 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeACCO: Automated Causal CNN Scheduling Optimizer for Real-Time Edge Accelerators
Jun 11, 2024Spatio-Temporal Convolutional Neural Networks (ST-CNN) allow extending CNN capabilities from image processing to consecutive temporal-pattern recognition. Generally, state-of-the-art (SotA) ST-CNNs inflate the feature maps and weights from well-known CNN backbones to represent the additional time dimension. However, edge computing applications would suffer tremendously from such large computation or memory overhead. Fortunately, the overlapping nature of ST-CNN enables various optimizations, such as the dilated causal convolution structure and Depth-First (DF) layer fusion to reuse the computation between time steps and CNN sliding windows, respectively. Yet, no hardware-aware approach has been proposed that jointly explores the optimal strategy from a scheduling as well as a hardware point of view. To this end, we present ACCO, an automated optimizer that explores efficient Causal CNN transformation and DF scheduling for ST-CNNs on edge hardware accelerators. By cost-modeling the computation and data movement on the accelerator architecture, ACCO automatically selects the best scheduling strategy for the given hardware-algorithm target. Compared to the fixed dilated causal structure, ST-CNNs with ACCO reach an ~8.4x better Energy-Delay-Product. Meanwhile, ACCO improves ~20% in layer-fusion optimals compared to the SotA DF exploration toolchain. When jointly optimizing ST-CNN on the temporal and spatial dimension, ACCO's scheduling outcomes are on average 19x faster and 37x more energy-efficient than spatial DF schemes.
Can Synthetic Data Boost the Training of Deep Acoustic Vehicle Counting Networks?
Jan 17, 2024
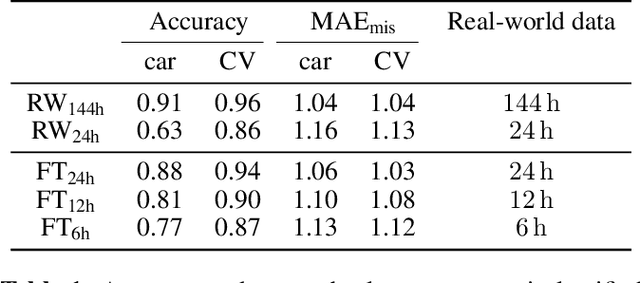
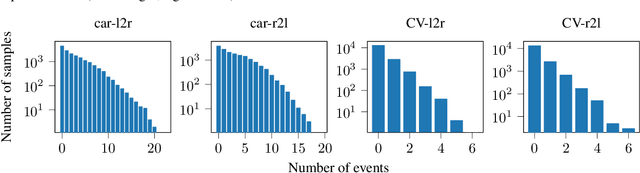
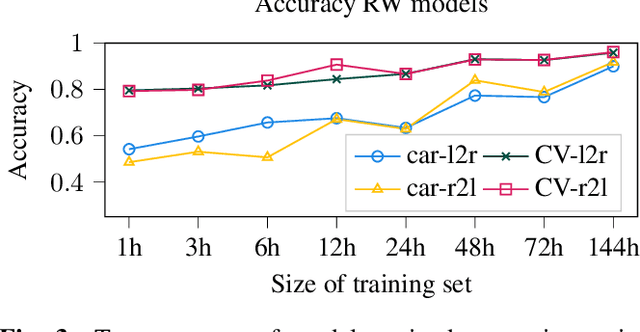
In the design of traffic monitoring solutions for optimizing the urban mobility infrastructure, acoustic vehicle counting models have received attention due to their cost effectiveness and energy efficiency. Although deep learning has proven effective for visual traffic monitoring, its use has not been thoroughly investigated in the audio domain, likely due to real-world data scarcity. In this work, we propose a novel approach to acoustic vehicle counting by developing: i) a traffic noise simulation framework to synthesize realistic vehicle pass-by events; ii) a strategy to mix synthetic and real data to train a deep-learning model for traffic counting. The proposed system is capable of simultaneously counting cars and commercial vehicles driving on a two-lane road, and identifying their direction of travel under moderate traffic density conditions. With only 24 hours of labeled real-world traffic noise, we are able to improve counting accuracy on real-world data from $63\%$ to $88\%$ for cars and from $86\%$ to $94\%$ for commercial vehicles.
