 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Framework for Knowledge Integrated Evolutionary Algorithms
Mar 31, 2021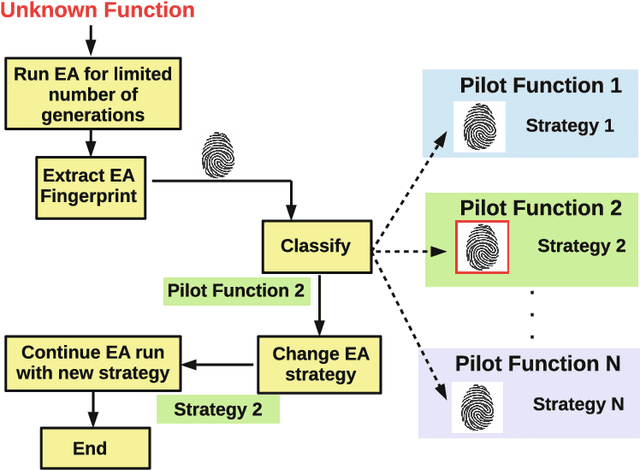

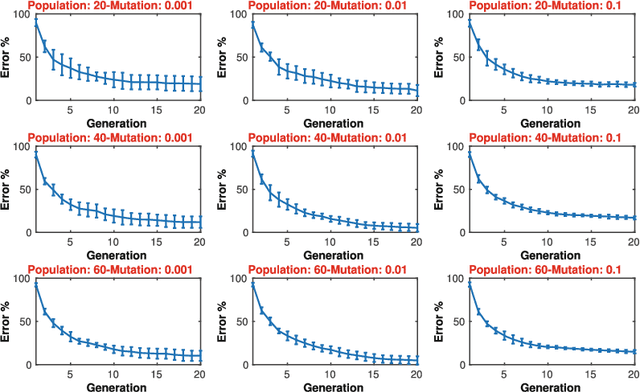
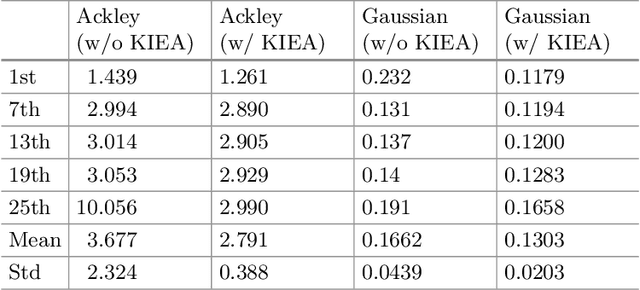
One of the main reasons for the success of Evolutionary Algorithms (EAs) is their general-purposeness, i.e., the fact that they can be applied straightforwardly to a broad range of optimization problems, without any specific prior knowledge. On the other hand, it has been shown that incorporating a priori knowledge, such as expert knowledge or empirical findings, can significantly improve the performance of an EA. However, integrating knowledge in EAs poses numerous challenges. It is often the case that the features of the search space are unknown, hence any knowledge associated with the search space properties can be hardly used. In addition, a priori knowledge is typically problem-specific and hard to generalize. In this paper, we propose a framework, called Knowledge Integrated Evolutionary Algorithm (KIEA), which facilitates the integration of existing knowledge into EAs. Notably, the KIEA framework is EA-agnostic (i.e., it works with any evolutionary algorithm), problem-independent (i.e., it is not dedicated to a specific type of problems), expandable (i.e., its knowledge base can grow over time). Furthermore, the framework integrates knowledge while the EA is running, thus optimizing the use of the needed computational power. In the preliminary experiments shown here, we observe that the KIEA framework produces in the worst case an 80% improvement on the converge time, w.r.t. the corresponding "knowledge-free" EA counterpart.
