 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentic Business Process Management: A Research Manifesto
Mar 19, 2026This paper presents a manifesto that articulates the conceptual foundations of Agentic Business Process Management (APM), an extension of Business Process Management (BPM) for governing autonomous agents executing processes in organizations. From a management perspective, APM represents a paradigm shift from the traditional process view of the business process, driven by the realization of process awareness and an agent-oriented abstraction, where software and human agents act as primary functional entities that perceive, reason, and act within explicit process frames. This perspective marks a shift from traditional, automation-oriented BPM toward systems in which autonomy is constrained, aligned, and made operational through process awareness. We introduce the core abstractions and architectural elements required to realize APM systems and elaborate on four key capabilities that such APM agents must support: framed autonomy, explainability, conversational actionability, and self-modification. These capabilities jointly ensure that agents' goals are aligned with organizational goals and that agents behave in a framed yet proactive manner in pursuing those goals. We discuss the extent to which the capabilities can be realized and identify research challenges whose resolution requires further advances in BPM, AI, and multi-agent systems. The manifesto thus serves as a roadmap for bridging these communities and for guiding the development of APM systems in practice.
Synchronizing Process Model and Event Abstraction for Grounded Process Intelligence (Extended Version)
May 29, 2025Model abstraction (MA) and event abstraction (EA) are means to reduce complexity of (discovered) models and event data. Imagine a process intelligence project that aims to analyze a model discovered from event data which is further abstracted, possibly multiple times, to reach optimality goals, e.g., reducing model size. So far, after discovering the model, there is no technique that enables the synchronized abstraction of the underlying event log. This results in loosing the grounding in the real-world behavior contained in the log and, in turn, restricts analysis insights. Hence, in this work, we provide the formal basis for synchronized model and event abstraction, i.e., we prove that abstracting a process model by MA and discovering a process model from an abstracted event log yields an equivalent process model. We prove the feasibility of our approach based on behavioral profile abstraction as non-order preserving MA technique, resulting in a novel EA technique.
An Uncertainty-Aware ED-LSTM for Probabilistic Suffix Prediction
May 27, 2025Suffix prediction of business processes forecasts the remaining sequence of events until process completion. Current approaches focus on predicting a single, most likely suffix. However, if the future course of a process is exposed to uncertainty or has high variability, the expressiveness of a single suffix prediction can be limited. To address this limitation, we propose probabilistic suffix prediction, a novel approach that approximates a probability distribution of suffixes. The proposed approach is based on an Uncertainty-Aware Encoder-Decoder LSTM (U-ED-LSTM) and a Monte Carlo (MC) suffix sampling algorithm. We capture epistemic uncertainties via MC dropout and aleatoric uncertainties as learned loss attenuation. This technical report provides a detailed evaluation of the U-ED-LSTM's predictive performance and assesses its calibration on four real-life event logs with three different hyperparameter settings. The results show that i) the U-ED-LSTM has reasonable predictive performance across various datasets, ii) aggregating probabilistic suffix predictions into mean values can outperform most likely predictions, particularly for rare prefixes or longer suffixes, and iii) the approach effectively captures uncertainties present in event logs.
Conversational Process Model Redesign
May 08, 2025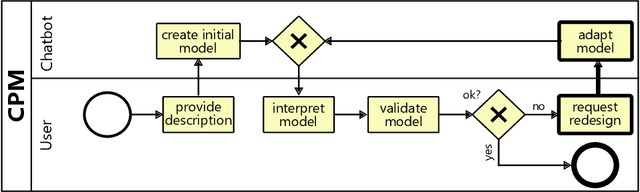

