 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Frame is Worth One Token: Efficient Generative World Modeling with Delta Tokens
Apr 06, 2026Anticipating diverse future states is a central challenge in video world modeling. Discriminative world models produce a deterministic prediction that implicitly averages over possible futures, while existing generative world models remain computationally expensive. Recent work demonstrates that predicting the future in the feature space of a vision foundation model (VFM), rather than a latent space optimized for pixel reconstruction, requires significantly fewer world model parameters. However, most such approaches remain discriminative. In this work, we introduce DeltaTok, a tokenizer that encodes the VFM feature difference between consecutive frames into a single continuous "delta" token, and DeltaWorld, a generative world model operating on these tokens to efficiently generate diverse plausible futures. Delta tokens reduce video from a three-dimensional spatio-temporal representation to a one-dimensional temporal sequence, for example yielding a 1,024x token reduction with 512x512 frames. This compact representation enables tractable multi-hypothesis training, where many futures are generated in parallel and only the best is supervised. At inference, this leads to diverse predictions in a single forward pass. Experiments on dense forecasting tasks demonstrate that DeltaWorld forecasts futures that more closely align with real-world outcomes, while having over 35x fewer parameters and using 2,000x fewer FLOPs than existing generative world models. Code and weights: https://deltatok.github.io.
PMT: Plain Mask Transformer for Image and Video Segmentation with Frozen Vision Encoders
Mar 26, 2026Vision Foundation Models (VFMs) pre-trained at scale enable a single frozen encoder to serve multiple downstream tasks simultaneously. Recent VFM-based encoder-only models for image and video segmentation, such as EoMT and VidEoMT, achieve competitive accuracy with remarkably low latency, yet they require finetuning the encoder, sacrificing the multi-task encoder sharing that makes VFMs practically attractive for large-scale deployment. To reconcile encoder-only simplicity and speed with frozen VFM features, we propose the Plain Mask Decoder (PMD), a fast Transformer-based segmentation decoder that operates on top of frozen VFM features. The resulting model, the Plain Mask Transformer (PMT), preserves the architectural simplicity and low latency of encoder-only designs while keeping the encoder representation unchanged and shareable. The design seamlessly applies to both image and video segmentation, inheriting the generality of the encoder-only framework. On standard image segmentation benchmarks, PMT matches the frozen-encoder state of the art while running up to ~3x faster. For video segmentation, it even performs on par with fully finetuned methods, while being up to 8x faster than state-of-the-art frozen-encoder models. Code: https://github.com/tue-mps/pmt.
DONUT: A Decoder-Only Model for Trajectory Prediction
Jun 07, 2025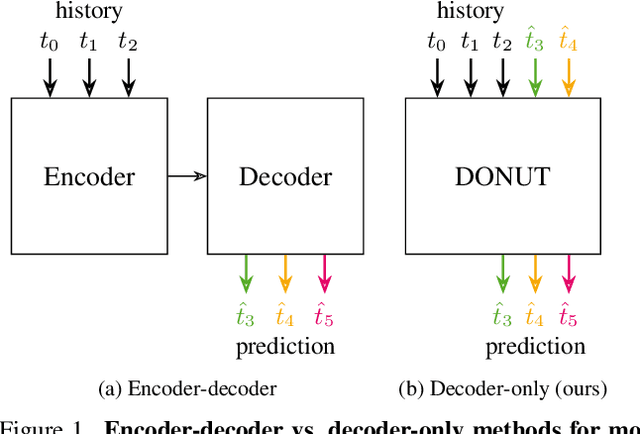

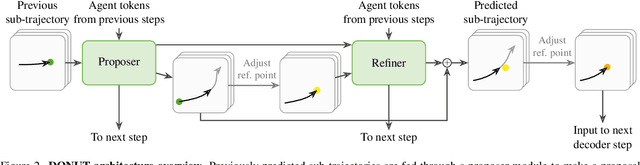
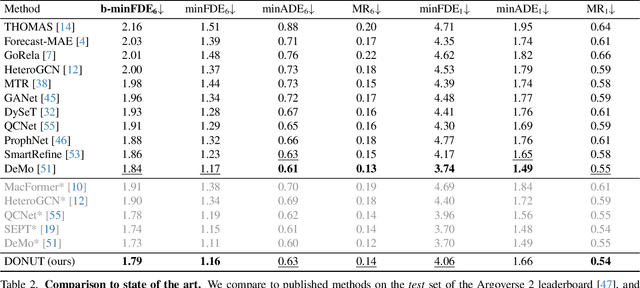
Predicting the motion of other agents in a scene is highly relevant for autonomous driving, as it allows a self-driving car to anticipate. Inspired by the success of decoder-only models for language modeling, we propose DONUT, a Decoder-Only Network for Unrolling Trajectories. Different from existing encoder-decoder forecasting models, we encode historical trajectories and predict future trajectories with a single autoregressive model. This allows the model to make iterative predictions in a consistent manner, and ensures that the model is always provided with up-to-date information, enhancing the performance. Furthermore, inspired by multi-token prediction for language modeling, we introduce an 'overprediction' strategy that gives the network the auxiliary task of predicting trajectories at longer temporal horizons. This allows the model to better anticipate the future, and further improves the performance. With experiments, we demonstrate that our decoder-only approach outperforms the encoder-decoder baseline, and achieves new state-of-the-art results on the Argoverse 2 single-agent motion forecasting benchmark.
How Important are Videos for Training Video LLMs?
Jun 07, 2025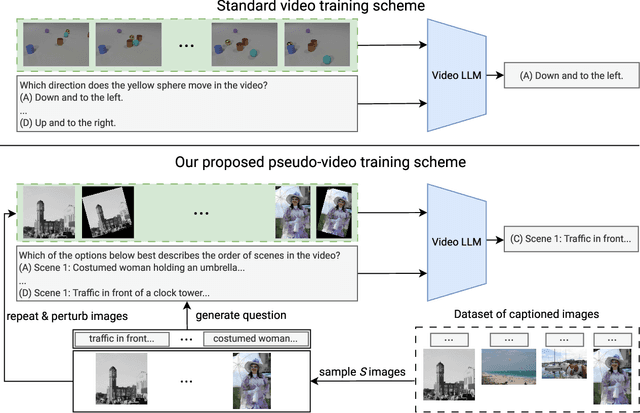

