 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Architecture Search: Insights from 1000 Papers
Jan 25, 2023



In the past decade, advances in deep learning have resulted in breakthroughs in a variety of areas, including computer vision, natural language understanding, speech recognition, and reinforcement learning. Specialized, high-performing neural architectures are crucial to the success of deep learning in these areas. Neural architecture search (NAS), the process of automating the design of neural architectures for a given task, is an inevitable next step in automating machine learning and has already outpaced the best human-designed architectures on many tasks. In the past few years, research in NAS has been progressing rapidly, with over 1000 papers released since 2020 (Deng and Lindauer, 2021). In this survey, we provide an organized and comprehensive guide to neural architecture search. We give a taxonomy of search spaces, algorithms, and speedup techniques, and we discuss resources such as benchmarks, best practices, other surveys, and open-source libraries.
Neural Architecture Search for Dense Prediction Tasks in Computer Vision
Feb 15, 2022The success of deep learning in recent years has lead to a rising demand for neural network architecture engineering. As a consequence, neural architecture search (NAS), which aims at automatically designing neural network architectures in a data-driven manner rather than manually, has evolved as a popular field of research. With the advent of weight sharing strategies across architectures, NAS has become applicable to a much wider range of problems. In particular, there are now many publications for dense prediction tasks in computer vision that require pixel-level predictions, such as semantic segmentation or object detection. These tasks come with novel challenges, such as higher memory footprints due to high-resolution data, learning multi-scale representations, longer training times, and more complex and larger neural architectures. In this manuscript, we provide an overview of NAS for dense prediction tasks by elaborating on these novel challenges and surveying ways to address them to ease future research and application of existing methods to novel problems.
Bag of Tricks for Neural Architecture Search
Jul 08, 2021While neural architecture search methods have been successful in previous years and led to new state-of-the-art performance on various problems, they have also been criticized for being unstable, being highly sensitive with respect to their hyperparameters, and often not performing better than random search. To shed some light on this issue, we discuss some practical considerations that help improve the stability, efficiency and overall performance.
Bag of Baselines for Multi-objective Joint Neural Architecture Search and Hyperparameter Optimization
May 03, 2021
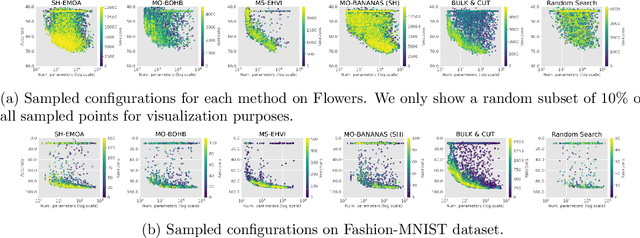
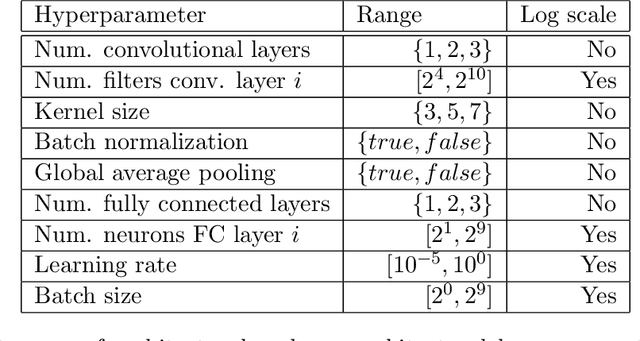
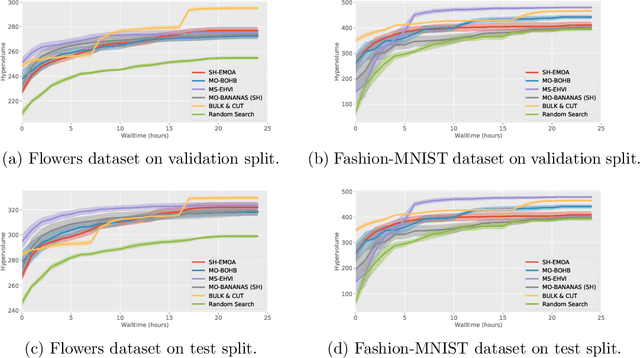
Neural architecture search (NAS) and hyperparameter optimization (HPO) make deep learning accessible to non-experts by automatically finding the architecture of the deep neural network to use and tuning the hyperparameters of the used training pipeline. While both NAS and HPO have been studied extensively in recent years, NAS methods typically assume fixed hyperparameters and vice versa - there exists little work on joint NAS + HPO. Furthermore, NAS has recently often been framed as a multi-objective optimization problem, in order to take, e.g., resource requirements into account. In this paper, we propose a set of methods that extend current approaches to jointly optimize neural architectures and hyperparameters with respect to multiple objectives. We hope that these methods will serve as simple baselines for future research on multi-objective joint NAS + HPO. To facilitate this, all our code is available at https://github.com/automl/multi-obj-baselines.