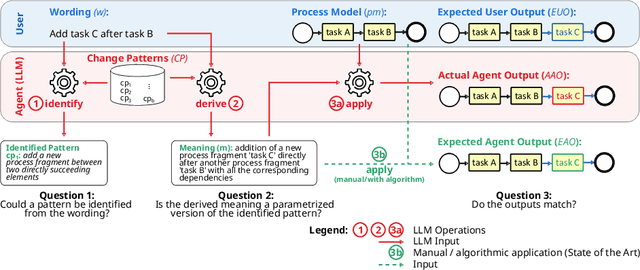

With the recent success of large language models (LLMs), the idea of AI-augmented Business Process Management systems is becoming more feasible. One of their essential characteristics is the ability to be conversationally actionable, allowing humans to interact with the LLM effectively to perform crucial process life cycle tasks such as process model design and redesign. However, most current research focuses on single-prompt execution and evaluation of results, rather than on continuous interaction between the user and the LLM. In this work, we aim to explore the feasibility of using LLMs to empower domain experts in the creation and redesign of process models in an iterative and effective way. The proposed conversational process model redesign (CPD) approach receives as input a process model and a redesign request by the user in natural language. Instead of just letting the LLM make changes, the LLM is employed to (a) identify process change patterns from literature, (b) re-phrase the change request to be aligned with an expected wording for the identified pattern (i.e., the meaning), and then to (c) apply the meaning of the change to the process model. This multi-step approach allows for explainable and reproducible changes. In order to ensure the feasibility of the CPD approach, and to find out how well the patterns from literature can be handled by the LLM, we performed an extensive evaluation. The results show that some patterns are hard to understand by LLMs and by users. Within the scope of the study, we demonstrated that users need support to describe the changes clearly. Overall the evaluation shows that the LLMs can handle most changes well according to a set of completeness and correctness criteria.
Beyond Yes or No: Predictive Compliance Monitoring Approaches for Quantifying the Magnitude of Compliance Violations
Feb 03, 2025



Most existing process compliance monitoring approaches detect compliance violations in an ex post manner. Only predicate prediction focuses on predicting them. However, predicate prediction provides a binary yes/no notion of compliance, lacking the ability to measure to which extent an ongoing process instance deviates from the desired state as specified in constraints. Here, being able to quantify the magnitude of violation would provide organizations with deeper insights into their operational performance, enabling informed decision making to reduce or mitigate the risk of non-compliance. Thus, we propose two predictive compliance monitoring approaches to close this research gap. The first approach reformulates the binary classification problem as a hybrid task that considers both classification and regression, while the second employs a multi-task learning method to explicitly predict the compliance status and the magnitude of violation for deviant cases simultaneously. In this work, we focus on temporal constraints as they are significant in almost any application domain, e.g., health care. The evaluation on synthetic and real-world event logs demonstrates that our approaches are capable of quantifying the magnitude of violations while maintaining comparable performance for compliance predictions achieved by state-of-the-art approaches.
Design of a Quality Management System based on the EU Artificial Intelligence Act
Aug 08, 2024The Artificial Intelligence Act of the European Union mandates that providers and deployers of high-risk AI systems establish a quality management system (QMS). Among other criteria, a QMS shall help to i) identify, analyze, evaluate, and mitigate risks, ii) ensure evidence of compliance with training, validation, and testing data, and iii) verify and document the AI system design and quality. Current research mainly addresses conceptual considerations and framework designs for AI risk assessment and auditing processes. However, it often overlooks practical tools that actively involve and support humans in checking and documenting high-risk or general-purpose AI systems. This paper addresses this gap by proposing requirements derived from legal regulations and a generic design and architecture of a QMS for AI systems verification and documentation. A first version of a prototype QMS is implemented, integrating LLMs as examples of AI systems and focusing on an integrated risk management sub-service. The prototype is evaluated on i) a user story-based qualitative requirements assessment using potential stakeholder scenarios and ii) a technical assessment of the required GPU storage and performance.
Recent Advances in Data-Driven Business Process Management
Jun 03, 2024



The rapid development of cutting-edge technologies, the increasing volume of data and also the availability and processability of new types of data sources has led to a paradigm shift in data-based management and decision-making. Since business processes are at the core of organizational work, these developments heavily impact BPM as a crucial success factor for organizations. In view of this emerging potential, data-driven business process management has become a relevant and vibrant research area. Given the complexity and interdisciplinarity of the research field, this position paper therefore presents research insights regarding data-driven BPM.
From Internet of Things Data to Business Processes: Challenges and a Framework
May 14, 2024



