 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI-Driven Decision Support in Oncology: Evaluating Data Readiness for Skin Cancer Treatment
Mar 12, 2025



This research focuses on evaluating and enhancing data readiness for the development of an Artificial Intelligence (AI)-based Clinical Decision Support System (CDSS) in the context of skin cancer treatment. The study, conducted at the Skin Tumor Center of the University Hospital M\"unster, delves into the essential role of data quality, availability, and extractability in implementing effective AI applications in oncology. By employing a multifaceted methodology, including literature review, data readiness assessment, and expert workshops, the study addresses the challenges of integrating AI into clinical decision-making. The research identifies crucial data points for skin cancer treatment decisions, evaluates their presence and quality in various information systems, and highlights the difficulties in extracting information from unstructured data. The findings underline the significance of high-quality, accessible data for the success of AI-driven CDSS in medical settings, particularly in the complex field of oncology.
From Internet of Things Data to Business Processes: Challenges and a Framework
May 14, 2024



The IoT and Business Process Management (BPM) communities co-exist in many shared application domains, such as manufacturing and healthcare. The IoT community has a strong focus on hardware, connectivity and data; the BPM community focuses mainly on finding, controlling, and enhancing the structured interactions among the IoT devices in processes. While the field of Process Mining deals with the extraction of process models and process analytics from process event logs, the data produced by IoT sensors often is at a lower granularity than these process-level events. The fundamental questions about extracting and abstracting process-related data from streams of IoT sensor values are: (1) Which sensor values can be clustered together as part of process events?, (2) Which sensor values signify the start and end of such events?, (3) Which sensor values are related but not essential? This work proposes a framework to semi-automatically perform a set of structured steps to convert low-level IoT sensor data into higher-level process events that are suitable for process mining. The framework is meant to provide a generic sequence of abstract steps to guide the event extraction, abstraction, and correlation, with variation points for plugging in specific analysis techniques and algorithms for each step. To assess the completeness of the framework, we present a set of challenges, how they can be tackled through the framework, and an example on how to instantiate the framework in a real-world demonstration from the field of smart manufacturing. Based on this framework, future research can be conducted in a structured manner through refining and improving individual steps.
Likelihood-based Sensor Calibration for Expert-Supported Distributed Learning Algorithms in IoT Systems
Sep 20, 2023



An important task in the field of sensor technology is the efficient implementation of adaptation procedures of measurements from one sensor to another sensor of identical design. One idea is to use the estimation of an affine transformation between different systems, which can be improved by the knowledge of experts. This paper presents an improved solution from Glacier Research that was published back in 1973. It is shown that this solution can be adapted for software calibration of sensors, implementation of expert-based adaptation, and federated learning methods. We evaluate our research with simulations and also with real measured data of a multi-sensor board with 8 identical sensors. The results show an improvement for both the simulation and the experiments with real data.
Declarative Guideline Conformance Checking of Clinical Treatments: A Case Study
Sep 20, 2022
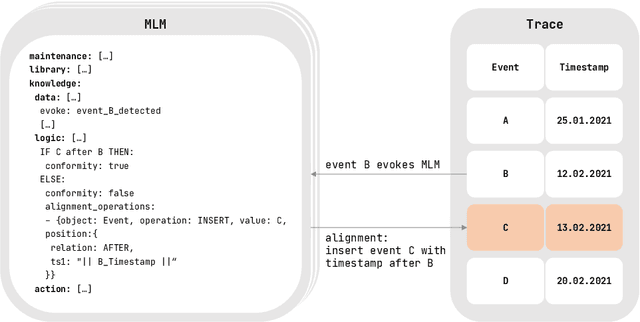
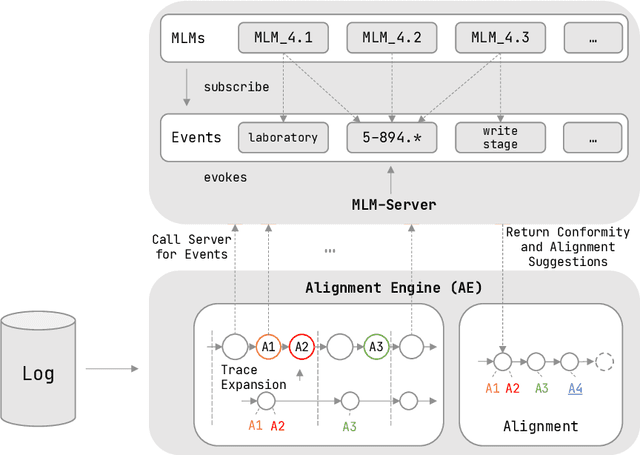
Conformance checking is a process mining technique that allows verifying the conformance of process instances to a given model. Thus, this technique is predestined to be used in the medical context for the comparison of treatment cases with clinical guidelines. However, medical processes are highly variable, highly dynamic, and complex. This makes the use of imperative conformance checking approaches in the medical domain difficult. Studies show that declarative approaches can better address these characteristics. However, none of the approaches has yet gained practical acceptance. Another challenge are alignments, which usually do not add any value from a medical point of view. For this reason, we investigate in a case study the usability of the HL7 standard Arden Syntax for declarative, rule-based conformance checking and the use of manually modeled alignments. Using the approach, it was possible to check the conformance of treatment cases and create medically meaningful alignments for large parts of a medical guideline.
