 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKriging prior Regression: A Case for Kriging-Based Spatial Features with TabPFN in Soil Mapping
Sep 11, 2025Machine learning and geostatistics are two fundamentally different frameworks for predicting and spatially mapping soil properties. Geostatistics leverages the spatial structure of soil properties, while machine learning captures the relationship between available environmental features and soil properties. We propose a hybrid framework that enriches ML with spatial context through engineering of 'spatial lag' features from ordinary kriging. We call this approach 'kriging prior regression' (KpR), as it follows the inverse logic of regression kriging. To evaluate this approach, we assessed both the point and probabilistic prediction performance of KpR, using the TabPFN model across six fieldscale datasets from LimeSoDa. These datasets included soil organic carbon, clay content, and pH, along with features derived from remote sensing and in-situ proximal soil sensing. KpR with TabPFN demonstrated reliable uncertainty estimates and more accurate predictions in comparison to several other spatial techniques (e.g., regression/residual kriging with TabPFN), as well as to established non-spatial machine learning algorithms (e.g., random forest). Most notably, it significantly improved the average R2 by around 30% compared to machine learning algorithms without spatial context. This improvement was due to the strong prediction performance of the TabPFN algorithm itself and the complementary spatial information provided by KpR features. TabPFN is particularly effective for prediction tasks with small sample sizes, common in precision agriculture, whereas KpR can compensate for weak relationships between sensing features and soil properties when proximal soil sensing data are limited. Hence, we conclude that KpR with TabPFN is a very robust and versatile modelling framework for digital soil mapping in precision agriculture.
Scaling Up Quantization-Aware Neural Architecture Search for Efficient Deep Learning on the Edge
Jan 22, 2024



Neural Architecture Search (NAS) has become the de-facto approach for designing accurate and efficient networks for edge devices. Since models are typically quantized for edge deployment, recent work has investigated quantization-aware NAS (QA-NAS) to search for highly accurate and efficient quantized models. However, existing QA-NAS approaches, particularly few-bit mixed-precision (FB-MP) methods, do not scale to larger tasks. Consequently, QA-NAS has mostly been limited to low-scale tasks and tiny networks. In this work, we present an approach to enable QA-NAS (INT8 and FB-MP) on large-scale tasks by leveraging the block-wise formulation introduced by block-wise NAS. We demonstrate strong results for the semantic segmentation task on the Cityscapes dataset, finding FB-MP models 33% smaller and INT8 models 17.6% faster than DeepLabV3 (INT8) without compromising task performance.
BOMP-NAS: Bayesian Optimization Mixed Precision NAS
Jan 27, 2023



Bayesian Optimization Mixed-Precision Neural Architecture Search (BOMP-NAS) is an approach to quantization-aware neural architecture search (QA-NAS) that leverages both Bayesian optimization (BO) and mixed-precision quantization (MP) to efficiently search for compact, high performance deep neural networks. The results show that integrating quantization-aware fine-tuning (QAFT) into the NAS loop is a necessary step to find networks that perform well under low-precision quantization: integrating it allows a model size reduction of nearly 50\% on the CIFAR-10 dataset. BOMP-NAS is able to find neural networks that achieve state of the art performance at much lower design costs. This study shows that BOMP-NAS can find these neural networks at a 6x shorter search time compared to the closest related work.