Real-Time Acoustic Perception for Automotive Applications
Jan 30, 2023



In recent years the automotive industry has been strongly promoting the development of smart cars, equipped with multi-modal sensors to gather information about the surroundings, in order to aid human drivers or make autonomous decisions. While the focus has mostly been on visual sensors, also acoustic events are crucial to detect situations that require a change in the driving behavior, such as a car honking, or the sirens of approaching emergency vehicles. In this paper, we summarize the results achieved so far in the Marie Sklodowska-Curie Actions (MSCA) European Industrial Doctorates (EID) project Intelligent Ultra Low-Power Signal Processing for Automotive (I-SPOT). On the algorithmic side, the I-SPOT Project aims to enable detecting, localizing and tracking environmental audio signals by jointly developing microphone array processing and deep learning techniques that specifically target automotive applications. Data generation software has been developed to cover the I-SPOT target scenarios and research challenges. This tool is currently being used to develop low-complexity deep learning techniques for emergency sound detection. On the hardware side, the goal impels workflows for hardware-algorithm co-design to ease the generation of architectures that are sufficiently flexible towards algorithmic evolutions without giving up on efficiency, as well as enable rapid feedback of hardware implications of algorithmic decision. This is pursued though a hierarchical workflow that breaks the hardware-algorithm design space into reasonable subsets, which has been tested for operator-level optimizations on state-of-the-art robust sound source localization for edge devices. Further, several open challenges towards an end-to-end system are clarified for the next stage of I-SPOT.
SELD-TCN: Sound Event Localization & Detection via Temporal Convolutional Networks
Mar 03, 2020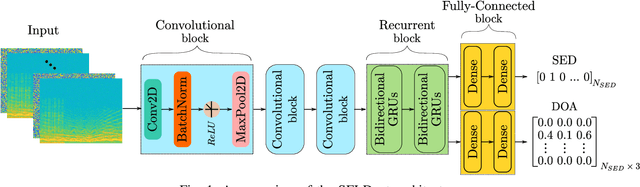
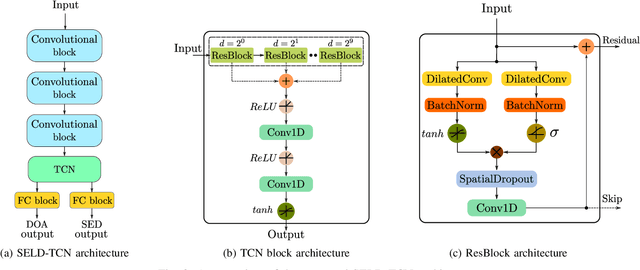
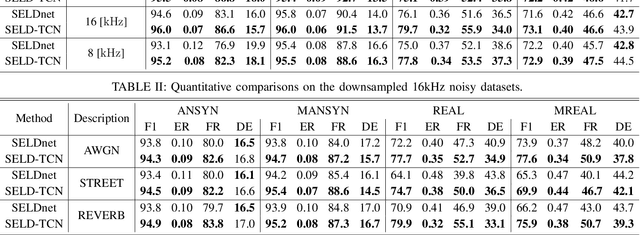
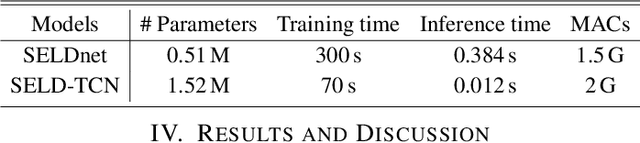
The understanding of the surrounding environment plays a critical role in autonomous robotic systems, such as self-driving cars. Extensive research has been carried out concerning visual perception. Yet, to obtain a more complete perception of the environment, autonomous systems of the future should also take acoustic information into account. Recent sound event localization and detection (SELD) frameworks utilize convolutional recurrent neural networks (CRNNs). However, considering the recurrent nature of CRNNs, it becomes challenging to implement them efficiently on embedded hardware. Not only are their computations strenuous to parallelize, but they also require high memory bandwidth and large memory buffers. In this work, we develop a more robust and hardware-friendly novel architecture based on a temporal convolutional network(TCN). The proposed framework (SELD-TCN) outperforms the state-of-the-art SELDnet performance on four different datasets. Moreover, SELD-TCN achieves 4x faster training time per epoch and 40x faster inference time on an ordinary graphics processing unit (GPU).