An Adaptive Multi-Agent Physical Layer Security Framework for Cognitive Cyber-Physical Systems
Jan 07, 2021
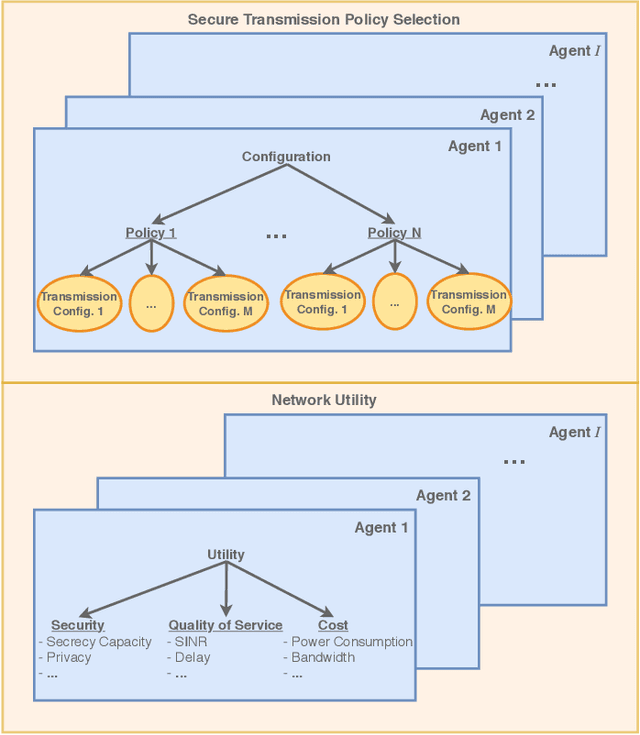
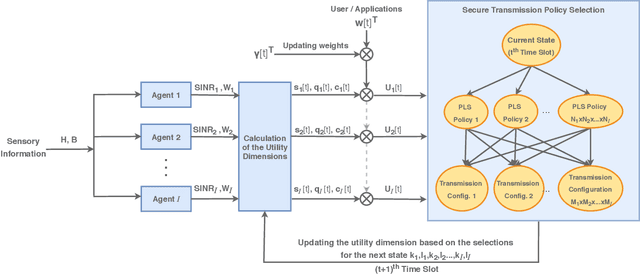
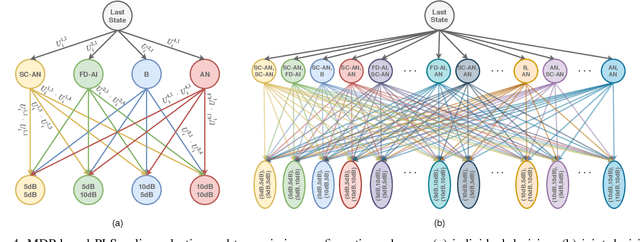
Being capable of sensing and behavioral adaptation in line with their changing environments, cognitive cyber-physical systems (CCPSs) are the new form of applications in future wireless networks. With the advancement of the machine learning algorithms, the transmission scheme providing the best performance can be utilized to sustain a reliable network of CCPS agents equipped with self-decision mechanisms, where the interactions between each agent are modeled in terms of service quality, security, and cost dimensions. In this work, first, we provide network utility as a reliability metric, which is a weighted sum of the individual utility values of the CCPS agents. The individual utilities are calculated by mixing the quality of service (QoS), security, and cost dimensions with the proportions determined by the individualized user requirements. By changing the proportions, the CCPS network can be tuned for different applications of next-generation wireless networks. Then, we propose a secure transmission policy selection (STPS) mechanism that maximizes the network utility by using the Markov-decision process (MDP). In STPS, the CCPS network jointly selects the best performing physical layer security policy and the parameters of the selected secure transmission policy to adapt to the changing environmental effects. The proposed STPS is realized by reinforcement learning (RL), considering its real-time decision mechanism where agents can decide automatically the best utility providing policy in an altering environment.