An End-to-End HW/SW Co-Design Methodology to Design Efficient Deep Neural Network Systems using Virtual Models
Nov 18, 2019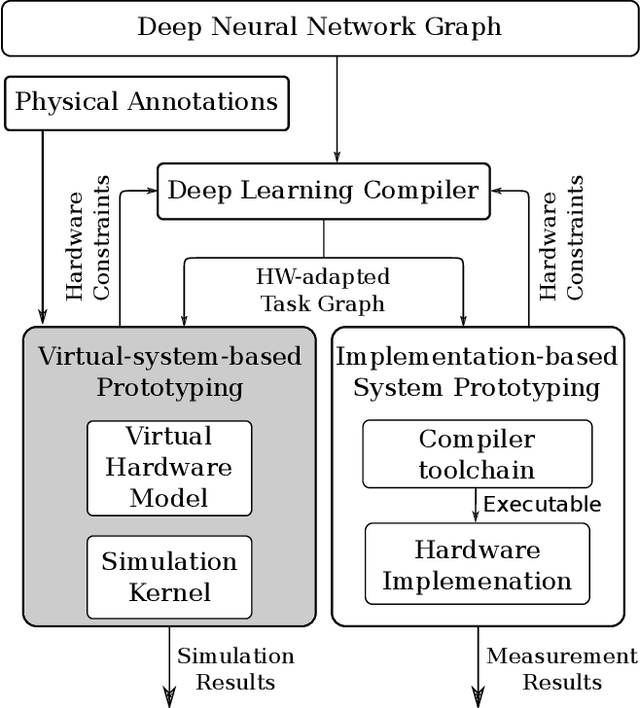
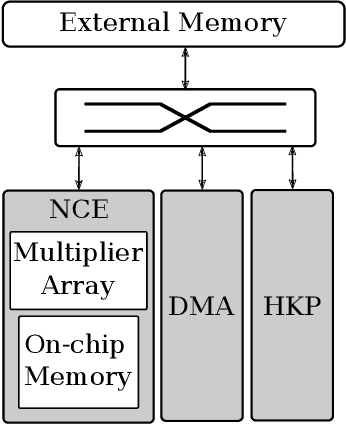
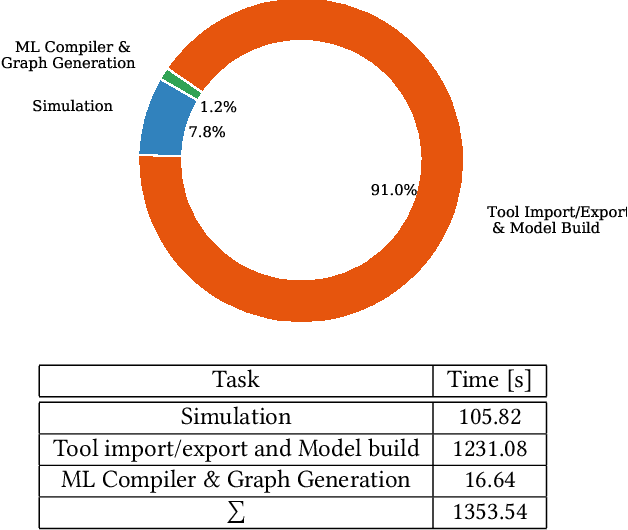
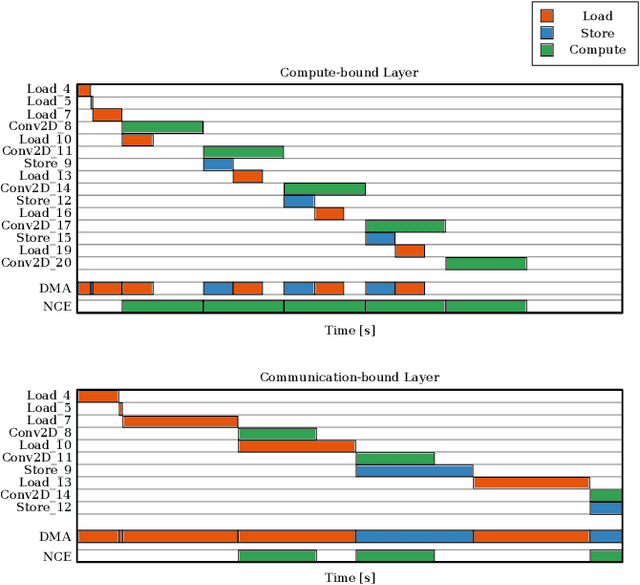
End-to-end performance estimation and measurement of deep neural network (DNN) systems become more important with increasing complexity of DNN systems consisting of hardware and software components. The methodology proposed in this paper aims at a reduced turn-around time for evaluating different design choices of hardware and software components of DNN systems. This reduction is achieved by moving the performance estimation from the implementation phase to the concept phase by employing virtual hardware models instead of gathering measurement results from physical prototypes. Deep learning compilers introduce hardware-specific transformations and are, therefore, considered a part of the design flow of virtual system models to extract end-to-end performance estimations. To validate the run-time accuracy of the proposed methodology, a system processing the DilatedVGG DNN is realized both as virtual system model and as hardware implementation. The results show that up to 92 % accuracy can be reached in predicting the processing time of the DNN inference.