An End-to-End HW/SW Co-Design Methodology to Design Efficient Deep Neural Network Systems using Virtual Models
Nov 18, 2019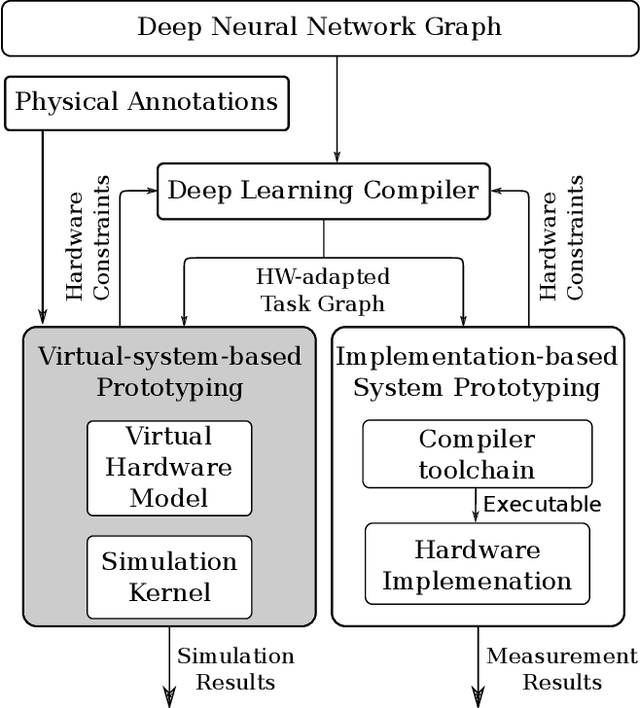
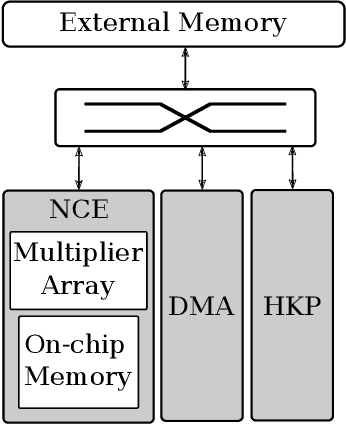
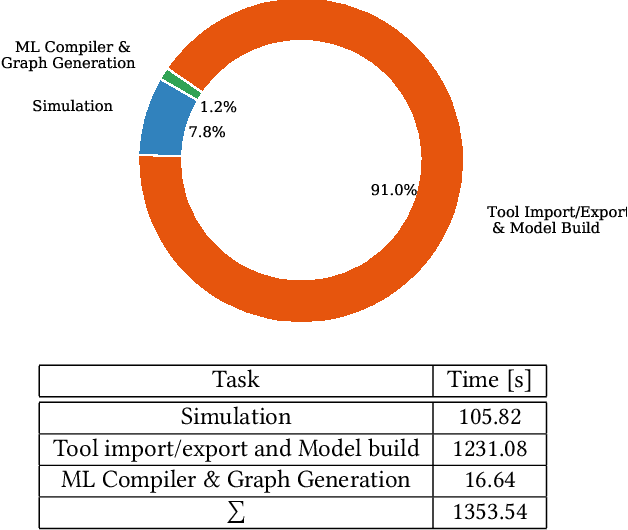
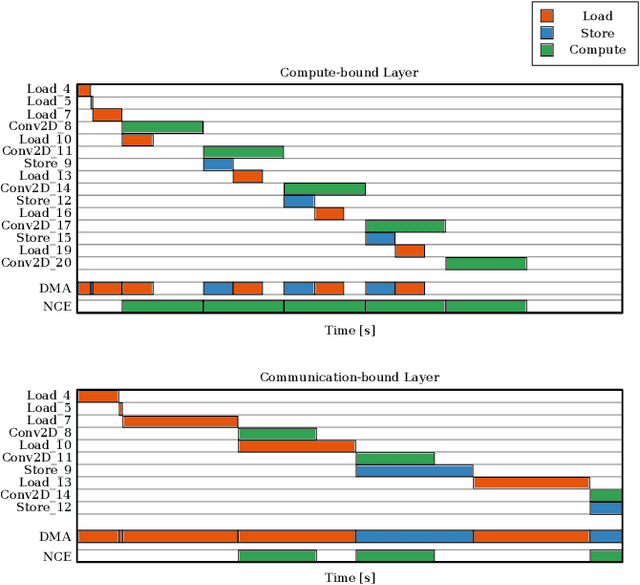
End-to-end performance estimation and measurement of deep neural network (DNN) systems become more important with increasing complexity of DNN systems consisting of hardware and software components. The methodology proposed in this paper aims at a reduced turn-around time for evaluating different design choices of hardware and software components of DNN systems. This reduction is achieved by moving the performance estimation from the implementation phase to the concept phase by employing virtual hardware models instead of gathering measurement results from physical prototypes. Deep learning compilers introduce hardware-specific transformations and are, therefore, considered a part of the design flow of virtual system models to extract end-to-end performance estimations. To validate the run-time accuracy of the proposed methodology, a system processing the DilatedVGG DNN is realized both as virtual system model and as hardware implementation. The results show that up to 92 % accuracy can be reached in predicting the processing time of the DNN inference.