Informed Machine Learning for Improved Similarity Assessment in Process-Oriented Case-Based Reasoning
Jun 30, 2021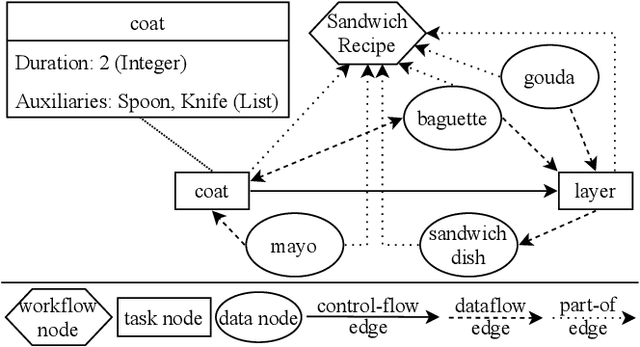

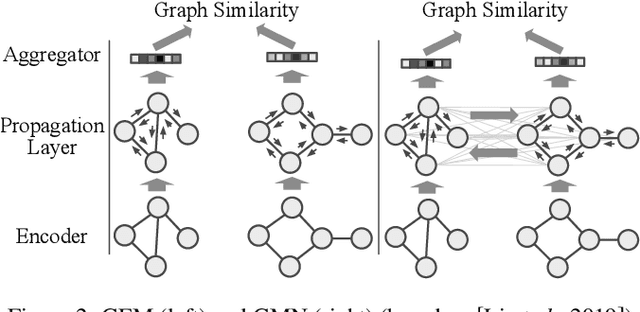
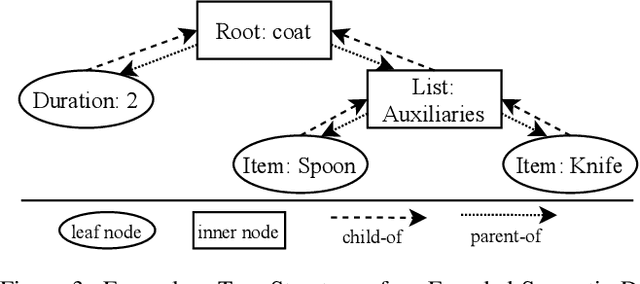
Currently, Deep Learning (DL) components within a Case-Based Reasoning (CBR) application often lack the comprehensive integration of available domain knowledge. The trend within machine learning towards so-called Informed machine learning can help to overcome this limitation. In this paper, we therefore investigate the potential of integrating domain knowledge into Graph Neural Networks (GNNs) that are used for similarity assessment between semantic graphs within process-oriented CBR applications. We integrate knowledge in two ways: First, a special data representation and processing method is used that encodes structural knowledge about the semantic annotations of each graph node and edge. Second, the message-passing component of the GNNs is constrained by knowledge on legal node mappings. The evaluation examines the quality and training time of the extended GNNs, compared to the stock models. The results show that both extensions are capable of providing better quality, shorter training times, or in some configurations both advantages at once.