EVO-RL: Evolutionary-Driven Reinforcement Learning
Jul 10, 2020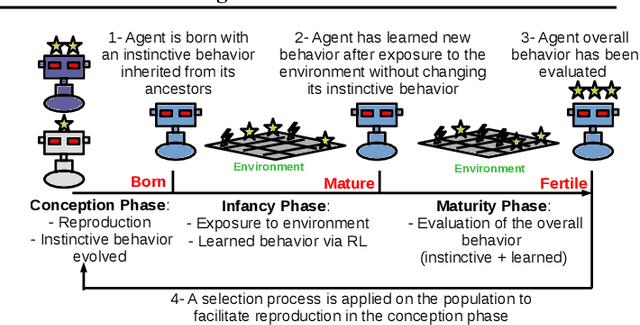
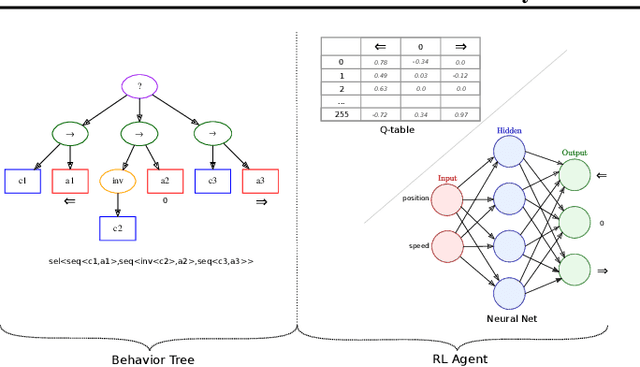
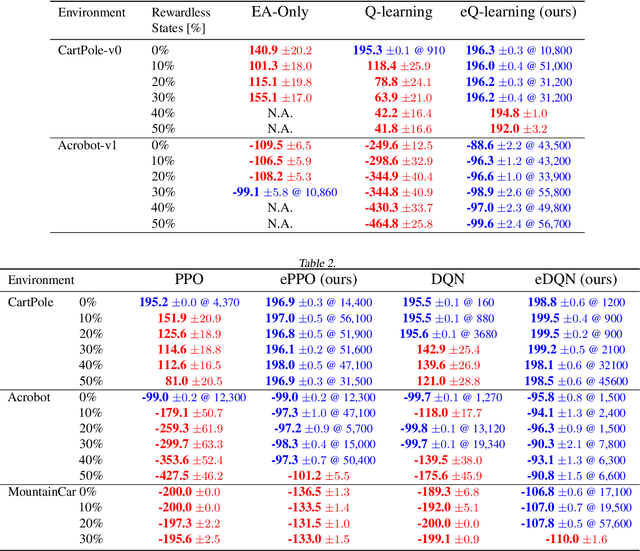
In this work, we propose a novel approach for reinforcement learning driven by evolutionary computation. Our algorithm, dubbed as Evolutionary-Driven Reinforcement Learning (evo-RL), embeds the reinforcement learning algorithm in an evolutionary cycle, where we distinctly differentiate between purely evolvable (instinctive) behaviour versus purely learnable behaviour. Furthermore, we propose that this distinction is decided by the evolutionary process, thus allowing evo-RL to be adaptive to different environments. In addition, evo-RL facilitates learning on environments with rewardless states, which makes it more suited for real-world problems with incomplete information. To show that evo-RL leads to state-of-the-art performance, we present the performance of different state-of-the-art reinforcement learning algorithms when operating within evo-RL and compare it with the case when these same algorithms are executed independently. Results show that reinforcement learning algorithms embedded within our evo-RL approach significantly outperform the stand-alone versions of the same RL algorithms on OpenAI Gym control problems with rewardless states constrained by the same computational budget.
