 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConversational Process Model Redesign
May 08, 2025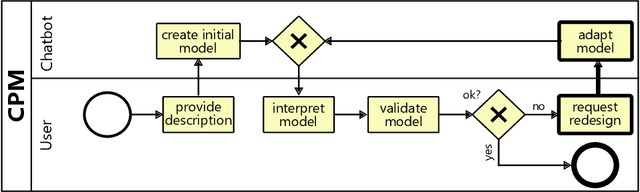

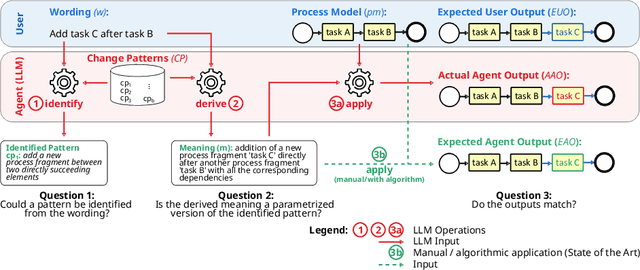

With the recent success of large language models (LLMs), the idea of AI-augmented Business Process Management systems is becoming more feasible. One of their essential characteristics is the ability to be conversationally actionable, allowing humans to interact with the LLM effectively to perform crucial process life cycle tasks such as process model design and redesign. However, most current research focuses on single-prompt execution and evaluation of results, rather than on continuous interaction between the user and the LLM. In this work, we aim to explore the feasibility of using LLMs to empower domain experts in the creation and redesign of process models in an iterative and effective way. The proposed conversational process model redesign (CPD) approach receives as input a process model and a redesign request by the user in natural language. Instead of just letting the LLM make changes, the LLM is employed to (a) identify process change patterns from literature, (b) re-phrase the change request to be aligned with an expected wording for the identified pattern (i.e., the meaning), and then to (c) apply the meaning of the change to the process model. This multi-step approach allows for explainable and reproducible changes. In order to ensure the feasibility of the CPD approach, and to find out how well the patterns from literature can be handled by the LLM, we performed an extensive evaluation. The results show that some patterns are hard to understand by LLMs and by users. Within the scope of the study, we demonstrated that users need support to describe the changes clearly. Overall the evaluation shows that the LLMs can handle most changes well according to a set of completeness and correctness criteria.
From Internet of Things Data to Business Processes: Challenges and a Framework
May 14, 2024



The IoT and Business Process Management (BPM) communities co-exist in many shared application domains, such as manufacturing and healthcare. The IoT community has a strong focus on hardware, connectivity and data; the BPM community focuses mainly on finding, controlling, and enhancing the structured interactions among the IoT devices in processes. While the field of Process Mining deals with the extraction of process models and process analytics from process event logs, the data produced by IoT sensors often is at a lower granularity than these process-level events. The fundamental questions about extracting and abstracting process-related data from streams of IoT sensor values are: (1) Which sensor values can be clustered together as part of process events?, (2) Which sensor values signify the start and end of such events?, (3) Which sensor values are related but not essential? This work proposes a framework to semi-automatically perform a set of structured steps to convert low-level IoT sensor data into higher-level process events that are suitable for process mining. The framework is meant to provide a generic sequence of abstract steps to guide the event extraction, abstraction, and correlation, with variation points for plugging in specific analysis techniques and algorithms for each step. To assess the completeness of the framework, we present a set of challenges, how they can be tackled through the framework, and an example on how to instantiate the framework in a real-world demonstration from the field of smart manufacturing. Based on this framework, future research can be conducted in a structured manner through refining and improving individual steps.
INEXA: Interactive and Explainable Process Model Abstraction Through Object-Centric Process Mining
Mar 27, 2024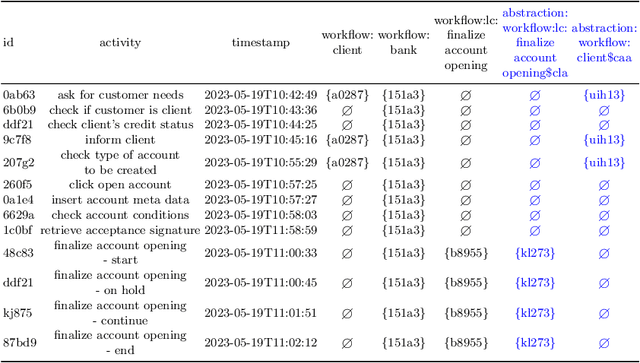
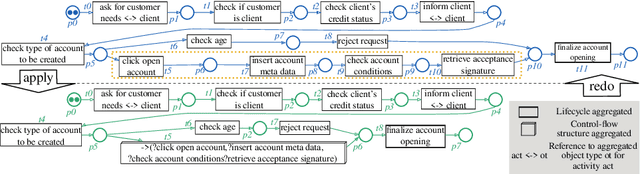

