 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFault Injectors for TensorFlow: Evaluation of the Impact of Random Hardware Faults on Deep CNNs
Dec 13, 2020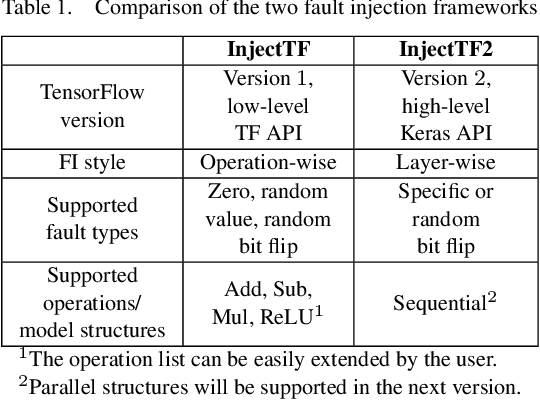
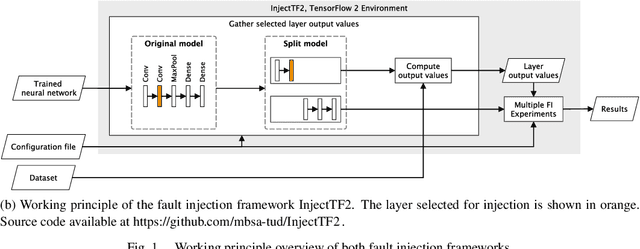
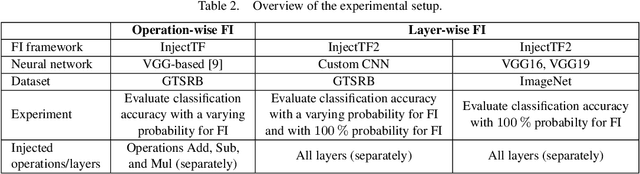
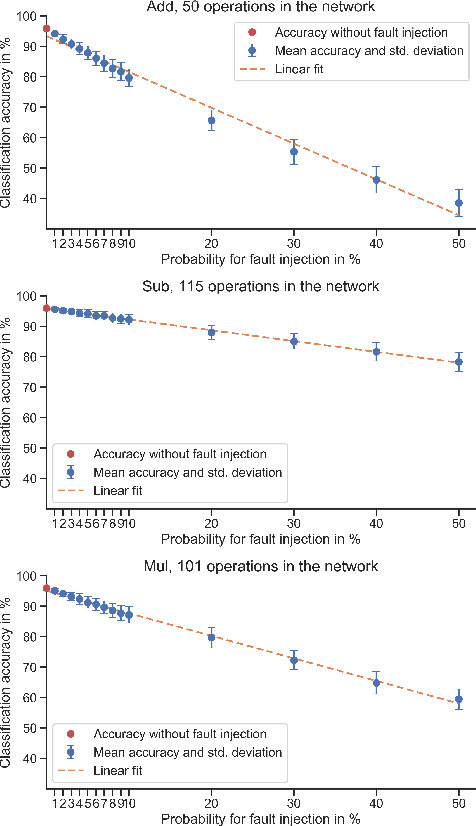
Today, Deep Learning (DL) enhances almost every industrial sector, including safety-critical areas. The next generation of safety standards will define appropriate verification techniques for DL-based applications and propose adequate fault tolerance mechanisms. DL-based applications, like any other software, are susceptible to common random hardware faults such as bit flips, which occur in RAM and CPU registers. Such faults can lead to silent data corruption. Therefore, it is crucial to develop methods and tools that help to evaluate how DL components operate under the presence of such faults. In this paper, we introduce two new Fault Injection (FI) frameworks InjectTF and InjectTF2 for TensorFlow 1 and TensorFlow 2, respectively. Both frameworks are available on GitHub and allow the configurable injection of random faults into Neural Networks (NN). In order to demonstrate the feasibility of the frameworks, we also present the results of FI experiments conducted on four VGG-based Convolutional NNs using two image sets. The results demonstrate how random bit flips in the output of particular mathematical operations and layers of NNs affect the classification accuracy. These results help to identify the most critical operations and layers, compare the reliability characteristics of functionally similar NNs, and introduce selective fault tolerance mechanisms.