Automated design of error-resilient and hardware-efficient deep neural networks
Sep 30, 2019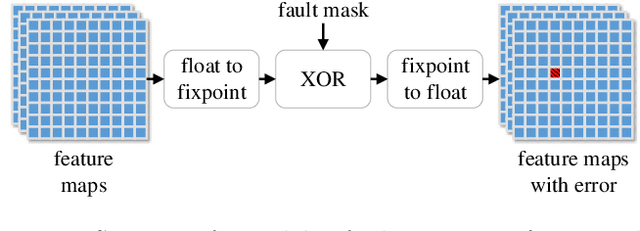
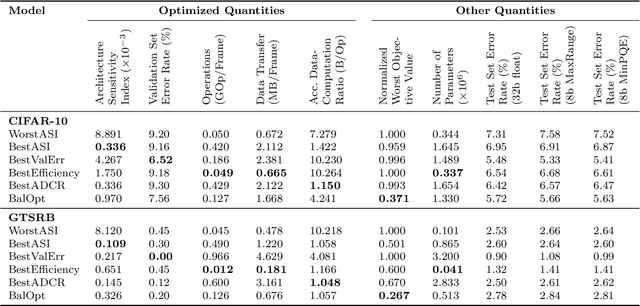
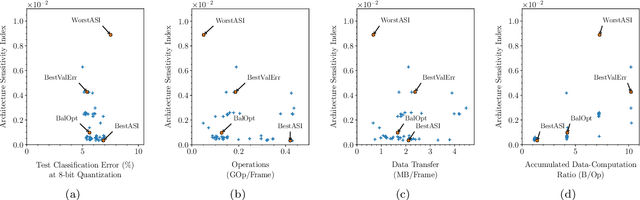
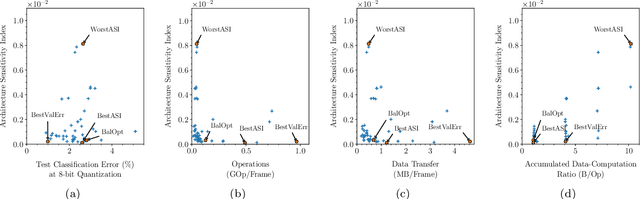
Applying deep neural networks (DNNs) in mobile and safety-critical systems, such as autonomous vehicles, demands a reliable and efficient execution on hardware. Optimized dedicated hardware accelerators are being developed to achieve this. However, the design of efficient and reliable hardware has become increasingly difficult, due to the increased complexity of modern integrated circuit technology and its sensitivity against hardware faults, such as random bit-flips. It is thus desirable to exploit optimization potential for error resilience and efficiency also at the algorithmic side, e.g., by optimizing the architecture of the DNN. Since there are numerous design choices for the architecture of DNNs, with partially opposing effects on the preferred characteristics (such as small error rates at low latency), multi-objective optimization strategies are necessary. In this paper, we develop an evolutionary optimization technique for the automated design of hardware-optimized DNN architectures. For this purpose, we derive a set of easily computable objective functions, which enable the fast evaluation of DNN architectures with respect to their hardware efficiency and error resilience solely based on the network topology. We observe a strong correlation between predicted error resilience and actual measurements obtained from fault injection simulations. Furthermore, we analyze two different quantization schemes for efficient DNN computation and find significant differences regarding their effect on error resilience.
Efficient Stochastic Inference of Bitwise Deep Neural Networks
Nov 20, 2016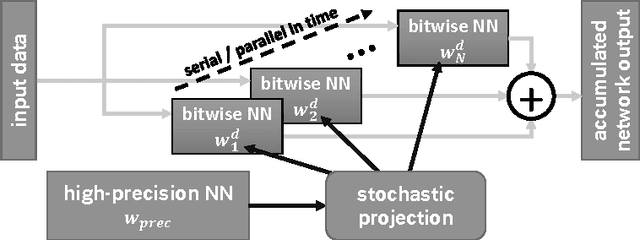
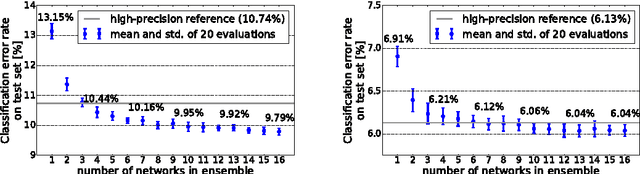
Recently published methods enable training of bitwise neural networks which allow reduced representation of down to a single bit per weight. We present a method that exploits ensemble decisions based on multiple stochastically sampled network models to increase performance figures of bitwise neural networks in terms of classification accuracy at inference. Our experiments with the CIFAR-10 and GTSRB datasets show that the performance of such network ensembles surpasses the performance of the high-precision base model. With this technique we achieve 5.81% best classification error on CIFAR-10 test set using bitwise networks. Concerning inference on embedded systems we evaluate these bitwise networks using a hardware efficient stochastic rounding procedure. Our work contributes to efficient embedded bitwise neural networks.