 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoiseCAM: Explainable AI for the Boundary Between Noise and Adversarial Attacks
Mar 09, 2023
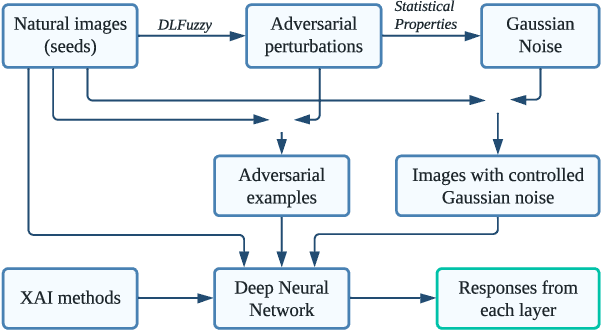
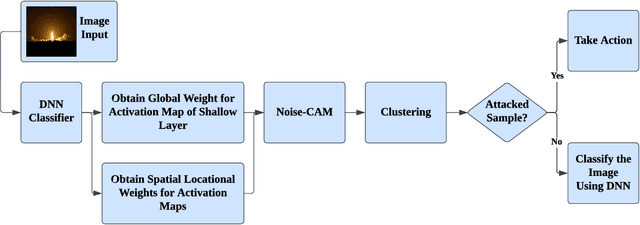
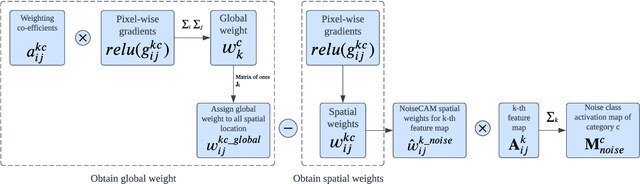
Deep Learning (DL) and Deep Neural Networks (DNNs) are widely used in various domains. However, adversarial attacks can easily mislead a neural network and lead to wrong decisions. Defense mechanisms are highly preferred in safety-critical applications. In this paper, firstly, we use the gradient class activation map (GradCAM) to analyze the behavior deviation of the VGG-16 network when its inputs are mixed with adversarial perturbation or Gaussian noise. In particular, our method can locate vulnerable layers that are sensitive to adversarial perturbation and Gaussian noise. We also show that the behavior deviation of vulnerable layers can be used to detect adversarial examples. Secondly, we propose a novel NoiseCAM algorithm that integrates information from globally and pixel-level weighted class activation maps. Our algorithm is susceptible to adversarial perturbations and will not respond to Gaussian random noise mixed in the inputs. Third, we compare detecting adversarial examples using both behavior deviation and NoiseCAM, and we show that NoiseCAM outperforms behavior deviation modeling in its overall performance. Our work could provide a useful tool to defend against certain adversarial attacks on deep neural networks.
Exploring Adversarial Attacks on Neural Networks: An Explainable Approach
Mar 08, 2023Deep Learning (DL) is being applied in various domains, especially in safety-critical applications such as autonomous driving. Consequently, it is of great significance to ensure the robustness of these methods and thus counteract uncertain behaviors caused by adversarial attacks. In this paper, we use gradient heatmaps to analyze the response characteristics of the VGG-16 model when the input images are mixed with adversarial noise and statistically similar Gaussian random noise. In particular, we compare the network response layer by layer to determine where errors occurred. Several interesting findings are derived. First, compared to Gaussian random noise, intentionally generated adversarial noise causes severe behavior deviation by distracting the area of concentration in the networks. Second, in many cases, adversarial examples only need to compromise a few intermediate blocks to mislead the final decision. Third, our experiments revealed that specific blocks are more vulnerable and easier to exploit by adversarial examples. Finally, we demonstrate that the layers $Block4\_conv1$ and $Block5\_cov1$ of the VGG-16 model are more susceptible to adversarial attacks. Our work could provide valuable insights into developing more reliable Deep Neural Network (DNN) models.