Using Semantic Web Services for AI-Based Research in Industry 4.0
Jul 07, 2020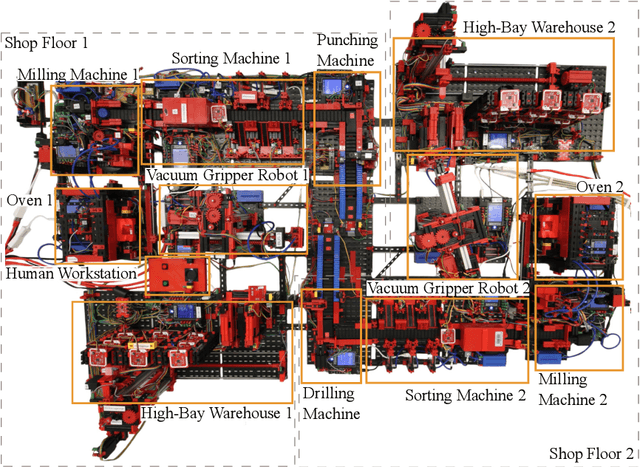
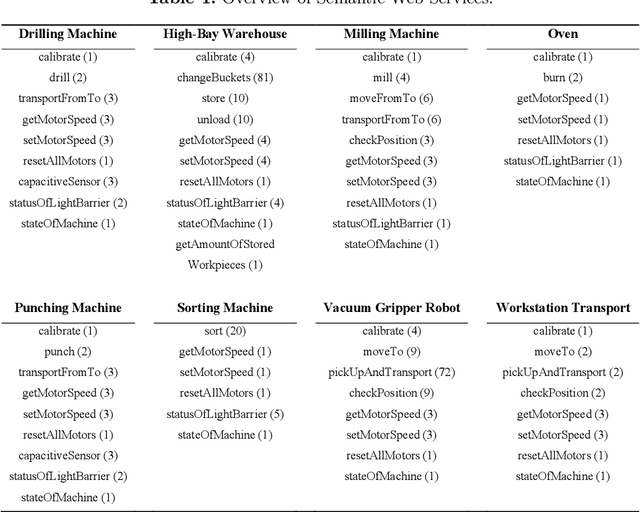
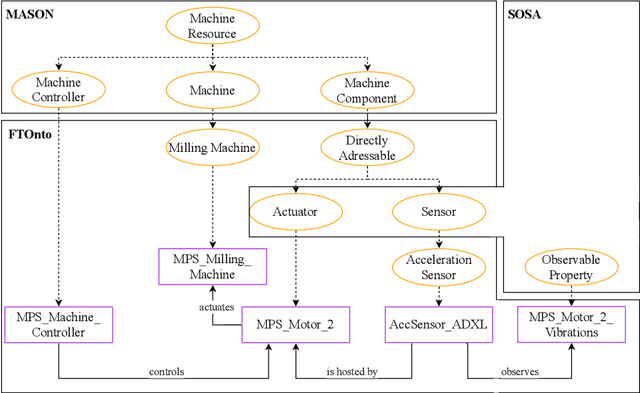
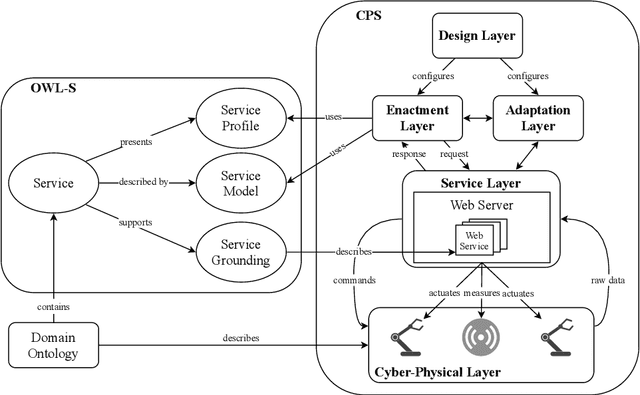
The transition to Industry 4.0 requires smart manufacturing systems that are easily configurable and provide a high level of flexibility during manufacturing in order to achieve mass customization or to support cloud manufacturing. To realize this, Cyber-Physical Systems (CPSs) combined with Artificial Intelligence (AI) methods find their way into manufacturing shop floors. For using AI methods in the context of Industry 4.0, semantic web services are indispensable to provide a reasonable abstraction of the underlying manufacturing capabilities. In this paper, we present semantic web services for AI-based research in Industry 4.0. Therefore, we developed more than 300 semantic web services for a physical simulation factory based on Web Ontology Language for Web Services (OWL-S) and Web Service Modeling Ontology (WSMO) and linked them to an already existing domain ontology for intelligent manufacturing control. Suitable for the requirements of CPS environments, our pre- and postconditions are verified in near real-time by invoking other semantic web services in contrast to complex reasoning within the knowledge base. Finally, we evaluate our implementation by executing a cyber-physical workflow composed of semantic web services using a workflow management system.
