 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Reliable Process Event Streams and Time Series Data based on Neural Networks
Mar 20, 2021
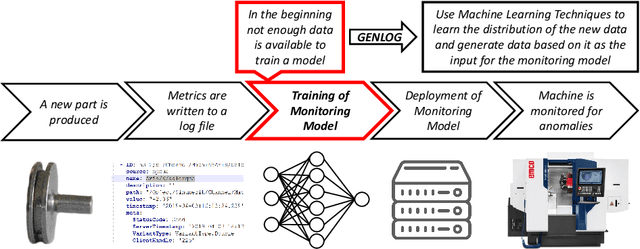

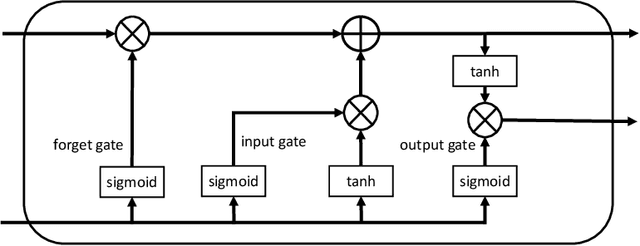
Domains such as manufacturing and medicine crave for continuous monitoring and analysis of their processes, especially in combination with time series as produced by sensors. Time series data can be exploited to, for example, explain and predict concept drifts during runtime. Generally, a certain data volume is required in order to produce meaningful analysis results. However, reliable data sets are often missing, for example, if event streams and times series data are collected separately, in case of a new process, or if it is too expensive to obtain a sufficient data volume. Additional challenges arise with preparing time series data from multiple event sources, variations in data collection frequency, and concept drift. This paper proposes the GENLOG approach to generate reliable event and time series data that follows the distribution of the underlying input data set. GENLOG employs data resampling and enables the user to select different parts of the log data to orchestrate the training of a recurrent neural network for stream generation. The generated data is sampled back to its original sample rate and is embedded into a template representing the log data format it originated from. Overall, GENLOG can boost small data sets and consequently the application of online process mining.