Automated design of error-resilient and hardware-efficient deep neural networks
Sep 30, 2019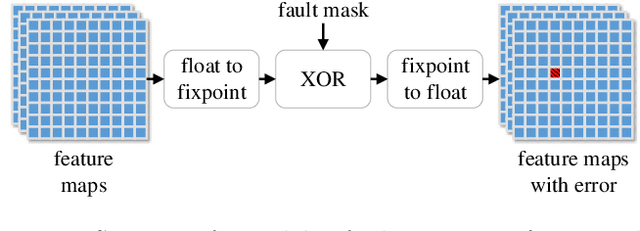
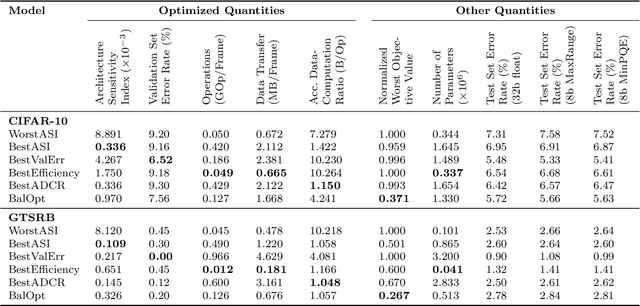
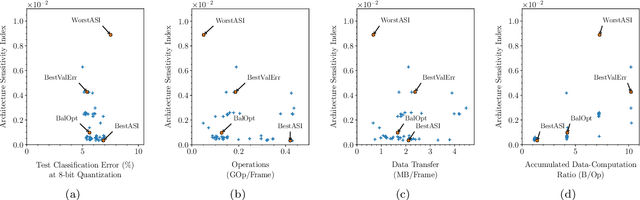
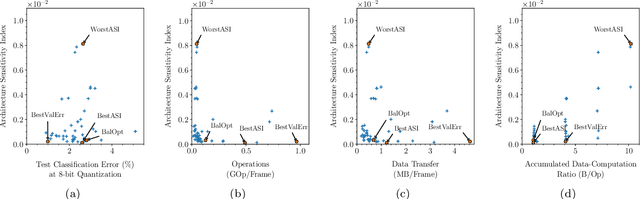
Applying deep neural networks (DNNs) in mobile and safety-critical systems, such as autonomous vehicles, demands a reliable and efficient execution on hardware. Optimized dedicated hardware accelerators are being developed to achieve this. However, the design of efficient and reliable hardware has become increasingly difficult, due to the increased complexity of modern integrated circuit technology and its sensitivity against hardware faults, such as random bit-flips. It is thus desirable to exploit optimization potential for error resilience and efficiency also at the algorithmic side, e.g., by optimizing the architecture of the DNN. Since there are numerous design choices for the architecture of DNNs, with partially opposing effects on the preferred characteristics (such as small error rates at low latency), multi-objective optimization strategies are necessary. In this paper, we develop an evolutionary optimization technique for the automated design of hardware-optimized DNN architectures. For this purpose, we derive a set of easily computable objective functions, which enable the fast evaluation of DNN architectures with respect to their hardware efficiency and error resilience solely based on the network topology. We observe a strong correlation between predicted error resilience and actual measurements obtained from fault injection simulations. Furthermore, we analyze two different quantization schemes for efficient DNN computation and find significant differences regarding their effect on error resilience.
Efficient Stochastic Inference of Bitwise Deep Neural Networks
Nov 20, 2016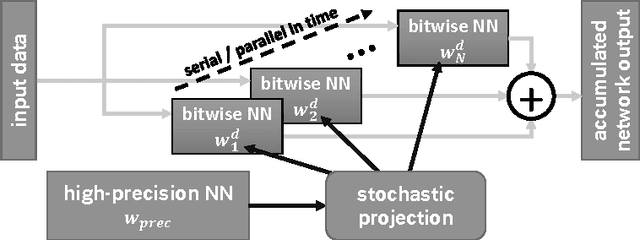
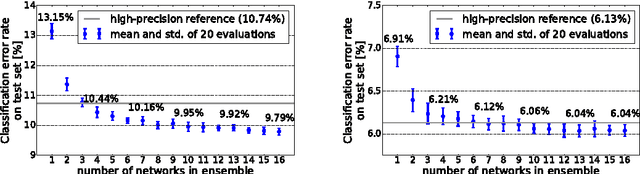
Recently published methods enable training of bitwise neural networks which allow reduced representation of down to a single bit per weight. We present a method that exploits ensemble decisions based on multiple stochastically sampled network models to increase performance figures of bitwise neural networks in terms of classification accuracy at inference. Our experiments with the CIFAR-10 and GTSRB datasets show that the performance of such network ensembles surpasses the performance of the high-precision base model. With this technique we achieve 5.81% best classification error on CIFAR-10 test set using bitwise networks. Concerning inference on embedded systems we evaluate these bitwise networks using a hardware efficient stochastic rounding procedure. Our work contributes to efficient embedded bitwise neural networks.