Towards an Argument Mining Pipeline Transforming Texts to Argument Graphs
Jun 08, 2020


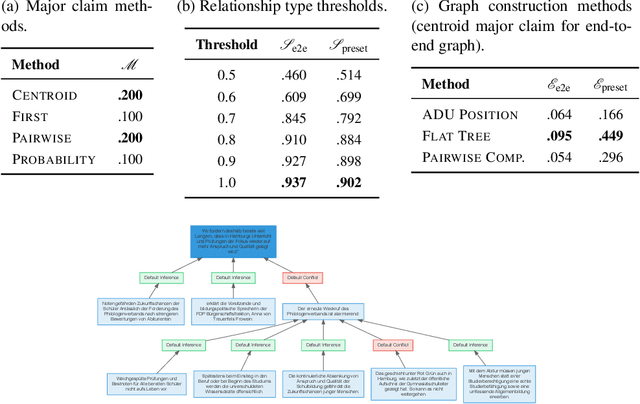
This paper targets the automated extraction of components of argumentative information and their relations from natural language text. Moreover, we address a current lack of systems to provide complete argumentative structure from arbitrary natural language text for general usage. We present an argument mining pipeline as a universally applicable approach for transforming German and English language texts to graph-based argument representations. We also introduce new methods for evaluating the results based on existing benchmark argument structures. Our results show that the generated argument graphs can be beneficial to detect new connections between different statements of an argumentative text. Our pipeline implementation is publicly available on GitHub.
Same Side Stance Classification Task: Facilitating Argument Stance Classification by Fine-tuning a BERT Model
Apr 23, 2020
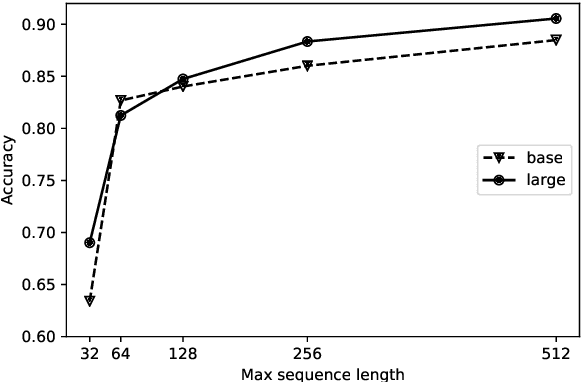
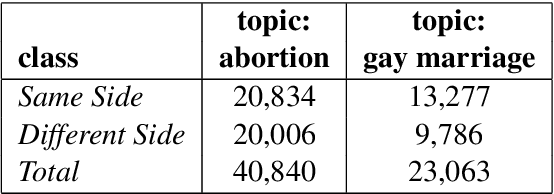
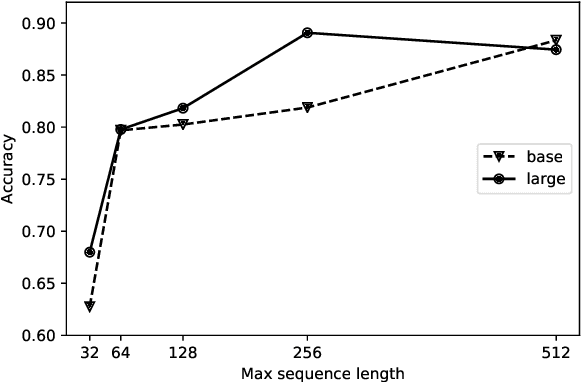
Research on computational argumentation is currently being intensively investigated. The goal of this community is to find the best pro and con arguments for a user given topic either to form an opinion for oneself, or to persuade others to adopt a certain standpoint. While existing argument mining methods can find appropriate arguments for a topic, a correct classification into pro and con is not yet reliable. The same side stance classification task provides a dataset of argument pairs classified by whether or not both arguments share the same stance and does not need to distinguish between topic-specific pro and con vocabulary but only the argument similarity within a stance needs to be assessed. The results of our contribution to the task are build on a setup based on the BERT architecture. We fine-tuned a pre-trained BERT model for three epochs and used the first 512 tokens of each argument to predict if two arguments share the same stance.