Neural Ensemble Search for Performant and Calibrated Predictions
Jun 15, 2020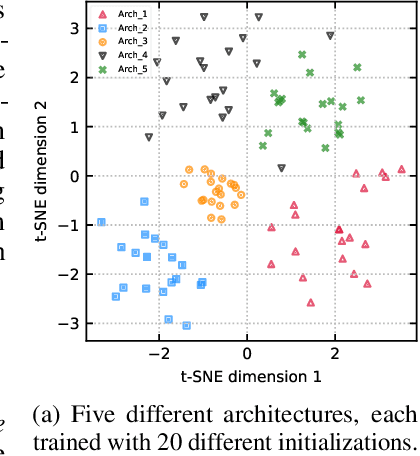
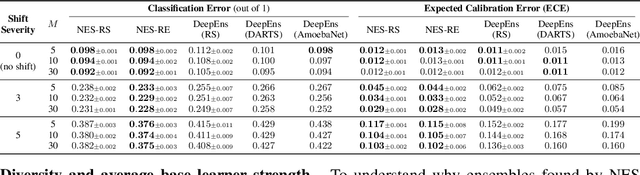


Ensembles of neural networks achieve superior performance compared to stand-alone networks not only in terms of accuracy on in-distribution data but also on data with distributional shift alongside improved uncertainty calibration. Diversity among networks in an ensemble is believed to be key for building strong ensembles, but typical approaches only ensemble different weight vectors of a fixed architecture. Instead, we investigate neural architecture search (NAS) for explicitly constructing ensembles to exploit diversity among networks of varying architectures and to achieve robustness against distributional shift. By directly optimizing ensemble performance, our methods implicitly encourage diversity among networks, without the need to explicitly define diversity. We find that the resulting ensembles are more diverse compared to ensembles composed of a fixed architecture and are therefore also more powerful. We show significant improvements in ensemble performance on image classification tasks both for in-distribution data and during distributional shift with better uncertainty calibration.
Meta-Learning of Neural Architectures for Few-Shot Learning
Nov 25, 2019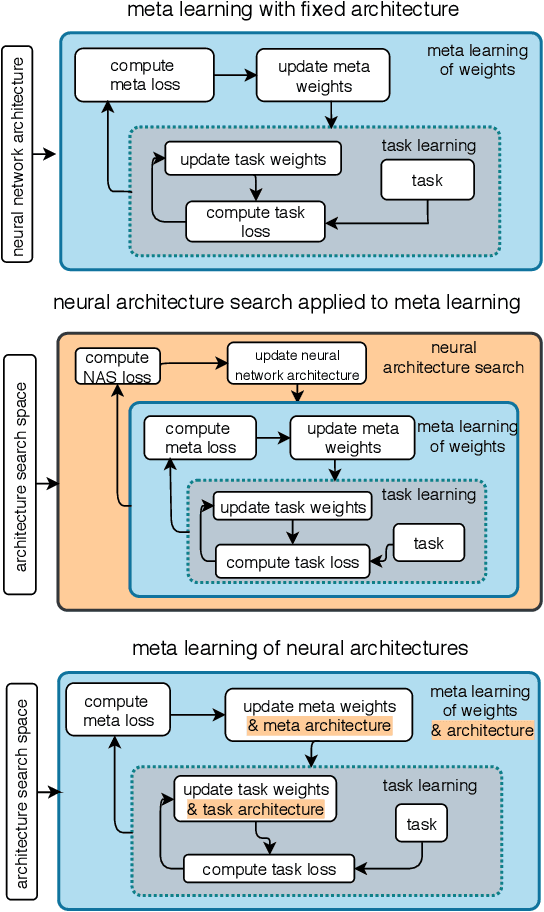
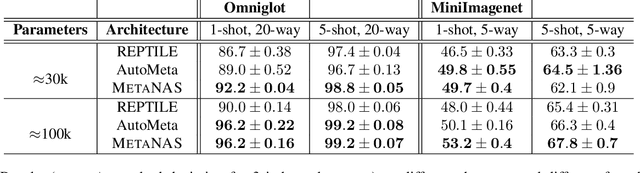
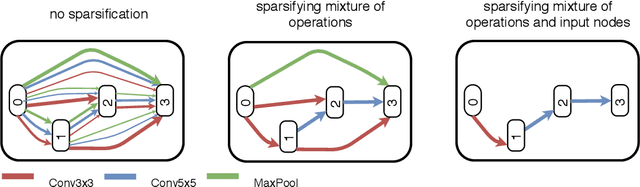
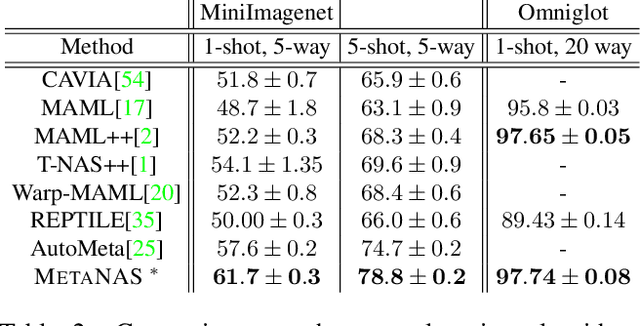
The recent progress in neural architectures search (NAS) has allowed scaling the automated design of neural architectures to real-world domains such as object detection and semantic segmentation. However, one prerequisite for the application of NAS are large amounts of labeled data and compute resources. This renders its application challenging in few-shot learning scenarios, where many related tasks need to be learned, each with limited amounts of data and compute time. Thus, few-shot learning is typically done with a fixed neural architecture. To improve upon this, we propose MetaNAS, the first method which fully integrates NAS with gradient-based meta-learning. MetaNAS optimizes a meta-architecture along with the meta-weights during meta-training. During