 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixed-Precision Training and Compilation for RRAM-based Computing-in-Memory Accelerators
Jan 29, 2026Computing-in-Memory (CIM) accelerators are a promising solution for accelerating Machine Learning (ML) workloads, as they perform Matrix-Vector Multiplications (MVMs) on crossbar arrays directly in memory. Although the bit widths of the crossbar inputs and cells are very limited, most CIM compilers do not support quantization below 8 bit. As a result, a single MVM requires many compute cycles, and weights cannot be efficiently stored in a single crossbar cell. To address this problem, we propose a mixed-precision training and compilation framework for CIM architectures. The biggest challenge is the massive search space, that makes it difficult to find good quantization parameters. This is why we introduce a reinforcement learning-based strategy to find suitable quantization configurations that balance latency and accuracy. In the best case, our approach achieves up to a 2.48x speedup over existing state-of-the-art solutions, with an accuracy loss of only 0.086 %.
Optimizing Binary and Ternary Neural Network Inference on RRAM Crossbars using CIM-Explorer
May 20, 2025Using Resistive Random Access Memory (RRAM) crossbars in Computing-in-Memory (CIM) architectures offers a promising solution to overcome the von Neumann bottleneck. Due to non-idealities like cell variability, RRAM crossbars are often operated in binary mode, utilizing only two states: Low Resistive State (LRS) and High Resistive State (HRS). Binary Neural Networks (BNNs) and Ternary Neural Networks (TNNs) are well-suited for this hardware due to their efficient mapping. Existing software projects for RRAM-based CIM typically focus on only one aspect: compilation, simulation, or Design Space Exploration (DSE). Moreover, they often rely on classical 8 bit quantization. To address these limitations, we introduce CIM-Explorer, a modular toolkit for optimizing BNN and TNN inference on RRAM crossbars. CIM-Explorer includes an end-to-end compiler stack, multiple mapping options, and simulators, enabling a DSE flow for accuracy estimation across different crossbar parameters and mappings. CIM-Explorer can accompany the entire design process, from early accuracy estimation for specific crossbar parameters, to selecting an appropriate mapping, and compiling BNNs and TNNs for a finalized crossbar chip. In DSE case studies, we demonstrate the expected accuracy for various mappings and crossbar parameters. CIM-Explorer can be found on GitHub.
Introducing Instruction-Accurate Simulators for Performance Estimation of Autotuning Workloads
May 19, 2025Accelerating Machine Learning (ML) workloads requires efficient methods due to their large optimization space. Autotuning has emerged as an effective approach for systematically evaluating variations of implementations. Traditionally, autotuning requires the workloads to be executed on the target hardware (HW). We present an interface that allows executing autotuning workloads on simulators. This approach offers high scalability when the availability of the target HW is limited, as many simulations can be run in parallel on any accessible HW. Additionally, we evaluate the feasibility of using fast instruction-accurate simulators for autotuning. We train various predictors to forecast the performance of ML workload implementations on the target HW based on simulation statistics. Our results demonstrate that the tuned predictors are highly effective. The best workload implementation in terms of actual run time on the target HW is always within the top 3 % of predictions for the tested x86, ARM, and RISC-V-based architectures. In the best case, this approach outperforms native execution on the target HW for embedded architectures when running as few as three samples on three simulators in parallel.
Evaluating the Scalability of Binary and Ternary CNN Workloads on RRAM-based Compute-in-Memory Accelerators
May 12, 2025The increasing computational demand of Convolutional Neural Networks (CNNs) necessitates energy-efficient acceleration strategies. Compute-in-Memory (CIM) architectures based on Resistive Random Access Memory (RRAM) offer a promising solution by reducing data movement and enabling low-power in-situ computations. However, their efficiency is limited by the high cost of peripheral circuits, particularly Analog-to-Digital Converters (ADCs). Large crossbars and low ADC resolutions are often used to mitigate this, potentially compromising accuracy. This work introduces novel simulation methods to model the impact of resistive wire parasitics and limited ADC resolution on RRAM crossbars. Our parasitics model employs a vectorised algorithm to compute crossbar output currents with errors below 0.15% compared to SPICE. Additionally, we propose a variable step-size ADC and a calibration methodology that significantly reduces ADC resolution requirements. These accuracy models are integrated with a statistics-based energy model. Using our framework, we conduct a comparative analysis of binary and ternary CNNs. Experimental results demonstrate that the ternary CNNs exhibit greater resilience to wire parasitics and lower ADC resolution but suffer a 40% reduction in energy efficiency. These findings provide valuable insights for optimising RRAM-based CIM accelerators for energy-efficient deep learning.
