 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiteVSR: Efficient Visual Speech Recognition by Learning from Speech Representations of Unlabeled Data
Dec 15, 2023



This paper proposes a novel, resource-efficient approach to Visual Speech Recognition (VSR) leveraging speech representations produced by any trained Automatic Speech Recognition (ASR) model. Moving away from the resource-intensive trends prevalent in recent literature, our method distills knowledge from a trained Conformer-based ASR model, achieving competitive performance on standard VSR benchmarks with significantly less resource utilization. Using unlabeled audio-visual data only, our baseline model achieves a word error rate (WER) of 47.4% and 54.7% on the LRS2 and LRS3 test benchmarks, respectively. After fine-tuning the model with limited labeled data, the word error rate reduces to 35% (LRS2) and 45.7% (LRS3). Our model can be trained on a single consumer-grade GPU within a few days and is capable of performing real-time end-to-end VSR on dated hardware, suggesting a path towards more accessible and resource-efficient VSR methodologies.
EVO-RL: Evolutionary-Driven Reinforcement Learning
Jul 10, 2020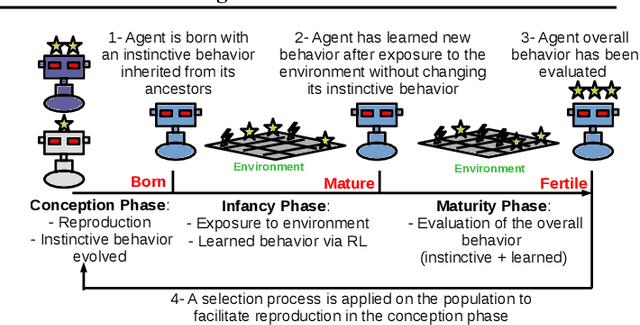
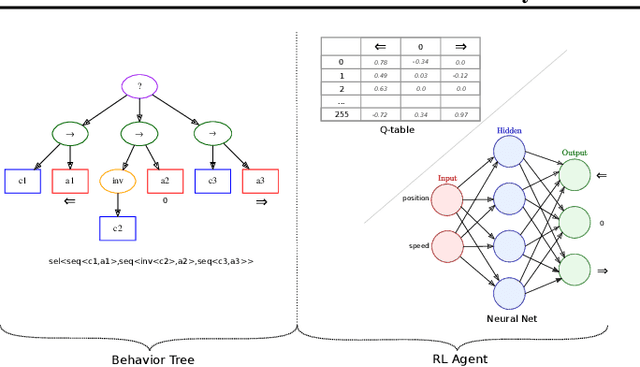
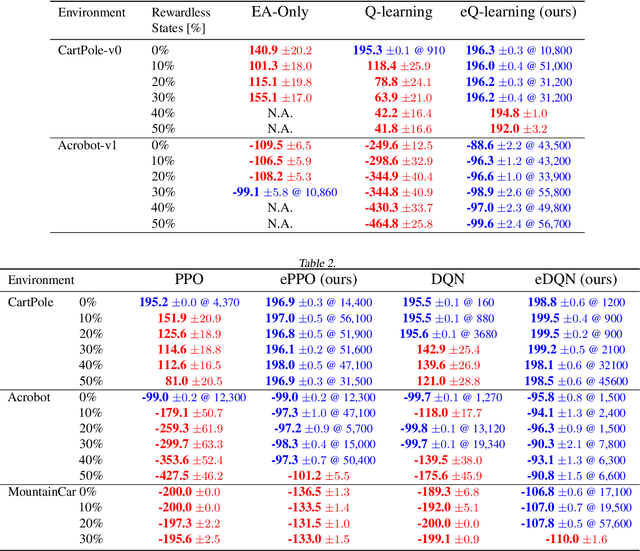
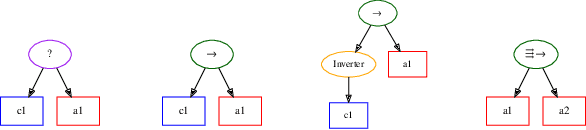
In this work, we propose a novel approach for reinforcement learning driven by evolutionary computation. Our algorithm, dubbed as Evolutionary-Driven Reinforcement Learning (evo-RL), embeds the reinforcement learning algorithm in an evolutionary cycle, where we distinctly differentiate between purely evolvable (instinctive) behaviour versus purely learnable behaviour. Furthermore, we propose that this distinction is decided by the evolutionary process, thus allowing evo-RL to be adaptive to different environments. In addition, evo-RL facilitates learning on environments with rewardless states, which makes it more suited for real-world problems with incomplete information. To show that evo-RL leads to state-of-the-art performance, we present the performance of different state-of-the-art reinforcement learning algorithms when operating within evo-RL and compare it with the case when these same algorithms are executed independently. Results show that reinforcement learning algorithms embedded within our evo-RL approach significantly outperform the stand-alone versions of the same RL algorithms on OpenAI Gym control problems with rewardless states constrained by the same computational budget.