Dataflow Aware Mapping of Convolutional Neural Networks Onto Many-Core Platforms With Network-on-Chip Interconnect
Jun 18, 2020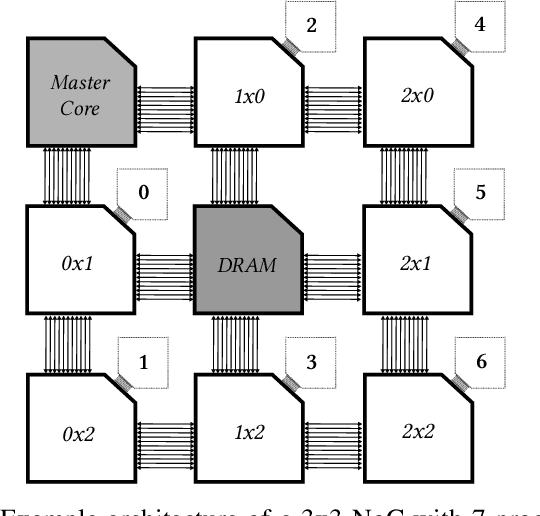
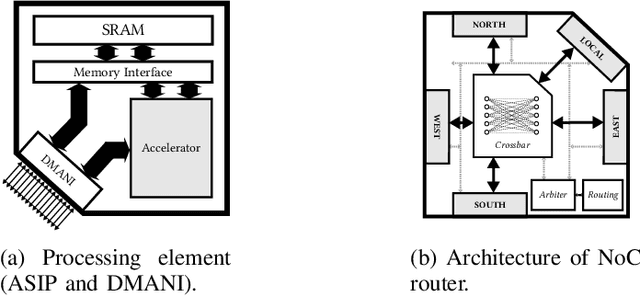
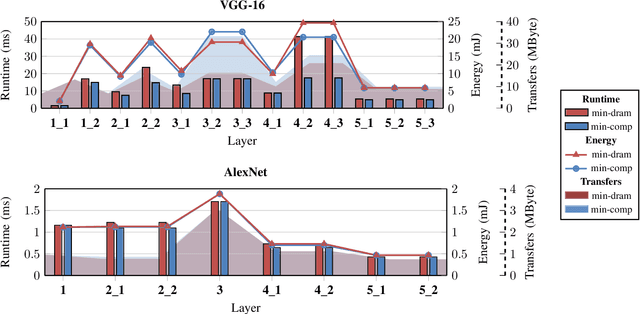
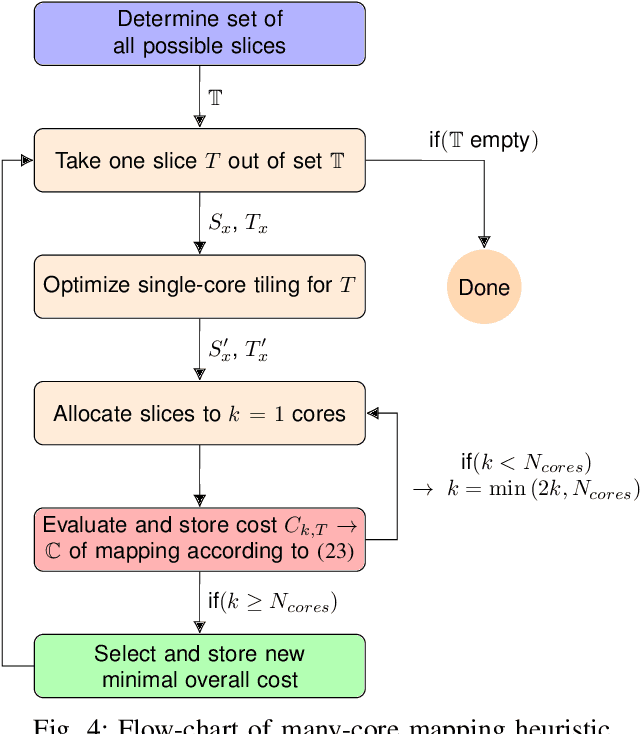
Machine intelligence, especially using convolutional neural networks (CNNs), has become a large area of research over the past years. Increasingly sophisticated hardware accelerators are proposed that exploit e.g. the sparsity in computations and make use of reduced precision arithmetic to scale down the energy consumption. However, future platforms require more than just energy efficiency: Scalability is becoming an increasingly important factor. The required effort for physical implementation grows with the size of the accelerator making it more difficult to meet target constraints. Using many-core platforms consisting of several homogeneous cores can alleviate the aforementioned limitations with regard to physical implementation at the expense of an increased dataflow mapping effort. While the dataflow in CNNs is deterministic and can therefore be optimized offline, the problem of finding a suitable scheme that minimizes both runtime and off-chip memory accesses is a challenging task which becomes even more complex if an interconnect system is involved. This work presents an automated mapping strategy starting at the single-core level with different optimization targets for minimal runtime and minimal off-chip memory accesses. The strategy is then extended towards a suitable many-core mapping scheme and evaluated using a scalable system-level simulation with a network-on-chip interconnect. Design space exploration is performed by mapping the well-known CNNs AlexNet and VGG-16 to platforms of different core counts and computational power per core in order to investigate the trade-offs. Our mapping strategy and system setup is scaled starting from the single core level up to 128 cores, thereby showing the limits of the selected approach.
