 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards an Argument Mining Pipeline Transforming Texts to Argument Graphs
Jun 08, 2020


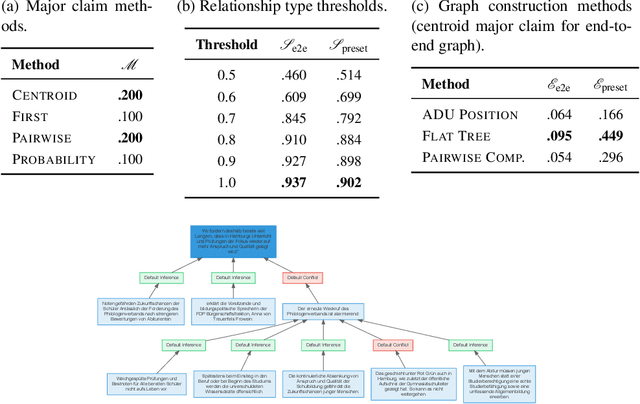
This paper targets the automated extraction of components of argumentative information and their relations from natural language text. Moreover, we address a current lack of systems to provide complete argumentative structure from arbitrary natural language text for general usage. We present an argument mining pipeline as a universally applicable approach for transforming German and English language texts to graph-based argument representations. We also introduce new methods for evaluating the results based on existing benchmark argument structures. Our results show that the generated argument graphs can be beneficial to detect new connections between different statements of an argumentative text. Our pipeline implementation is publicly available on GitHub.
Same Side Stance Classification Task: Facilitating Argument Stance Classification by Fine-tuning a BERT Model
Apr 23, 2020
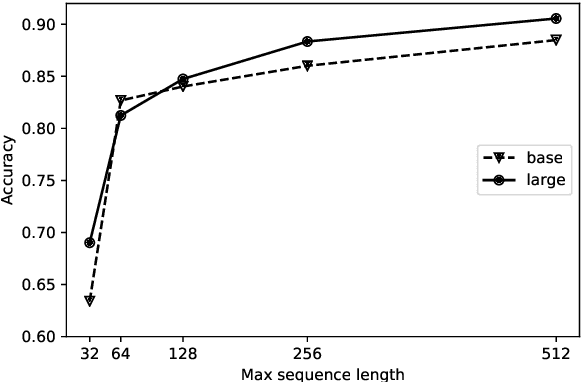
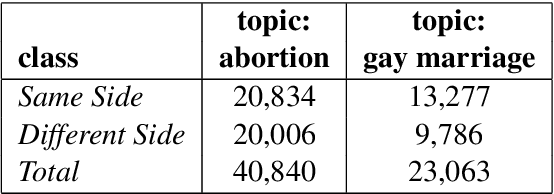
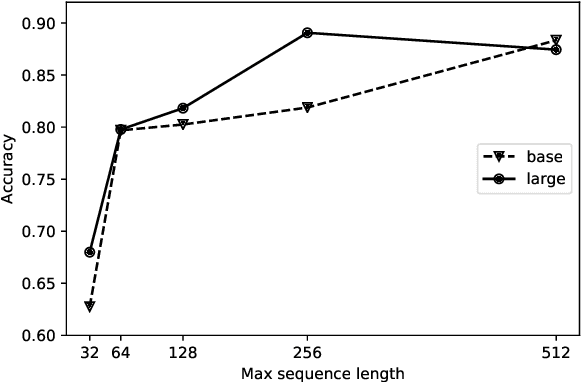
Research on computational argumentation is currently being intensively investigated. The goal of this community is to find the best pro and con arguments for a user given topic either to form an opinion for oneself, or to persuade others to adopt a certain standpoint. While existing argument mining methods can find appropriate arguments for a topic, a correct classification into pro and con is not yet reliable. The same side stance classification task provides a dataset of argument pairs classified by whether or not both arguments share the same stance and does not need to distinguish between topic-specific pro and con vocabulary but only the argument similarity within a stance needs to be assessed. The results of our contribution to the task are build on a setup based on the BERT architecture. We fine-tuned a pre-trained BERT model for three epochs and used the first 512 tokens of each argument to predict if two arguments share the same stance.