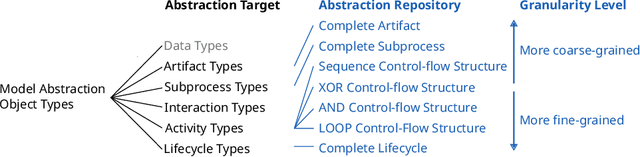
Process events are recorded by multiple information systems at different granularity levels. Based on the resulting event logs, process models are discovered at different granularity levels, as well. Events stored at a fine-grained granularity level, for example, may hinder the discovered process model to be displayed due the high number of resulting model elements. The discovered process model of a real-world manufacturing process, for example, consists of 1,489 model elements and over 2,000 arcs. Existing process model abstraction techniques could help reducing the size of the model, but would disconnect it from the underlying event log. Existing event abstraction techniques do neither support the analysis of mixed granularity levels, nor interactive exploration of a suitable granularity level. To enable the exploration of discovered process models at different granularity levels, we propose INEXA, an interactive, explainable process model abstraction method that keeps the link to the event log. As a starting point, INEXA aggregates large process models to a "displayable" size, e.g., for the manufacturing use case to a process model with 58 model elements. Then, the process analyst can explore granularity levels interactively, while applied abstractions are automatically traced in the event log for explainability.
Model-Driven Engineering Method to Support the Formalization of Machine Learning using SysML
Jul 10, 2023Methods: This work introduces a method supporting the collaborative definition of machine learning tasks by leveraging model-based engineering in the formalization of the systems modeling language SysML. The method supports the identification and integration of various data sources, the required definition of semantic connections between data attributes, and the definition of data processing steps within the machine learning support. Results: By consolidating the knowledge of domain and machine learning experts, a powerful tool to describe machine learning tasks by formalizing knowledge using the systems modeling language SysML is introduced. The method is evaluated based on two use cases, i.e., a smart weather system that allows to predict weather forecasts based on sensor data, and a waste prevention case for 3D printer filament that cancels the printing if the intended result cannot be achieved (image processing). Further, a user study is conducted to gather insights of potential users regarding perceived workload and usability of the elaborated method. Conclusion: Integrating machine learning-specific properties in systems engineering techniques allows non-data scientists to understand formalized knowledge and define specific aspects of a machine learning problem, document knowledge on the data, and to further support data scientists to use the formalized knowledge as input for an implementation using (semi-) automatic code generation. In this respect, this work contributes by consolidating knowledge from various domains and therefore, fosters the integration of machine learning in industry by involving several stakeholders.
Conversational Process Modelling: State of the Art, Applications, and Implications in Practice
Apr 19, 2023Chatbots such as ChatGPT have caused a tremendous hype lately. For BPM applications, it is often not clear how to apply chatbots to generate business value. Hence, this work aims at the systematic analysis of existing chatbots for their support of conversational process modelling as process-oriented capability. Application scenarios are identified along the process life cycle. Then a systematic literature review on conversational process modelling is performed. The resulting taxonomy serves as input for the identification of application scenarios for conversational process modelling, including paraphrasing and improvement of process descriptions. The application scenarios are evaluated for existing chatbots based on a real-world test set from the higher education domain. It contains process descriptions as well as corresponding process models, together with an assessment of the model quality. Based on the literature and application scenario analyses, recommendations for the usage (practical implications) and further development (research directions) of conversational process modelling are derived.
Sustainability Through Cognition Aware Safety Systems -- Next Level Human-Machine-Interaction
Oct 13, 2021

