 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDataflow Aware Mapping of Convolutional Neural Networks Onto Many-Core Platforms With Network-on-Chip Interconnect
Jun 18, 2020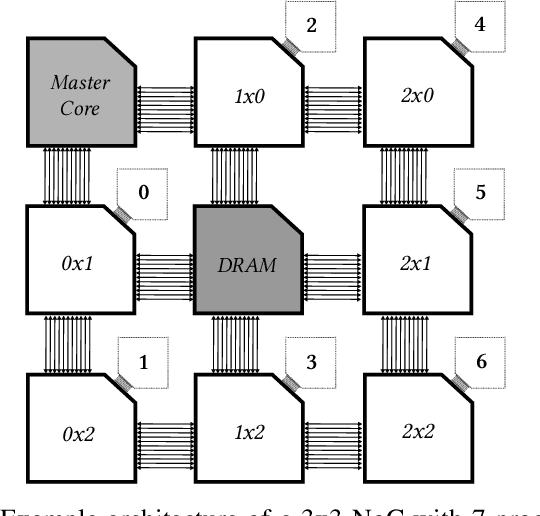
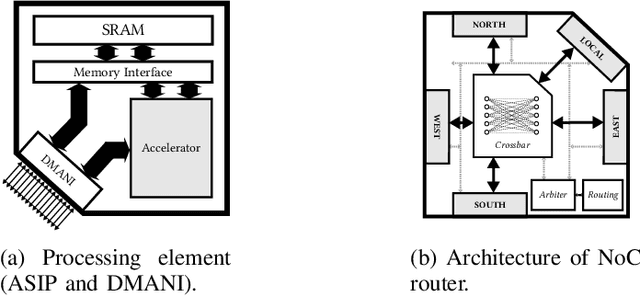
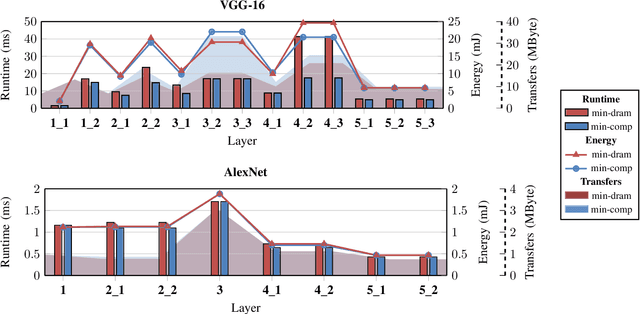
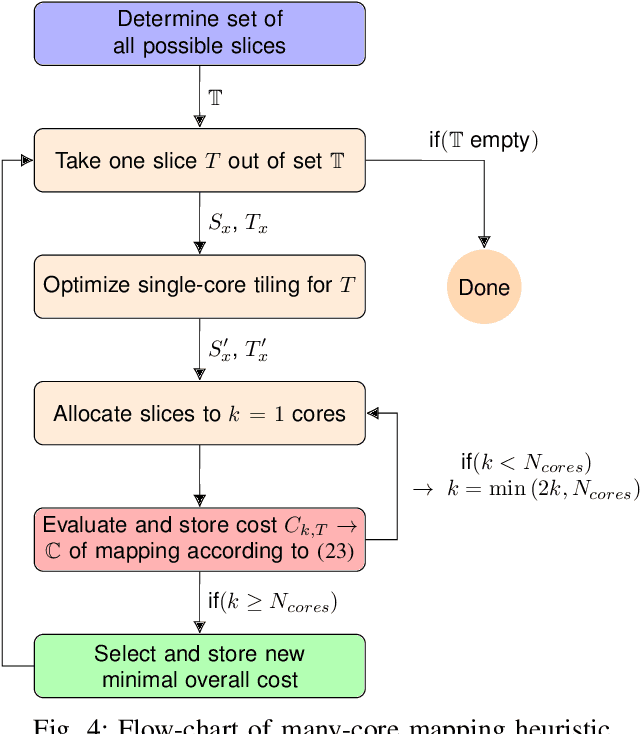
Machine intelligence, especially using convolutional neural networks (CNNs), has become a large area of research over the past years. Increasingly sophisticated hardware accelerators are proposed that exploit e.g. the sparsity in computations and make use of reduced precision arithmetic to scale down the energy consumption. However, future platforms require more than just energy efficiency: Scalability is becoming an increasingly important factor. The required effort for physical implementation grows with the size of the accelerator making it more difficult to meet target constraints. Using many-core platforms consisting of several homogeneous cores can alleviate the aforementioned limitations with regard to physical implementation at the expense of an increased dataflow mapping effort. While the dataflow in CNNs is deterministic and can therefore be optimized offline, the problem of finding a suitable scheme that minimizes both runtime and off-chip memory accesses is a challenging task which becomes even more complex if an interconnect system is involved. This work presents an automated mapping strategy starting at the single-core level with different optimization targets for minimal runtime and minimal off-chip memory accesses. The strategy is then extended towards a suitable many-core mapping scheme and evaluated using a scalable system-level simulation with a network-on-chip interconnect. Design space exploration is performed by