SELD-TCN: Sound Event Localization & Detection via Temporal Convolutional Networks
Mar 03, 2020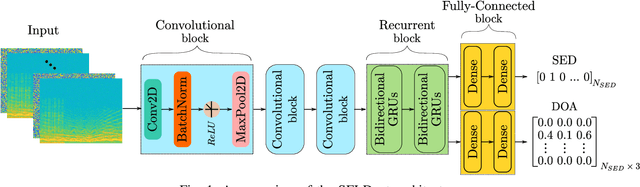
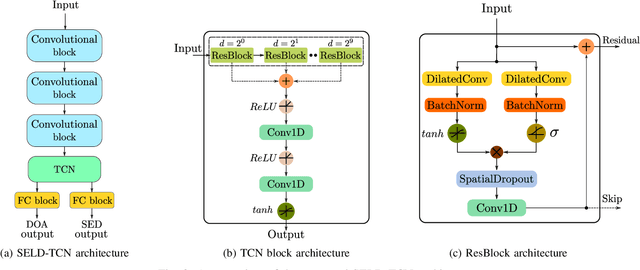
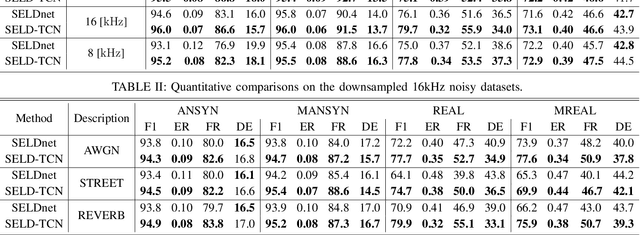
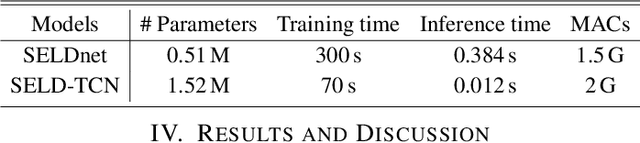
The understanding of the surrounding environment plays a critical role in autonomous robotic systems, such as self-driving cars. Extensive research has been carried out concerning visual perception. Yet, to obtain a more complete perception of the environment, autonomous systems of the future should also take acoustic information into account. Recent sound event localization and detection (SELD) frameworks utilize convolutional recurrent neural networks (CRNNs). However, considering the recurrent nature of CRNNs, it becomes challenging to implement them efficiently on embedded hardware. Not only are their computations strenuous to parallelize, but they also require high memory bandwidth and large memory buffers. In this work, we develop a more robust and hardware-friendly novel architecture based on a temporal convolutional network(TCN). The proposed framework (SELD-TCN) outperforms the state-of-the-art SELDnet performance on four different datasets. Moreover, SELD-TCN achieves 4x faster training time per epoch and 40x faster inference time on an ordinary graphics processing unit (GPU).