The IoT and Business Process Management (BPM) communities co-exist in many shared application domains, such as manufacturing and healthcare. The IoT community has a strong focus on hardware, connectivity and data; the BPM community focuses mainly on finding, controlling, and enhancing the structured interactions among the IoT devices in processes. While the field of Process Mining deals with the extraction of process models and process analytics from process event logs, the data produced by IoT sensors often is at a lower granularity than these process-level events. The fundamental questions about extracting and abstracting process-related data from streams of IoT sensor values are: (1) Which sensor values can be clustered together as part of process events?, (2) Which sensor values signify the start and end of such events?, (3) Which sensor values are related but not essential? This work proposes a framework to semi-automatically perform a set of structured steps to convert low-level IoT sensor data into higher-level process events that are suitable for process mining. The framework is meant to provide a generic sequence of abstract steps to guide the event extraction, abstraction, and correlation, with variation points for plugging in specific analysis techniques and algorithms for each step. To assess the completeness of the framework, we present a set of challenges, how they can be tackled through the framework, and an example on how to instantiate the framework in a real-world demonstration from the field of smart manufacturing. Based on this framework, future research can be conducted in a structured manner through refining and improving individual steps.
INEXA: Interactive and Explainable Process Model Abstraction Through Object-Centric Process Mining
Mar 27, 2024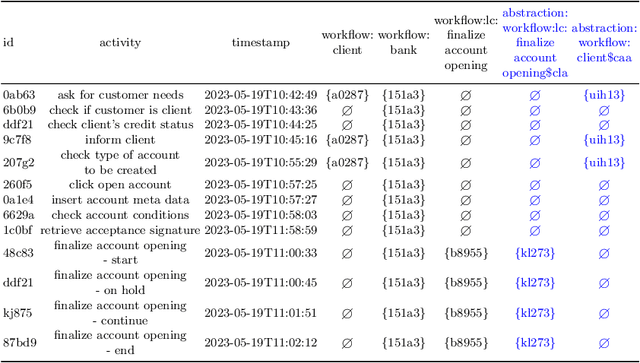
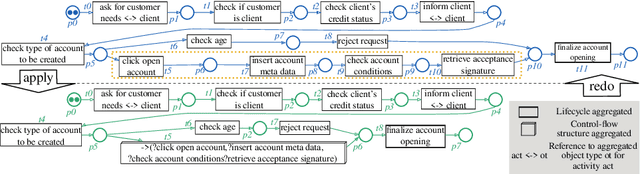

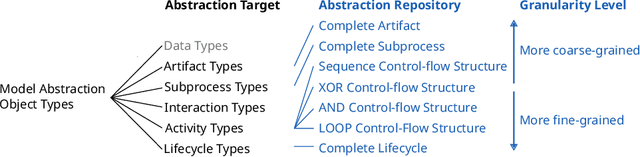
Process events are recorded by multiple information systems at different granularity levels. Based on the resulting event logs, process models are discovered at different granularity levels, as well. Events stored at a fine-grained granularity level, for example, may hinder the discovered process model to be displayed due the high number of resulting model elements. The discovered process model of a real-world manufacturing process, for example, consists of 1,489 model elements and over 2,000 arcs. Existing process model abstraction techniques could help reducing the size of the model, but would disconnect it from the underlying event log. Existing event abstraction techniques do neither support the analysis of mixed granularity levels, nor interactive exploration of a suitable granularity level. To enable the exploration of discovered process models at different granularity levels, we propose INEXA, an interactive, explainable process model abstraction method that keeps the link to the event log. As a starting point, INEXA aggregates large process models to a "displayable" size, e.g., for the manufacturing use case to a process model with 58 model elements. Then, the process analyst can explore granularity levels interactively, while applied abstractions are automatically traced in the event log for explainability.
Identification of Regulatory Requirements Relevant to Business Processes: A Comparative Study on Generative AI, Embedding-based Ranking, Crowd and Expert-driven Methods
Jan 02, 2024



Organizations face the challenge of ensuring compliance with an increasing amount of requirements from various regulatory documents. Which requirements are relevant depends on aspects such as the geographic location of the organization, its domain, size, and business processes. Considering these contextual factors, as a first step, relevant documents (e.g., laws, regulations, directives, policies) are identified, followed by a more detailed analysis of which parts of the identified documents are relevant for which step of a given business process. Nowadays the identification of regulatory requirements relevant to business processes is mostly done manually by domain and legal experts, posing a tremendous effort on them, especially for a large number of regulatory documents which might frequently change. Hence, this work examines how legal and domain experts can be assisted in the assessment of relevant requirements. For this, we compare an embedding-based NLP ranking method, a generative AI method using GPT-4, and a crowdsourced method with the purely manual method of creating relevancy labels by experts. The proposed methods are evaluated based on two case studies: an Australian insurance case created with domain experts and a global banking use case, adapted from SAP Signavio's workflow example of an international guideline. A gold standard is created for both BPMN2.0 processes and matched to real-world textual requirements from multiple regulatory documents. The evaluation and discussion provide insights into strengths and weaknesses of each method regarding applicability, automation, transparency, and reproducibility and provide guidelines on which method combinations will maximize benefits for given characteristics such as process usage, impact, and dynamics of an application scenario.