 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Resource Efficient Fusion Network for Object Detection in Bird's-Eye View using Camera and Raw Radar Data
Nov 20, 2024Cameras can be used to perceive the environment around the vehicle, while affordable radar sensors are popular in autonomous driving systems as they can withstand adverse weather conditions unlike cameras. However, radar point clouds are sparser with low azimuth and elevation resolution that lack semantic and structural information of the scenes, resulting in generally lower radar detection performance. In this work, we directly use the raw range-Doppler (RD) spectrum of radar data, thus avoiding radar signal processing. We independently process camera images within the proposed comprehensive image processing pipeline. Specifically, first, we transform the camera images to Bird's-Eye View (BEV) Polar domain and extract the corresponding features with our camera encoder-decoder architecture. The resultant feature maps are fused with Range-Azimuth (RA) features, recovered from the RD spectrum input from the radar decoder to perform object detection. We evaluate our fusion strategy with other existing methods not only in terms of accuracy but also on computational complexity metrics on RADIal dataset.
Scaling Up Quantization-Aware Neural Architecture Search for Efficient Deep Learning on the Edge
Jan 22, 2024



Neural Architecture Search (NAS) has become the de-facto approach for designing accurate and efficient networks for edge devices. Since models are typically quantized for edge deployment, recent work has investigated quantization-aware NAS (QA-NAS) to search for highly accurate and efficient quantized models. However, existing QA-NAS approaches, particularly few-bit mixed-precision (FB-MP) methods, do not scale to larger tasks. Consequently, QA-NAS has mostly been limited to low-scale tasks and tiny networks. In this work, we present an approach to enable QA-NAS (INT8 and FB-MP) on large-scale tasks by leveraging the block-wise formulation introduced by block-wise NAS. We demonstrate strong results for the semantic segmentation task on the Cityscapes dataset, finding FB-MP models 33% smaller and INT8 models 17.6% faster than DeepLabV3 (INT8) without compromising task performance.
Off-Policy Action Anticipation in Multi-Agent Reinforcement Learning
Apr 04, 2023



Learning anticipation in Multi-Agent Reinforcement Learning (MARL) is a reasoning paradigm where agents anticipate the learning steps of other agents to improve cooperation among themselves. As MARL uses gradient-based optimization, learning anticipation requires using Higher-Order Gradients (HOG), with so-called HOG methods. Existing HOG methods are based on policy parameter anticipation, i.e., agents anticipate the changes in policy parameters of other agents. Currently, however, these existing HOG methods have only been applied to differentiable games or games with small state spaces. In this work, we demonstrate that in the case of non-differentiable games with large state spaces, existing HOG methods do not perform well and are inefficient due to their inherent limitations related to policy parameter anticipation and multiple sampling stages. To overcome these problems, we propose Off-Policy Action Anticipation (OffPA2), a novel framework that approaches learning anticipation through action anticipation, i.e., agents anticipate the changes in actions of other agents, via off-policy sampling. We theoretically analyze our proposed OffPA2 and employ it to develop multiple HOG methods that are applicable to non-differentiable games with large state spaces. We conduct a large set of experiments and illustrate that our proposed HOG methods outperform the existing ones regarding efficiency and performance.
Deep Adaptive Multi-Intention Inverse Reinforcement Learning
Jul 14, 2021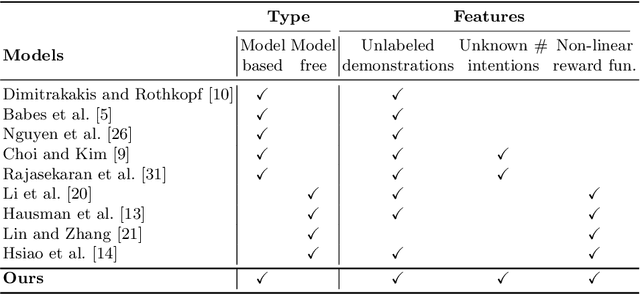
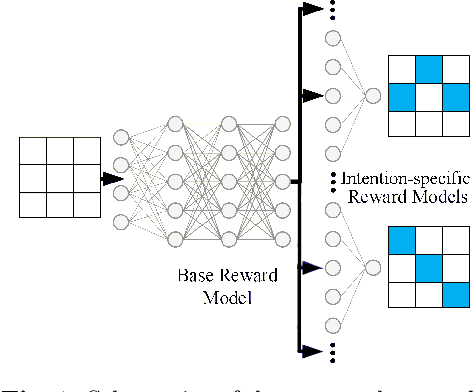
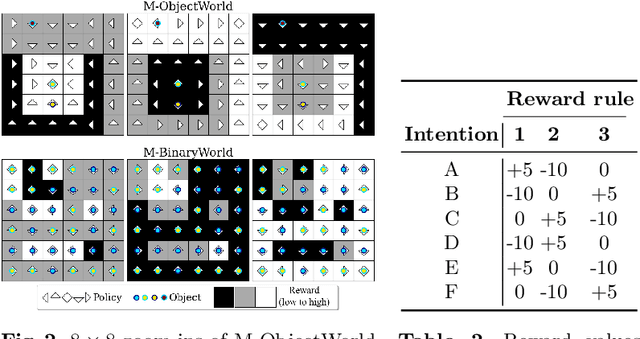

This paper presents a deep Inverse Reinforcement Learning (IRL) framework that can learn an a priori unknown number of nonlinear reward functions from unlabeled experts' demonstrations. For this purpose, we employ the tools from Dirichlet processes and propose an adaptive approach to simultaneously account for both complex and unknown number of reward functions. Using the conditional maximum entropy principle, we model the experts' multi-intention behaviors as a mixture of latent intention distributions and derive two algorithms to estimate the parameters of the deep reward network along with the number of experts' intentions from unlabeled demonstrations. The proposed algorithms are evaluated on three benchmarks, two of which have been specifically extended in this study for multi-intention IRL, and compared with well-known baselines. We demonstrate through several experiments the advantages of our algorithms over the existing approaches and the benefits of online inferring, rather than fixing beforehand, the number of expert's intentions.