A Calibratable Model for Fast Energy Estimation of MVM Operations on RRAM Crossbars
May 07, 2024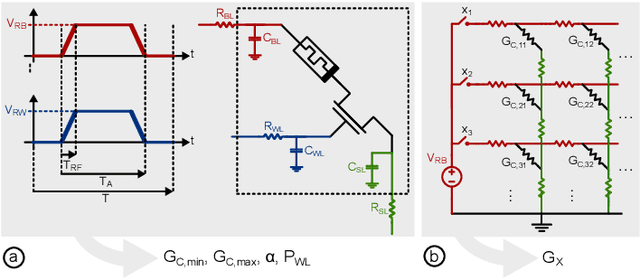
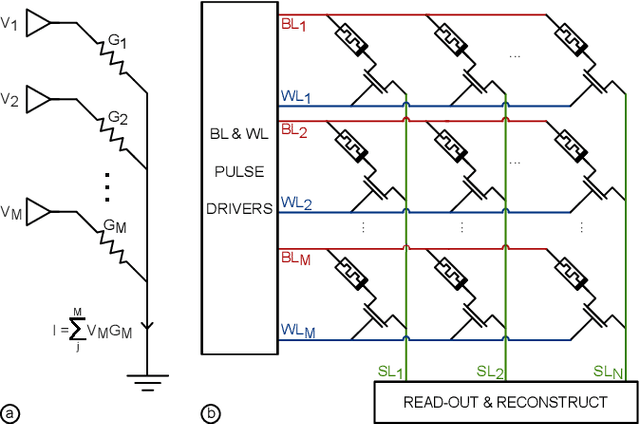
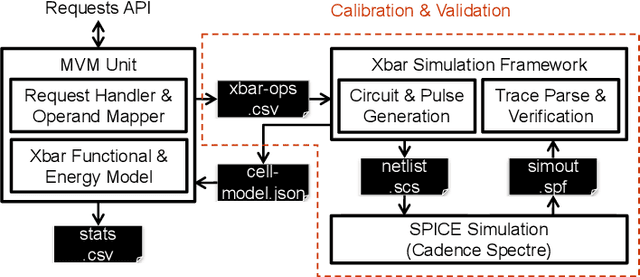
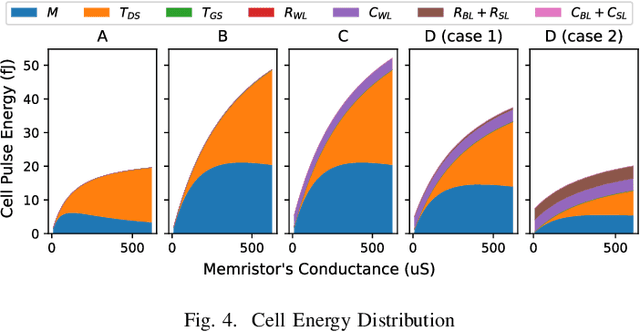
The surge in AI usage demands innovative power reduction strategies. Novel Compute-in-Memory (CIM) architectures, leveraging advanced memory technologies, hold the potential for significantly lowering energy consumption by integrating storage with parallel Matrix-Vector-Multiplications (MVMs). This study addresses the 1T1R RRAM crossbar, a core component in numerous CIM architectures. We introduce an abstract model and a calibration methodology for estimating operational energy. Our tool condenses circuit-level behaviour into a few parameters, facilitating energy assessments for DNN workloads. Validation against low-level SPICE simulations demonstrates speedups of up to 1000x and energy estimations with errors below 1%.