mapping the well-known CNNs AlexNet and VGG-16 to platforms of different core counts and computational power per core in order to investigate the trade-offs. Our mapping strategy and system setup is scaled starting from the single core level up to 128 cores, thereby showing the limits of the selected approach.
An Application-Specific VLIW Processor with Vector Instruction Set for CNN Acceleration
Apr 10, 2019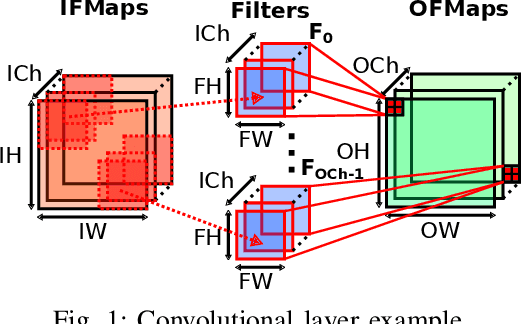


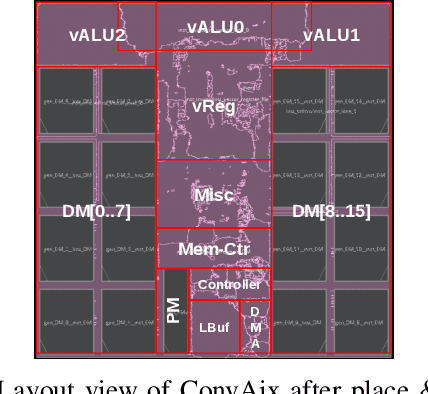
In recent years, neural networks have surpassed classical algorithms in areas such as object recognition, e.g. in the well-known ImageNet challenge. As a result, great effort is being put into developing fast and efficient accelerators, especially for Convolutional Neural Networks (CNNs). In this work we present ConvAix, a fully C-programmable processor, which -- contrary to many existing architectures -- does not rely on a hard-wired array of multiply-and-accumulate (MAC) units. Instead it maps computations onto independent vector lanes making use of a carefully designed vector instruction set. The presented processor is targeted towards latency-sensitive applications and is capable of executing up to 192 MAC operations per cycle. ConvAix operates at a target clock frequency of 400 MHz in 28nm CMOS, thereby offering state-of-the-art performance with proper flexibility within its target domain. Simulation results for several 2D convolutional layers from well known CNNs (AlexNet, VGG-16) show an average ALU utilization of 72.5% using vector instructions with 16 bit fixed-point arithmetic. Compared to other well-known designs which are less flexible, ConvAix offers competitive energy efficiency of up to 497 GOP/s/W while even surpassing them in terms of area efficiency and processing speed.