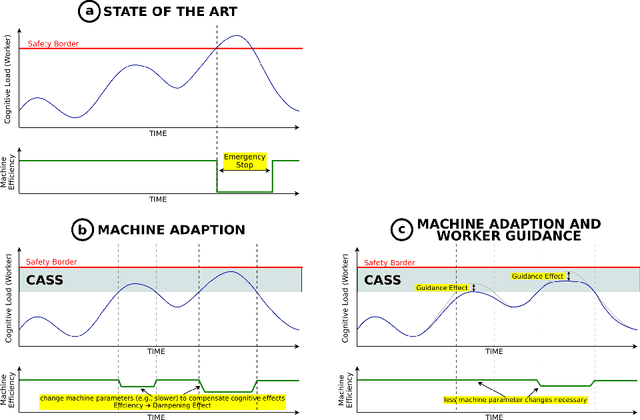

Industrial Safety deals with the physical integrity of humans, machines and the environment when they interact during production scenarios. Industrial Safety is subject to a rigorous certification process that leads to inflexible settings, in which all changes are forbidden. With the progressing introduction of smart robotics and smart machinery to the factory floor, combined with an increasing shortage of skilled workers, it becomes imperative that safety scenarios incorporate a flexible handling of the boundary between humans, machines and the environment. In order to increase the well-being of workers, reduce accidents, and compensate for different skill sets, the configuration of machines and the factory floor should be dynamically adapted, while still enforcing functional safety requirements. The contribution of this paper is as follows: (1) We present a set of three scenarios, and discuss how industrial safety mechanisms could be augmented through dynamic changes to the work environment in order to decrease potential accidents, and thus increase productivity. (2) We introduce the concept of a Cognition Aware Safety System (CASS) and its architecture. The idea behind CASS is to integrate AI based reasoning about human load, stress, and attention with AI based selection of actions to avoid the triggering of safety stops. (3) And finally, we will describe the required performance measurement dimensions for a quantitative performance measurement model to enable a comprehensive (triple bottom line) impact assessment of CASS. Additionally we introduce a detailed guideline for expert interviews to explore the feasibility of the approach for given scenarios.
The Role of Time and Data: Online Conformance Checking in the Manufacturing Domain
May 04, 2021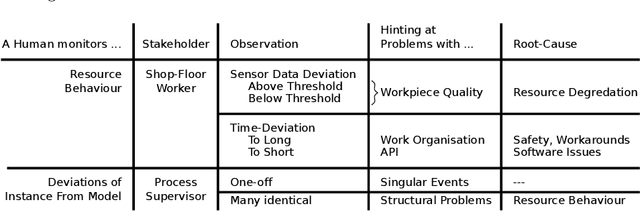
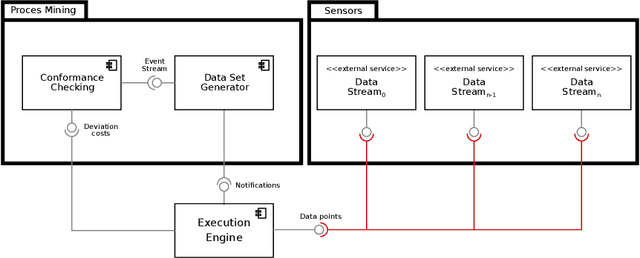
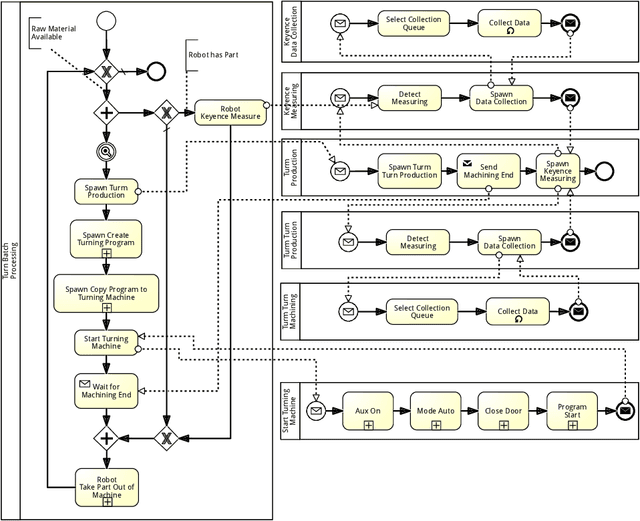
Process mining has matured as analysis instrument for process-oriented data in recent years. Manufacturing is a challenging domain that craves for process-oriented technologies to address digitalization challenges. We found that process mining creates high expectations, but its implementation and usage by manufacturing experts such as process supervisors and shopfloor workers remain unclear to a certain extent. Reason (1) is that even though manufacturing allows for well-structured processes, the actual workflow is rarely captured in a process model. Even if a model is available, a software for orchestrating and logging the execution is often missing. Reason (2) refers to the work reality in manufacturing: a process instance is started by a shopfloor worker who then turns to work on other things. Hence continuous monitoring of the process instances does not happen, i.e., process monitoring is merely a secondary task, and the shopfloor worker can only react to problems/errors that have already occurred. (1) and (2) motivate the goals of this study that is driven by Technical Action Research (TAR). Based on the experimental artifact TIDATE -- a lightweight process execution and mining framework -- it is studied how the correct execution of process instances can be ensured and how a data set suitable for process mining can be generated at run time in a real-world setting. Secondly, it is investigated whether and how process mining supports domain experts during process monitoring as a secondary task. The findings emphasize the importance of online conformance checking in manufacturing and show how appropriate data sets can be identified and generated.
Generating Reliable Process Event Streams and Time Series Data based on Neural Networks
Mar 20, 2021
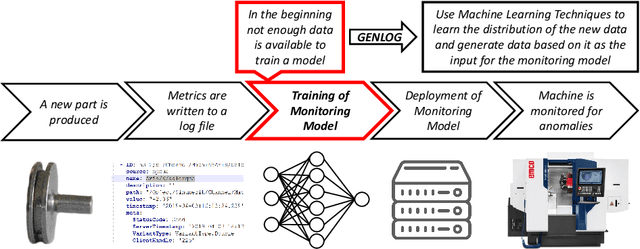