meta-testing, architectures can be adapted to a novel task with a few steps of the task optimizer, that is: task adaptation becomes computationally cheap and requires only little data per task. Moreover, MetaNAS is agnostic in that it can be used with arbitrary model-agnostic meta-learning algorithms and arbitrary gradient-based NAS methods. Empirical results on standard few-shot classification benchmarks show that MetaNAS with a combination of DARTS and REPTILE yields state-of-the-art results.
Automated design of error-resilient and hardware-efficient deep neural networks
Sep 30, 2019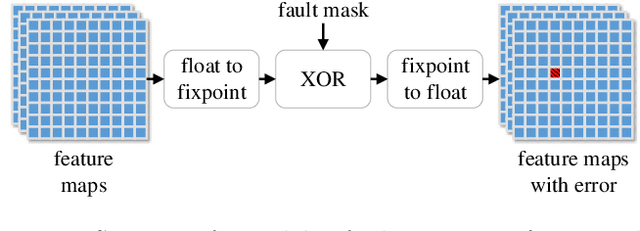
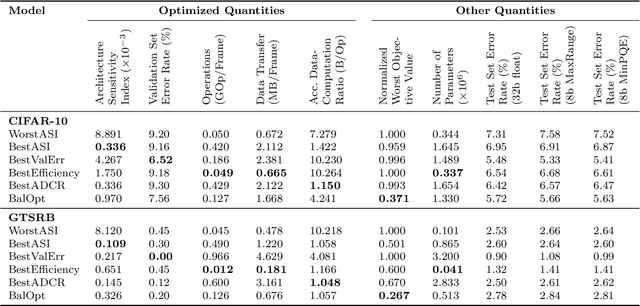
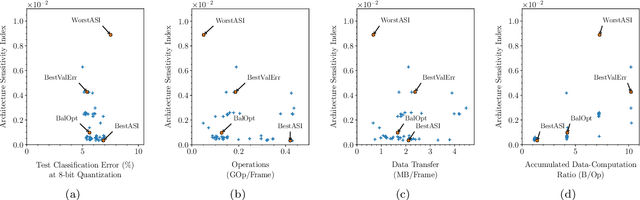
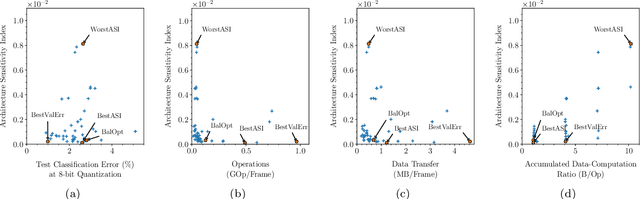
Applying deep neural networks (DNNs) in mobile and safety-critical systems, such as autonomous vehicles, demands a reliable and efficient execution on hardware. Optimized dedicated hardware accelerators are being developed to achieve this. However, the design of efficient and reliable hardware has become increasingly difficult, due to the increased complexity of modern integrated circuit technology and its sensitivity against hardware faults, such as random bit-flips. It is thus desirable to exploit optimization potential for error resilience and efficiency also at the algorithmic side, e.g., by optimizing the architecture of the DNN. Since there are numerous design choices for the architecture of DNNs, with partially opposing effects on the preferred characteristics (such as small error rates at low latency), multi-objective optimization strategies are necessary. In this paper, we develop an evolutionary optimization technique for the automated design of hardware-optimized DNN architectures. For this purpose, we derive a set of easily computable objective functions, which enable the fast evaluation of DNN architectures with respect to their hardware efficiency and error resilience solely based on the network topology. We observe a strong correlation between predicted error resilience and actual measurements obtained from fault injection simulations. Furthermore, we analyze two different quantization schemes for efficient DNN computation and find significant differences regarding their effect on error resilience.
