 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBosch Deep Learning Hardware Benchmark
Aug 24, 2020

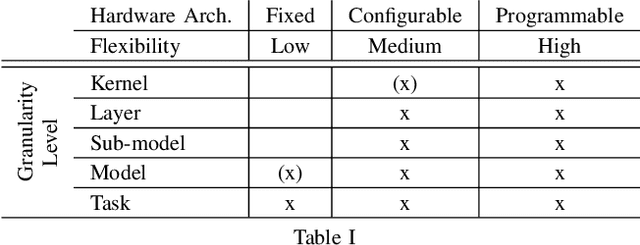

The widespread use of Deep Learning (DL) applications in science and industry has created a large demand for efficient inference systems. This has resulted in a rapid increase of available Hardware Accelerators (HWAs) making comparison challenging and laborious. To address this, several DL hardware benchmarks have been proposed aiming at a comprehensive comparison for many models, tasks, and hardware platforms. Here, we present our DL hardware benchmark which has been specifically developed for inference on embedded HWAs and tasks required for autonomous driving. In addition to previous benchmarks, we propose a new granularity level to evaluate common submodules of DL models, a twofold benchmark procedure that accounts for hardware and model optimizations done by HWA manufacturers, and an extended set of performance indicators that can help to identify a mismatch between a HWA and the DL models used in our benchmark.
Automated design of error-resilient and hardware-efficient deep neural networks
Sep 30, 2019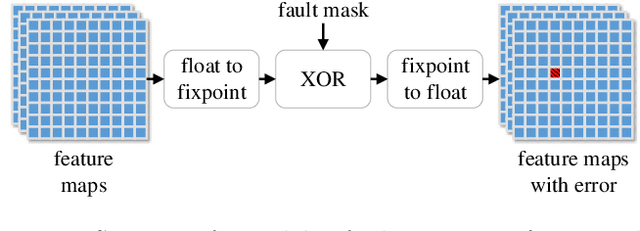
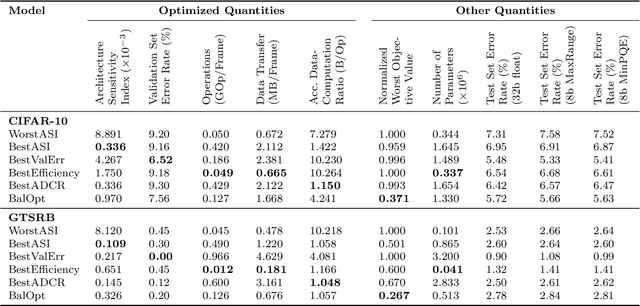
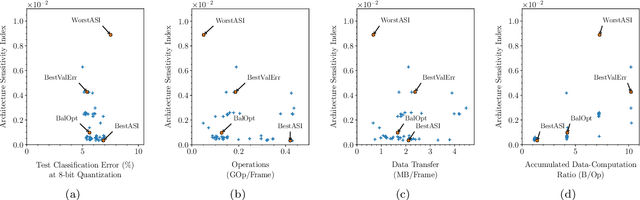
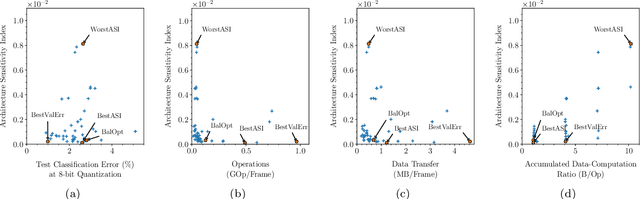
Applying deep neural networks (DNNs) in mobile and safety-critical systems, such as autonomous vehicles, demands a reliable and efficient execution on hardware. Optimized dedicated hardware accelerators are being developed to achieve this. However, the design of efficient and reliable hardware has become increasingly difficult, due to the increased complexity of modern integrated circuit technology and its sensitivity against hardware faults, such as random bit-flips. It is thus desirable to exploit optimization potential for error resilience and efficiency also at the algorithmic side, e.g., by optimizing the architecture of the DNN. Since there are numerous design choices for the architecture of DNNs, with partially opposing effects on the preferred characteristics (such as small error rates at low latency), multi-objective optimization strategies are necessary. In this paper, we develop an evolutionary optimization technique for the automated design of hardware-optimized DNN architectures. For this purpose, we derive a set of easily computable objective functions, which enable the fast evaluation of DNN architectures with respect to their hardware efficiency and error resilience solely based on the network topology. We observe a strong correlation between predicted error resilience and actual measurements obtained from fault injection simulations. Furthermore, we analyze two different quantization schemes for efficient DNN computation and find significant differences regarding their effect on error resilience.