CLSA-CIM: A Cross-Layer Scheduling Approach for Computing-in-Memory Architectures
Jan 17, 2024



The demand for efficient machine learning (ML) accelerators is growing rapidly, driving the development of novel computing concepts such as resistive random access memory (RRAM)-based tiled computing-in-memory (CIM) architectures. CIM allows to compute within the memory unit, resulting in faster data processing and reduced power consumption. Efficient compiler algorithms are essential to exploit the potential of tiled CIM architectures. While conventional ML compilers focus on code generation for CPUs, GPUs, and other von Neumann architectures, adaptations are needed to cover CIM architectures. Cross-layer scheduling is a promising approach, as it enhances the utilization of CIM cores, thereby accelerating computations. Although similar concepts are implicitly used in previous work, there is a lack of clear and quantifiable algorithmic definitions for cross-layer scheduling for tiled CIM architectures. To close this gap, we present CLSA-CIM, a cross-layer scheduling algorithm for tiled CIM architectures. We integrate CLSA-CIM with existing weight-mapping strategies and compare performance against state-of-the-art (SOTA) scheduling algorithms. CLSA-CIM improves the utilization by up to 17.9 x , resulting in an overall speedup increase of up to 29.2 x compared to SOTA.
Logic Locking at the Frontiers of Machine Learning: A Survey on Developments and Opportunities
Jul 21, 2021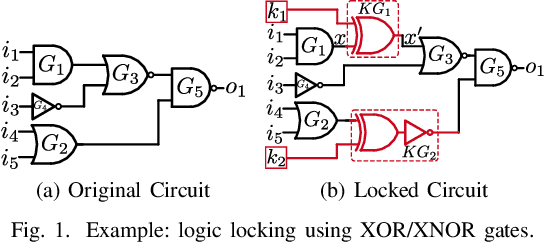



In the past decade, a lot of progress has been made in the design and evaluation of logic locking; a premier technique to safeguard the integrity of integrated circuits throughout the electronics supply chain. However, the widespread proliferation of machine learning has recently introduced a new pathway to evaluating logic locking schemes. This paper summarizes the recent developments in logic locking attacks and countermeasures at the frontiers of contemporary machine learning models. Based on the presented work, the key takeaways, opportunities, and challenges are highlighted to offer recommendations for the design of next-generation logic locking.
Deceptive Logic Locking for Hardware Integrity Protection against Machine Learning Attacks
Jul 19, 2021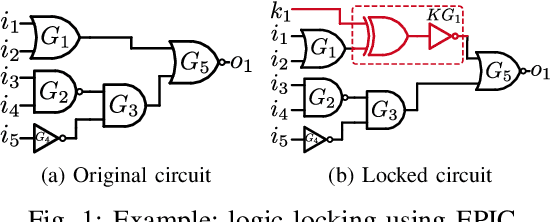

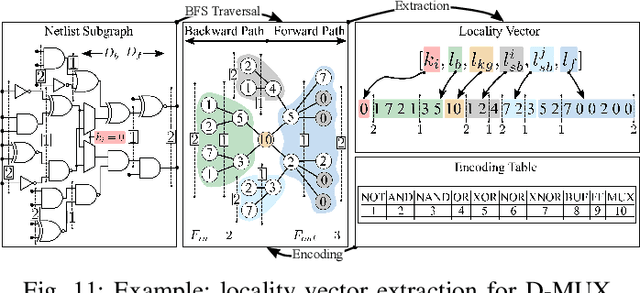
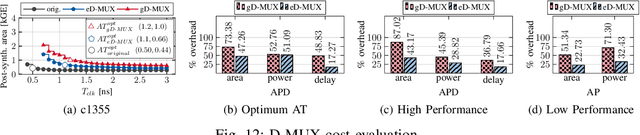
Logic locking has emerged as a prominent key-driven technique to protect the integrity of integrated circuits. However, novel machine-learning-based attacks have recently been introduced to challenge the security foundations of locking schemes. These attacks are able to recover a significant percentage of the key without having access to an activated circuit. This paper address this issue through two focal points. First, we present a theoretical model to test locking schemes for key-related structural leakage that can be exploited by machine learning. Second, based on the theoretical model, we introduce D-MUX: a deceptive multiplexer-based logic-locking scheme that is resilient against structure-exploiting machine learning attacks. Through the design of D-MUX, we uncover a major fallacy in existing multiplexer-based locking schemes in the form of a structural-analysis attack. Finally, an extensive cost evaluation of D-MUX is presented. To the best of our knowledge, D-MUX is the first machine-learning-resilient locking scheme capable of protecting against all known learning-based attacks. Hereby, the presented work offers a starting point for the design and evaluation of future-generation logic locking in the era of machine learning.