Automated design of error-resilient and hardware-efficient deep neural networks
Sep 30, 2019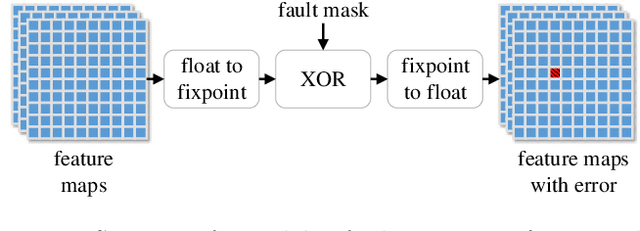
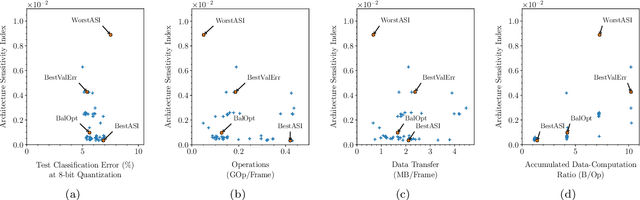
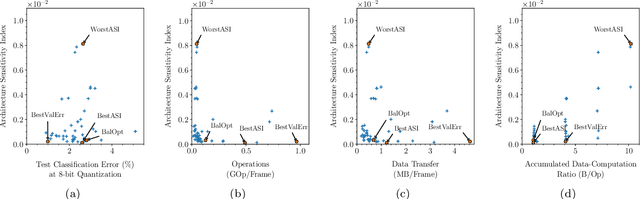
Applying deep neural networks (DNNs) in mobile and safety-critical systems, such as autonomous vehicles, demands a reliable and efficient execution on hardware. Optimized dedicated hardware accelerators are being developed to achieve this. However, the design of efficient and reliable hardware has become increasingly difficult, due to the increased complexity of modern integrated circuit technology and its sensitivity against hardware faults, such as random bit-flips. It is thus desirable to exploit optimization potential for error resilience and efficiency also at the algorithmic side, e.g., by optimizing the architecture of the DNN. Since there are numerous design choices for the architecture of DNNs, with partially opposing effects on the preferred characteristics (such as small error rates at low latency), multi-objective optimization strategies are necessary. In this paper, we develop an evolutionary optimization technique for the automated design of hardware-optimized DNN architectures. For this purpose, we derive a set of easily computable objective functions, which enable the fast evaluation of DNN architectures with respect to their hardware efficiency and error resilience solely based on the network topology. We observe a strong correlation between predicted error resilience and actual measurements obtained from fault injection simulations. Furthermore, we analyze two different quantization schemes for efficient DNN computation and find significant differences regarding their effect on error resilience.