Understanding and Robustifying Differentiable Architecture Search
Sep 20, 2019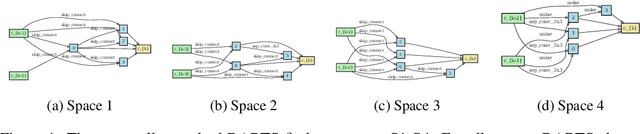
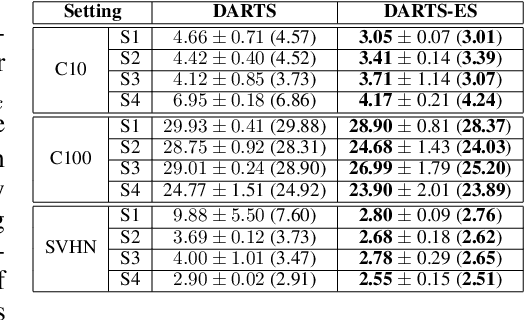
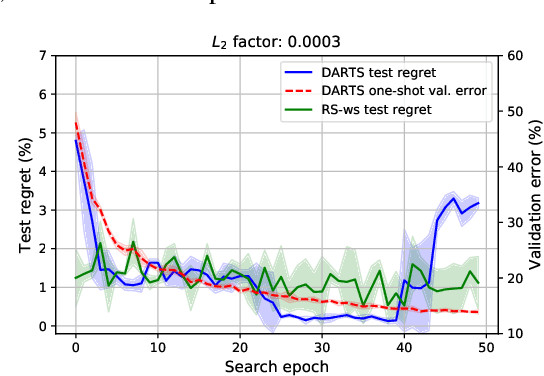
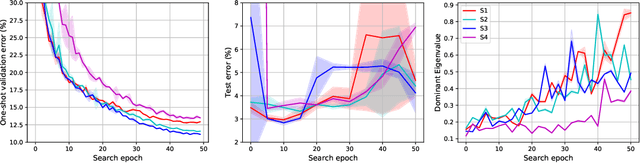
Differentiable Architecture Search (DARTS) has attracted a lot of attention due to its simplicity and small search costs achieved by a continuous relaxation and an approximation of the resulting bi-level optimization problem. However, DARTS does not work robustly for new problems: we identify a wide range of search spaces for which DARTS yields degenerate architectures with very poor test performance. We study this failure mode and show that, while DARTS successfully minimizes validation loss, the found solutions generalize poorly when they coincide with high validation loss curvature in the space of architectures. We show that by adding one of various types of regularization we can robustify DARTS to find solutions with smaller Hessian spectrum and with better generalization properties. Based on these observations we propose several simple variations of DARTS that perform substantially more robustly in practice. Our observations are robust across five search spaces on three image classification tasks and also hold for the very different domains of disparity estimation (a dense regression task) and language modelling. We provide our implementation and scripts to facilitate reproducibility.
