 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLikelihood-based Sensor Calibration for Expert-Supported Distributed Learning Algorithms in IoT Systems
Sep 20, 2023



An important task in the field of sensor technology is the efficient implementation of adaptation procedures of measurements from one sensor to another sensor of identical design. One idea is to use the estimation of an affine transformation between different systems, which can be improved by the knowledge of experts. This paper presents an improved solution from Glacier Research that was published back in 1973. It is shown that this solution can be adapted for software calibration of sensors, implementation of expert-based adaptation, and federated learning methods. We evaluate our research with simulations and also with real measured data of a multi-sensor board with 8 identical sensors. The results show an improvement for both the simulation and the experiments with real data.
Exploring Adversarial Attacks on Neural Networks: An Explainable Approach
Mar 08, 2023Deep Learning (DL) is being applied in various domains, especially in safety-critical applications such as autonomous driving. Consequently, it is of great significance to ensure the robustness of these methods and thus counteract uncertain behaviors caused by adversarial attacks. In this paper, we use gradient heatmaps to analyze the response characteristics of the VGG-16 model when the input images are mixed with adversarial noise and statistically similar Gaussian random noise. In particular, we compare the network response layer by layer to determine where errors occurred. Several interesting findings are derived. First, compared to Gaussian random noise, intentionally generated adversarial noise causes severe behavior deviation by distracting the area of concentration in the networks. Second, in many cases, adversarial examples only need to compromise a few intermediate blocks to mislead the final decision. Third, our experiments revealed that specific blocks are more vulnerable and easier to exploit by adversarial examples. Finally, we demonstrate that the layers $Block4\_conv1$ and $Block5\_cov1$ of the VGG-16 model are more susceptible to adversarial attacks. Our work could provide valuable insights into developing more reliable Deep Neural Network (DNN) models.
An Adaptive Multi-Agent Physical Layer Security Framework for Cognitive Cyber-Physical Systems
Jan 07, 2021
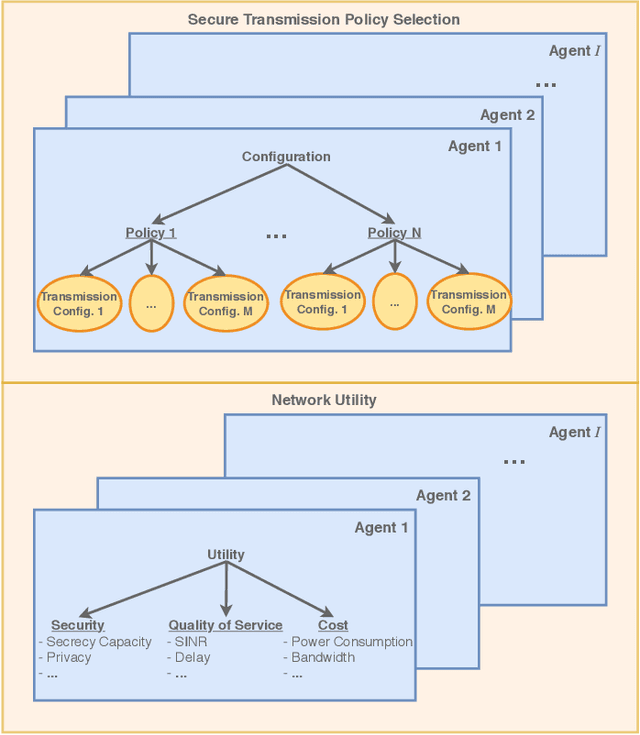
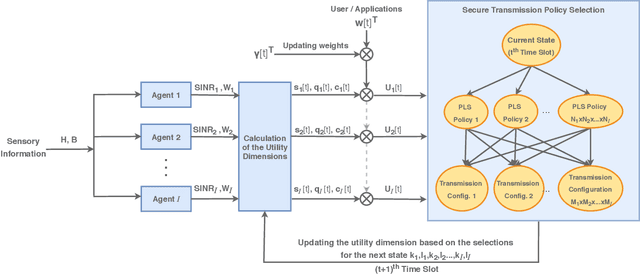
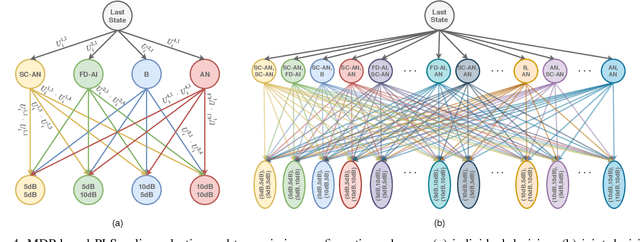
Being capable of sensing and behavioral adaptation in line with their changing environments, cognitive cyber-physical systems (CCPSs) are the new form of applications in future wireless networks. With the advancement of the machine learning algorithms, the transmission scheme providing the best performance can be utilized to sustain a reliable network of CCPS agents equipped with self-decision mechanisms, where the interactions between each agent are modeled in terms of service quality, security, and cost dimensions. In this work, first, we provide network utility as a reliability metric, which is a weighted sum of the individual utility values of the CCPS agents. The individual utilities are calculated by mixing the quality of service (QoS), security, and cost dimensions with the proportions determined by the individualized user requirements. By changing the proportions, the CCPS network can be tuned for different applications of next-generation wireless networks. Then, we propose a secure transmission policy selection (STPS) mechanism that maximizes the network utility by using the Markov-decision process (MDP). In STPS, the CCPS network jointly selects the best performing physical layer security policy and the parameters of the selected secure transmission policy to adapt to the changing environmental effects. The proposed STPS is realized by reinforcement learning (RL), considering its real-time decision mechanism where agents can decide automatically the best utility providing policy in an altering environment.
