 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Application-Specific VLIW Processor with Vector Instruction Set for CNN Acceleration
Paper and Code
Apr 10, 2019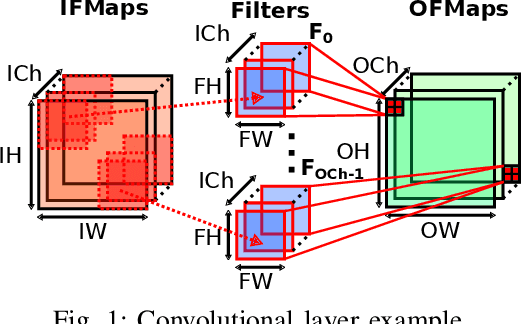


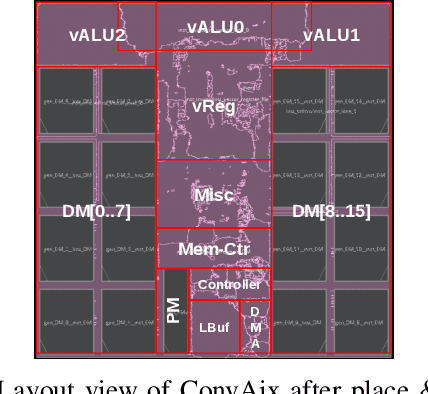
In recent years, neural networks have surpassed classical algorithms in areas such as object recognition, e.g. in the well-known ImageNet challenge. As a result, great effort is being put into developing fast and efficient accelerators, especially for Convolutional Neural Networks (CNNs). In this work we present ConvAix, a fully C-programmable processor, which -- contrary to many existing architectures -- does not rely on a hard-wired array of multiply-and-accumulate (MAC) units. Instead it maps computations onto independent vector lanes making use of a carefully designed vector instruction set. The presented processor is targeted towards latency-sensitive applications and is capable of executing up to 192 MAC operations per cycle. ConvAix operates at a target clock frequency of 400 MHz in 28nm CMOS, thereby offering state-of-the-art performance with proper flexibility within its target domain. Simulation results for several 2D convolutional layers from well known CNNs (AlexNet, VGG-16) show an average ALU utilization of 72.5% using vector instructions with 16 bit fixed-point arithmetic. Compared to other well-known designs which are less flexible, ConvAix offers competitive energy efficiency of up to 497 GOP/s/W while even surpassing them in terms of area efficiency and processing speed.