectively be used for MIL problems as illustrated by better performance on the standard benchmark datasets comparing to the state-of-the-art approaches. More importantly, unlike most related studies, the proposed framework can be easily scaled to large dataset problems, as illustrated by the audio event detection and segmentation task. Visualization also confirms the effectiveness of the latent representation in discriminating positive and negative classes.
Learning Front-end Filter-bank Parameters using Convolutional Neural Networks for Abnormal Heart Sound Detection
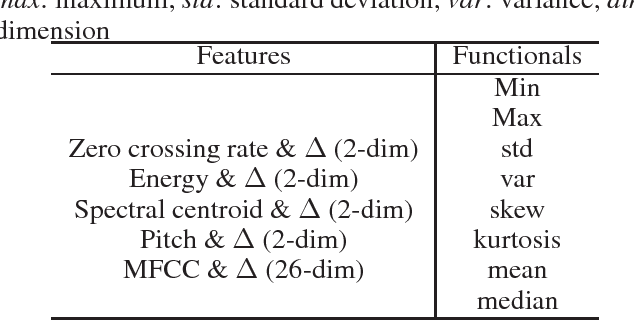
Jun 15, 2018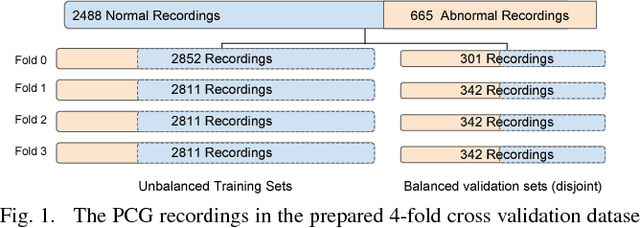
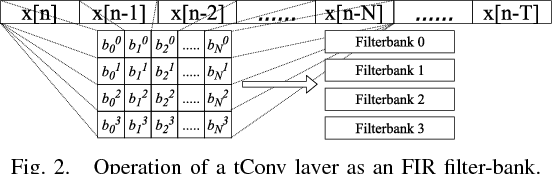
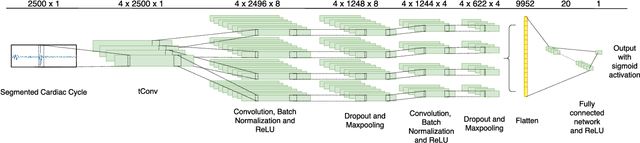
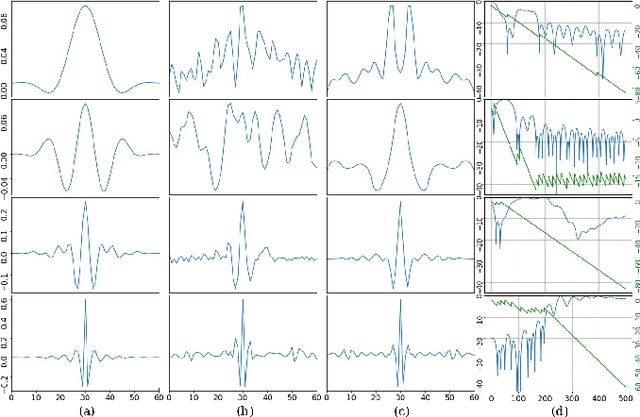
Automatic heart sound abnormality detection can play a vital role in the early diagnosis of heart diseases, particularly in low-resource settings. The state-of-the-art algorithms for this task utilize a set of Finite Impulse Response (FIR) band-pass filters as a front-end followed by a Convolutional Neural Network (CNN) model. In this work, we propound a novel CNN architecture that integrates the front-end bandpass filters within the network using time-convolution (tConv) layers, which enables the FIR filter-bank parameters to become learnable. Different initialization strategies for the learnable filters, including random parameters and a set of predefined FIR filter-bank coefficients, are examined. Using the proposed tConv layers, we add constraints to the learnable FIR filters to ensure linear and zero phase responses. Experimental evaluations are performed on a balanced 4-fold cross-validation task prepared using the PhysioNet/CinC 2016 dataset. Results demonstrate that the proposed models yield superior performance compared to the state-of-the-art system, while the linear phase FIR filterbank method provides an absolute improvement of 9.54% over the baseline in terms of an overall accuracy metric.