 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAWADA: Attention-Weighted Adversarial Domain Adaptation for Object Detection
Aug 31, 2022
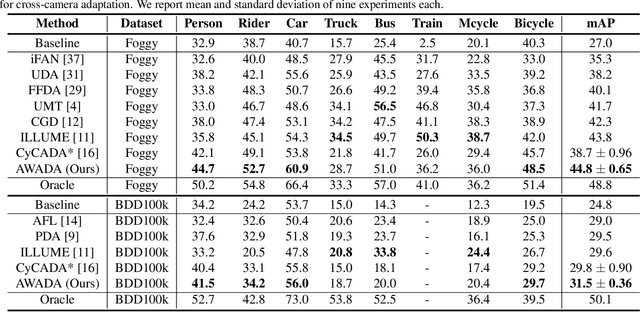
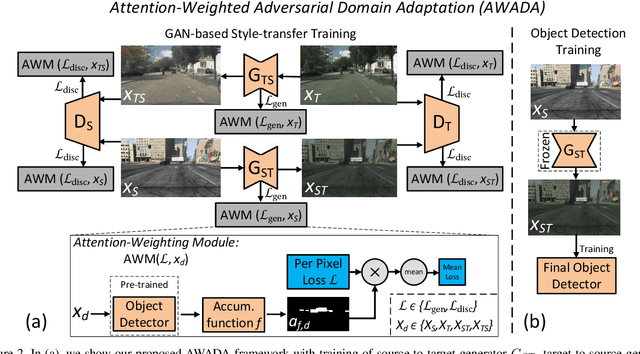
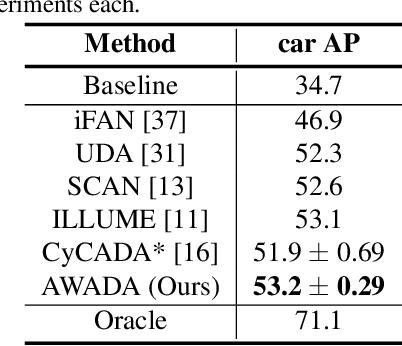
Object detection networks have reached an impressive performance level, yet a lack of suitable data in specific applications often limits it in practice. Typically, additional data sources are utilized to support the training task. In these, however, domain gaps between different data sources pose a challenge in deep learning. GAN-based image-to-image style-transfer is commonly applied to shrink the domain gap, but is unstable and decoupled from the object detection task. We propose AWADA, an Attention-Weighted Adversarial Domain Adaptation framework for creating a feedback loop between style-transformation and detection task. By constructing foreground object attention maps from object detector proposals, we focus the transformation on foreground object regions and stabilize style-transfer training. In extensive experiments and ablation studies, we show that AWADA reaches state-of-the-art unsupervised domain adaptation object detection performance in the commonly used benchmarks for tasks such as synthetic-to-real, adverse weather and cross-camera adaptation.
Bosch Deep Learning Hardware Benchmark
Aug 24, 2020

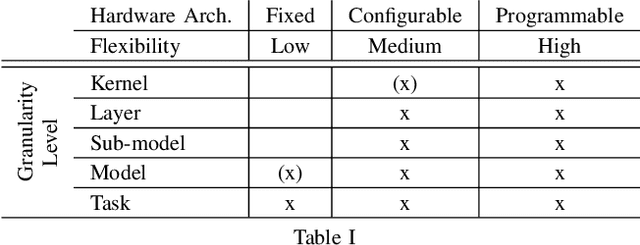

The widespread use of Deep Learning (DL) applications in science and industry has created a large demand for efficient inference systems. This has resulted in a rapid increase of available Hardware Accelerators (HWAs) making comparison challenging and laborious. To address this, several DL hardware benchmarks have been proposed aiming at a comprehensive comparison for many models, tasks, and hardware platforms. Here, we present our DL hardware benchmark which has been specifically developed for inference on embedded HWAs and tasks required for autonomous driving. In addition to previous benchmarks, we propose a new granularity level to evaluate common submodules of DL models, a twofold benchmark procedure that accounts for hardware and model optimizations done by HWA manufacturers, and an extended set of performance indicators that can help to identify a mismatch between a HWA and the DL models used in our benchmark.