An Application-Specific VLIW Processor with Vector Instruction Set for CNN Acceleration
Apr 10, 2019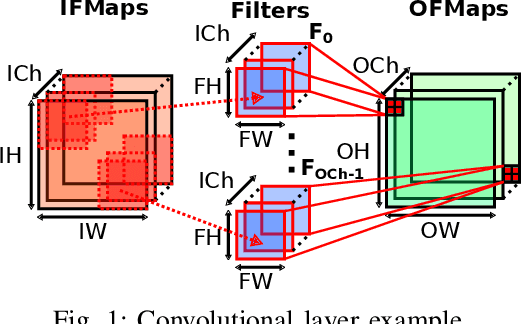


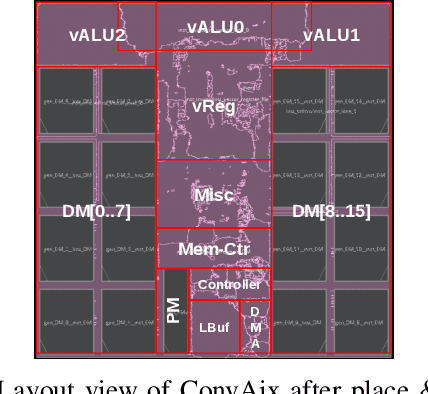
In recent years, neural networks have surpassed classical algorithms in areas such as object recognition, e.g. in the well-known ImageNet challenge. As a result, great effort is being put into developing fast and efficient accelerators, especially for Convolutional Neural Networks (CNNs). In this work we present ConvAix, a fully C-programmable processor, which -- contrary to many existing architectures -- does not rely on a hard-wired array of multiply-and-accumulate (MAC) units. Instead it maps computations onto independent vector lanes making use of a carefully designed vector instruction set. The presented processor is targeted towards latency-sensitive applications and is capable of executing up to 192 MAC operations per cycle. ConvAix operates at a target clock frequency of 400 MHz in 28nm CMOS, thereby offering state-of-the-art performance with proper flexibility within its target domain. Simulation results for several 2D convolutional layers from well known CNNs (AlexNet, VGG-16) show an average ALU utilization of 72.5% using vector instructions with 16 bit fixed-point arithmetic. Compared to other well-known designs which are less flexible, ConvAix offers competitive energy efficiency of up to 497 GOP/s/W while even surpassing them in terms of area efficiency and processing speed.
Efficient Stochastic Inference of Bitwise Deep Neural Networks
Nov 20, 2016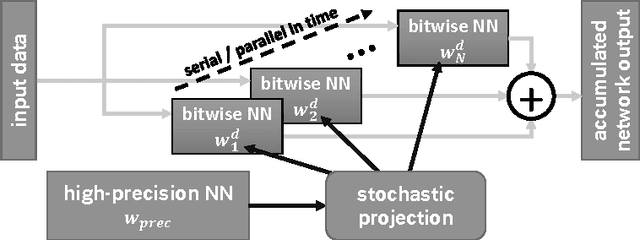
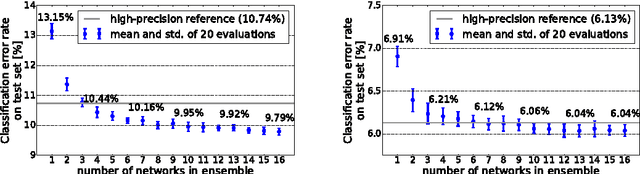
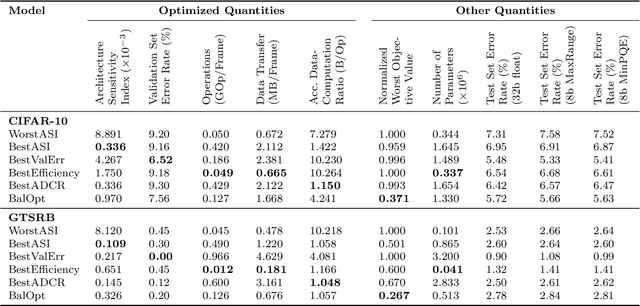
Recently published methods enable training of bitwise neural networks which allow reduced representation of down to a single bit per weight. We present a method that exploits ensemble decisions based on multiple stochastically sampled network models to increase performance figures of bitwise neural networks in terms of classification accuracy at inference. Our experiments with the CIFAR-10 and GTSRB datasets show that the performance of such network ensembles surpasses the performance of the high-precision base model. With this technique we achieve 5.81% best classification error on CIFAR-10 test set using bitwise networks. Concerning inference on embedded systems we evaluate these bitwise networks using a hardware efficient stochastic rounding procedure. Our work contributes to efficient embedded bitwise neural networks.