Challenging the Security of Logic Locking Schemes in the Era of Deep Learning: A Neuroevolutionary Approach
Nov 30, 2020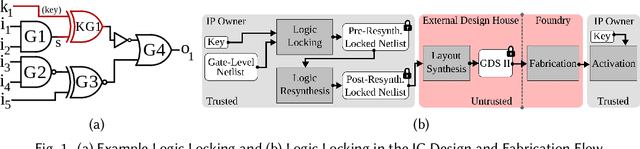

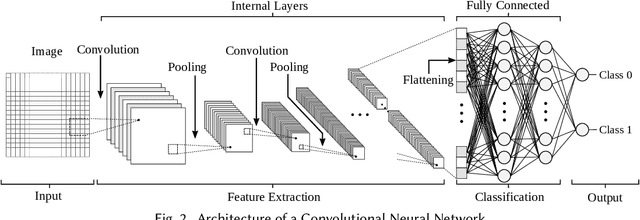
Logic locking is a prominent technique to protect the integrity of hardware designs throughout the integrated circuit design and fabrication flow. However, in recent years, the security of locking schemes has been thoroughly challenged by the introduction of various deobfuscation attacks. As in most research branches, deep learning is being introduced in the domain of logic locking as well. Therefore, in this paper we present SnapShot: a novel attack on logic locking that is the first of its kind to utilize artificial neural networks to directly predict a key bit value from a locked synthesized gate-level netlist without using a golden reference. Hereby, the attack uses a simpler yet more flexible learning model compared to existing work. Two different approaches are evaluated. The first approach is based on a simple feedforward fully connected neural network. The second approach utilizes genetic algorithms to evolve more complex convolutional neural network architectures specialized for the given task. The attack flow offers a generic and customizable framework for attacking locking schemes using machine learning techniques. We perform an extensive evaluation of SnapShot for two realistic attack scenarios, comprising both reference benchmark circuits as well as silicon-proven RISC-V core modules. The evaluation results show that SnapShot achieves an average key prediction accuracy of 82.60% for the selected attack scenario, with a significant performance increase of 10.49 percentage points compared to the state of the art. Moreover, SnapShot outperforms the existing technique on all evaluated benchmarks. The results indicate that the security foundation of common logic locking schemes is build on questionable assumptions. The conclusions of the evaluation offer insights into the challenges of designing future logic locking schemes that are resilient to machine learning attacks.