Automated design of error-resilient and hardware-efficient deep neural networks
Sep 30, 2019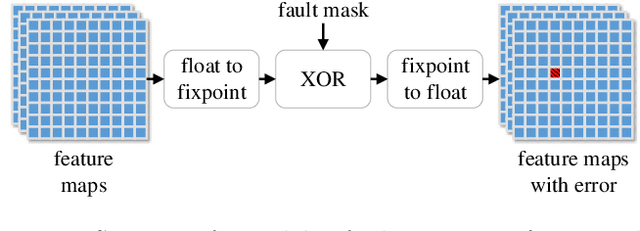
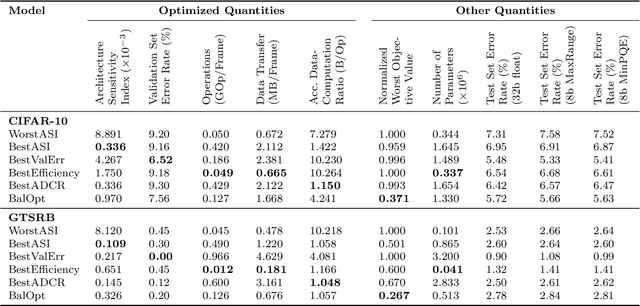
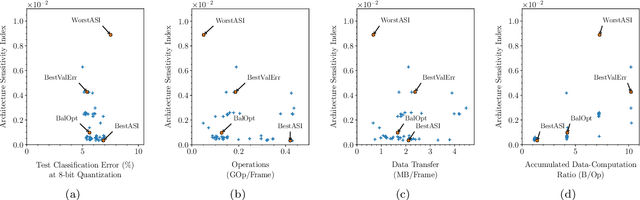
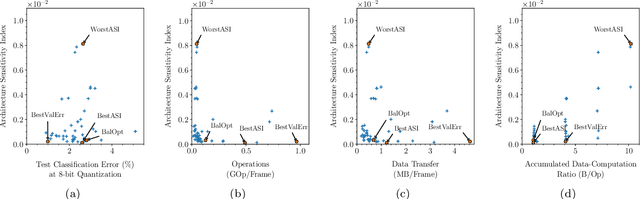
Applying deep neural networks (DNNs) in mobile and safety-critical systems, such as autonomous vehicles, demands a reliable and efficient execution on hardware. Optimized dedicated hardware accelerators are being developed to achieve this. However, the design of efficient and reliable hardware has become increasingly difficult, due to the increased complexity of modern integrated circuit technology and its sensitivity against hardware faults, such as random bit-flips. It is thus desirable to exploit optimization potential for error resilience and efficiency also at the algorithmic side, e.g., by optimizing the architecture of the DNN. Since there are numerous design choices for the architecture of DNNs, with partially opposing effects on the preferred characteristics (such as small error rates at low latency), multi-objective optimization strategies are necessary. In this paper, we develop an evolutionary optimization technique for the automated design of hardware-optimized DNN architectures. For this purpose, we derive a set of easily computable objective functions, which enable the fast evaluation of DNN architectures with respect to their hardware efficiency and error resilience solely based on the network topology. We observe a strong correlation between predicted error resilience and actual measurements obtained from fault injection simulations. Furthermore, we analyze two different quantization schemes for efficient DNN computation and find significant differences regarding their effect on error resilience.
Efficient Stochastic Inference of Bitwise Deep Neural Networks
Nov 20, 2016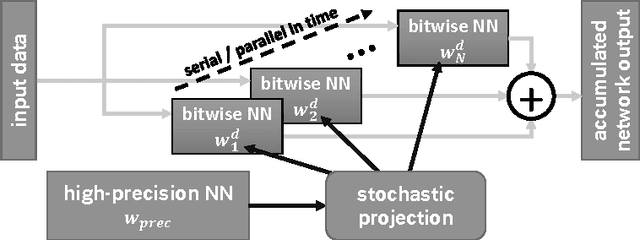
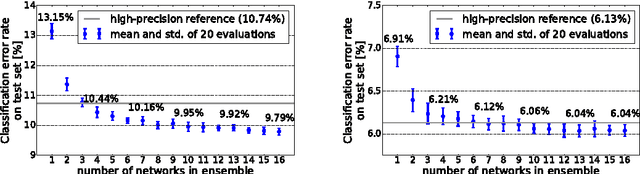
Recently published methods enable training of bitwise neural networks which allow reduced representation of down to a single bit per weight. We present a method that exploits ensemble decisions based on multiple stochastically sampled network models to increase performance figures of bitwise neural networks in terms of classification accuracy at inference. Our experiments with the CIFAR-10 and GTSRB datasets show that the performance of such network ensembles surpasses the performance of the high-precision base model. With this technique we achieve 5.81% best classification error on CIFAR-10 test set using bitwise networks. Concerning inference on embedded systems we evaluate these bitwise networks using a hardware efficient stochastic rounding procedure. Our work contributes to efficient embedded bitwise neural networks.