Neural Architecture Search: A Survey
Sep 05, 2018
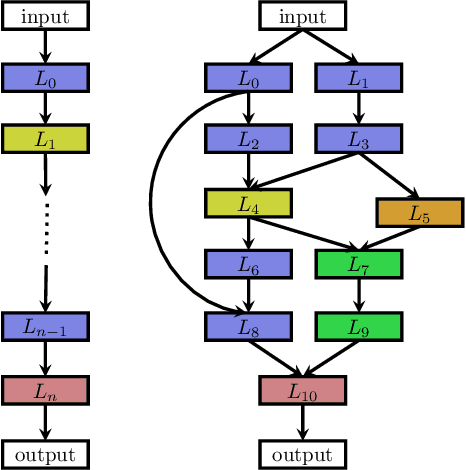
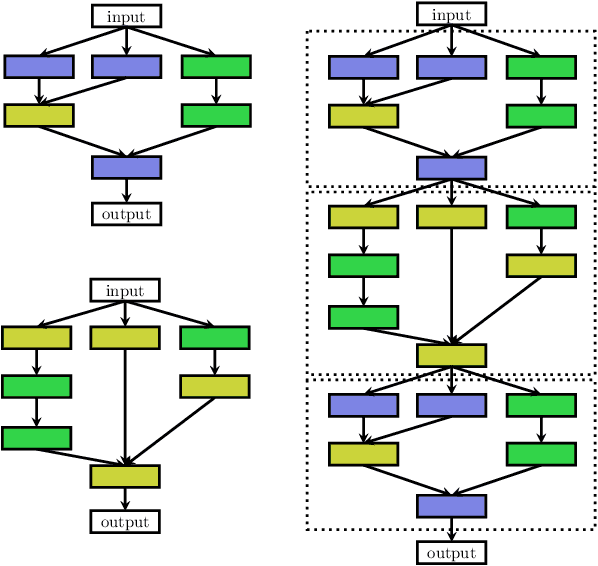
Deep Learning has enabled remarkable progress over the last years on a variety of tasks, such as image recognition, speech recognition, and machine translation. One crucial aspect for this progress are novel neural architectures. Currently employed architectures have mostly been developed manually by human experts, which is a time-consuming and error-prone process. Because of this, there is growing interest in automated neural architecture search methods. We provide an overview of existing work in this field of research and categorize them according to three dimensions: search space, search strategy, and performance estimation strategy.
Efficient Multi-objective Neural Architecture Search via Lamarckian Evolution
Jul 24, 2018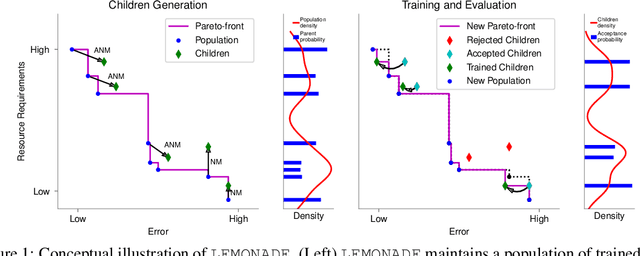
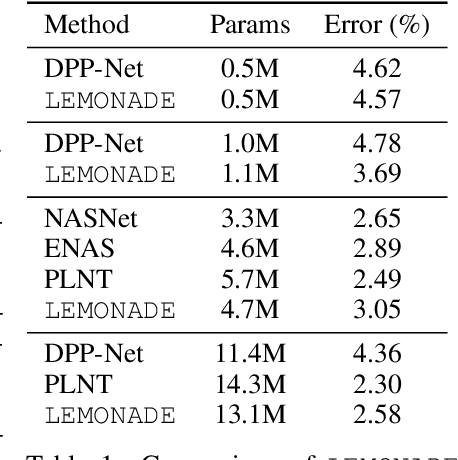
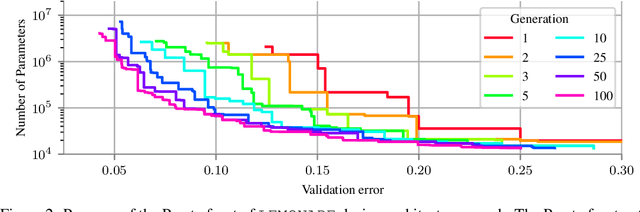

Architecture search aims at automatically finding neural architectures that are competitive with architectures designed by human experts. While recent approaches have achieved state-of-the-art predictive performance for image recognition, they are problematic under resource constraints for two reasons: (1) the neural architectures found are solely optimized for high predictive performance, without penalizing excessive resource consumption; (2) most architecture search methods require vast computational resources. We address the first shortcoming by proposing LEMONADE, an evolutionary algorithm for multi-objective architecture search that allows approximating the Pareto-front of architectures under multiple objectives, such as predictive performance and number of parameters, in a single run of the method. We address the second shortcoming by proposing a Lamarckian inheritance mechanism for LEMONADE which generates children networks that are warmstarted with the predictive performance of their trained parents. This is accomplished by using (approximate) network morphism operators for generating children. The combination of these two contributions allows finding models that are on par or even outperform different-sized NASNets, MobileNets, MobileNets V2 and Wide Residual Networks on CIFAR-10 and ImageNet64x64 within only one week on eight GPUs, which is about 20-40x less compute power than previous architecture search methods that yield state-of-the-art performance.