Dataflow Aware Mapping of Convolutional Neural Networks Onto Many-Core Platforms With Network-on-Chip Interconnect
Jun 18, 2020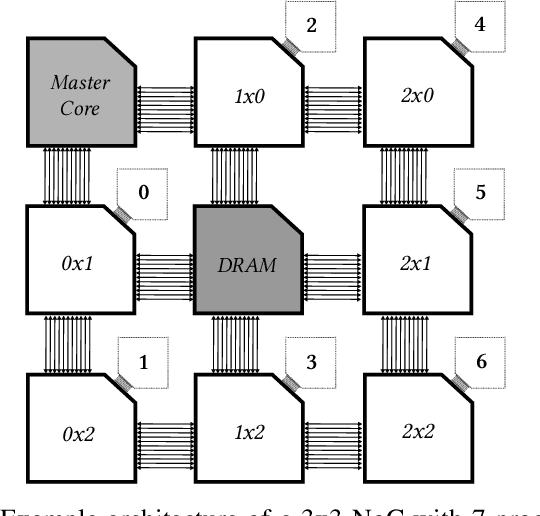
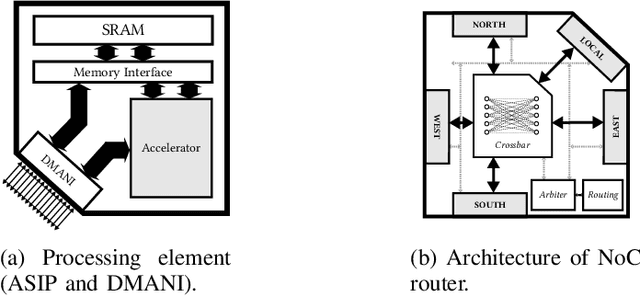
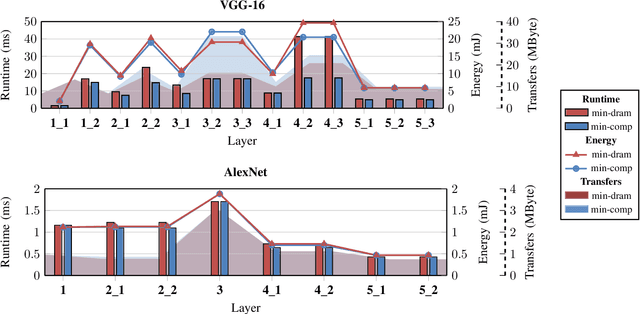
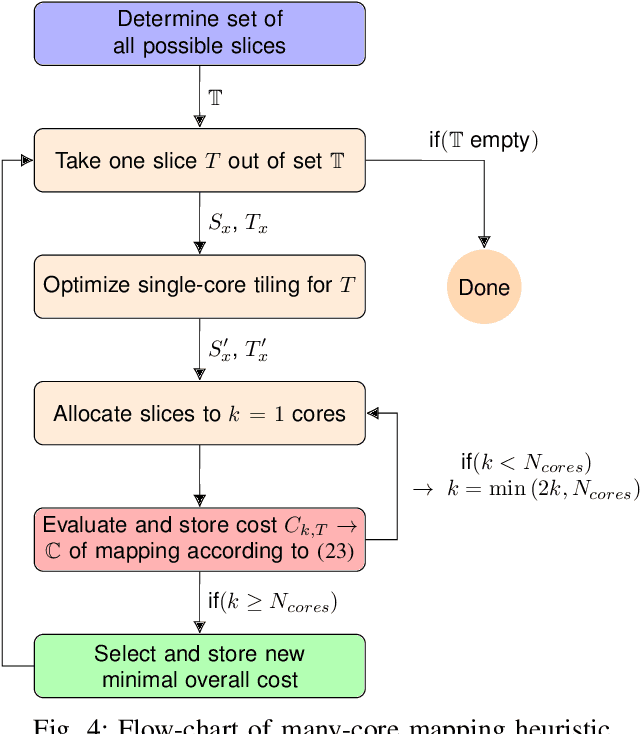
Machine intelligence, especially using convolutional neural networks (CNNs), has become a large area of research over the past years. Increasingly sophisticated hardware accelerators are proposed that exploit e.g. the sparsity in computations and make use of reduced precision arithmetic to scale down the energy consumption. However, future platforms require more than just energy efficiency: Scalability is becoming an increasingly important factor. The required effort for physical implementation grows with the size of the accelerator making it more difficult to meet target constraints. Using many-core platforms consisting of several homogeneous cores can alleviate the aforementioned limitations with regard to physical implementation at the expense of an increased dataflow mapping effort. While the dataflow in CNNs is deterministic and can therefore be optimized offline, the problem of finding a suitable scheme that minimizes both runtime and off-chip memory accesses is a challenging task which becomes even more complex if an interconnect system is involved. This work presents an automated mapping strategy starting at the single-core level with different optimization targets for minimal runtime and minimal off-chip memory accesses. The strategy is then extended towards a suitable many-core mapping scheme and evaluated using a scalable system-level simulation with a network-on-chip interconnect. Design space exploration is performed by mapping the well-known CNNs AlexNet and VGG-16 to platforms of different core counts and computational power per core in order to investigate the trade-offs. Our mapping strategy and system setup is scaled starting from the single core level up to 128 cores, thereby showing the limits of the selected approach.