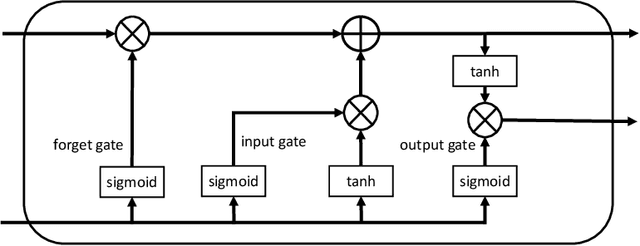
Domains such as manufacturing and medicine crave for continuous monitoring and analysis of their processes, especially in combination with time series as produced by sensors. Time series data can be exploited to, for example, explain and predict concept drifts during runtime. Generally, a certain data volume is required in order to produce meaningful analysis results. However, reliable data sets are often missing, for example, if event streams and times series data are collected separately, in case of a new process, or if it is too expensive to obtain a sufficient data volume. Additional challenges arise with preparing time series data from multiple event sources, variations in data collection frequency, and concept drift. This paper proposes the GENLOG approach to generate reliable event and time series data that follows the distribution of the underlying input data set. GENLOG employs data resampling and enables the user to select different parts of the log data to orchestrate the training of a recurrent neural network for stream generation. The generated data is sampled back to its original sample rate and is embedded into a template representing the log data format it originated from. Overall, GENLOG can boost small data sets and consequently the application of online process mining.