EVO-RL: Evolutionary-Driven Reinforcement Learning
Jul 10, 2020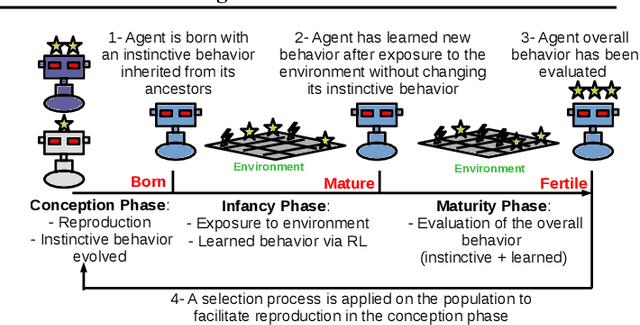
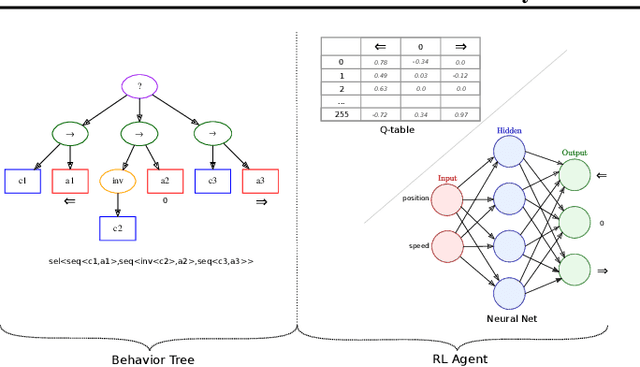
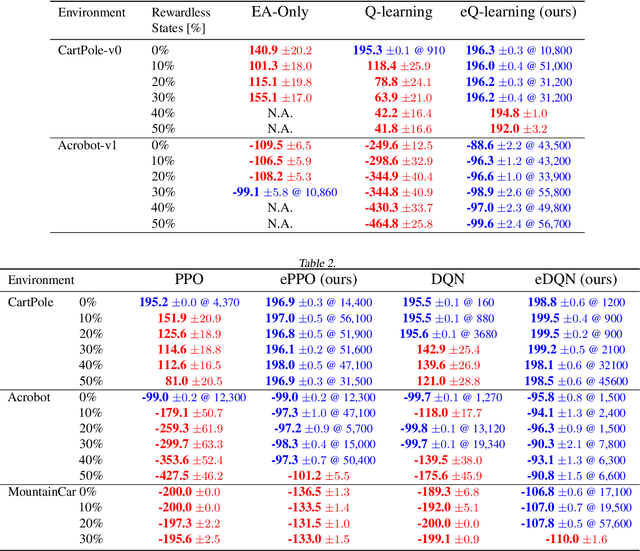
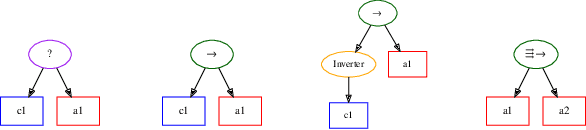
In this work, we propose a novel approach for reinforcement learning driven by evolutionary computation. Our algorithm, dubbed as Evolutionary-Driven Reinforcement Learning (evo-RL), embeds the reinforcement learning algorithm in an evolutionary cycle, where we distinctly differentiate between purely evolvable (instinctive) behaviour versus purely learnable behaviour. Furthermore, we propose that this distinction is decided by the evolutionary process, thus allowing evo-RL to be adaptive to different environments. In addition, evo-RL facilitates learning on environments with rewardless states, which makes it more suited for real-world problems with incomplete information. To show that evo-RL leads to state-of-the-art performance, we present the performance of different state-of-the-art reinforcement learning algorithms when operating within evo-RL and compare it with the case when these same algorithms are executed independently. Results show that reinforcement learning algorithms embedded within our evo-RL approach significantly outperform the stand-alone versions of the same RL algorithms on OpenAI Gym control problems with rewardless states constrained by the same computational budget.