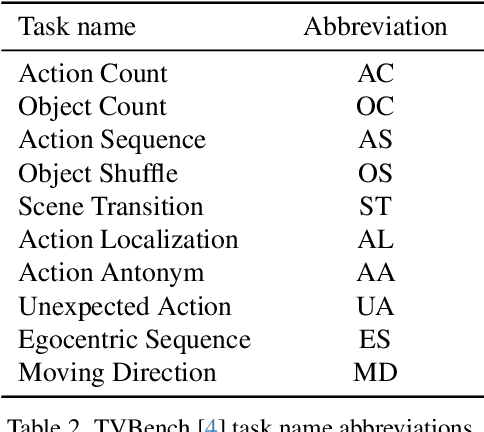
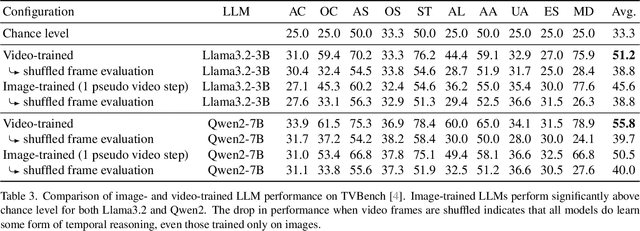
Research into Video Large Language Models (LLMs) has progressed rapidly, with numerous models and benchmarks emerging in just a few years. Typically, these models are initialized with a pretrained text-only LLM and finetuned on both image- and video-caption datasets. In this paper, we present findings indicating that Video LLMs are more capable of temporal reasoning after image-only training than one would assume, and that improvements from video-specific training are surprisingly small. Specifically, we show that image-trained versions of two LLMs trained with the recent LongVU algorithm perform significantly above chance level on TVBench, a temporal reasoning benchmark. Additionally, we introduce a simple finetuning scheme involving sequences of annotated images and questions targeting temporal capabilities. This baseline results in temporal reasoning performance close to, and occasionally higher than, what is achieved by video-trained LLMs. This suggests suboptimal utilization of rich temporal features found in real video by current models. Our analysis motivates further research into the mechanisms that allow image-trained LLMs to perform temporal reasoning, as well as into the bottlenecks that render current video training schemes inefficient.
DINO in the Room: Leveraging 2D Foundation Models for 3D Segmentation
Mar 24, 2025



Vision foundation models (VFMs) trained on large-scale image datasets provide high-quality features that have significantly advanced 2D visual recognition. However, their potential in 3D vision remains largely untapped, despite the common availability of 2D images alongside 3D point cloud datasets. While significant research has been dedicated to 2D-3D fusion, recent state-of-the-art 3D methods predominantly focus on 3D data, leaving the integration of VFMs into 3D models underexplored. In this work, we challenge this trend by introducing DITR, a simple yet effective approach that extracts 2D foundation model features, projects them to 3D, and finally injects them into a 3D point cloud segmentation model. DITR achieves state-of-the-art results on both indoor and outdoor 3D semantic segmentation benchmarks. To enable the use of VFMs even when images are unavailable during inference, we further propose to distill 2D foundation models into a 3D backbone as a pretraining task. By initializing the 3D backbone with knowledge distilled from 2D VFMs, we create a strong basis for downstream 3D segmentation tasks, ultimately boosting performance across various datasets.
Your ViT is Secretly an Image Segmentation Model
Mar 24, 2025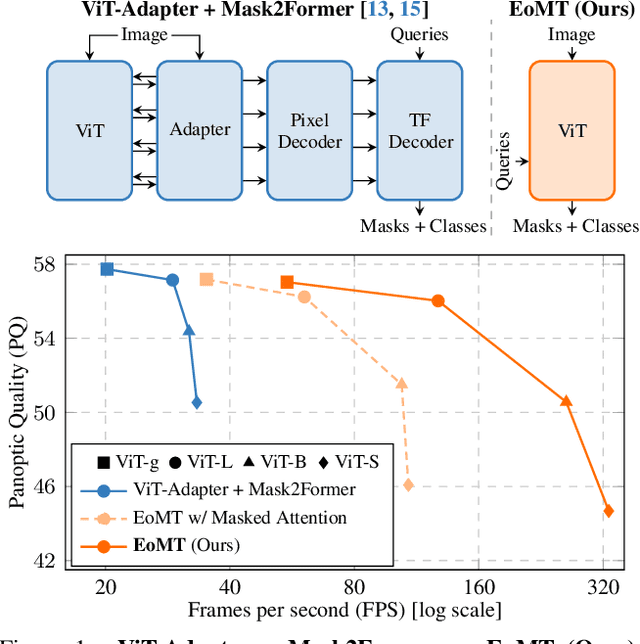
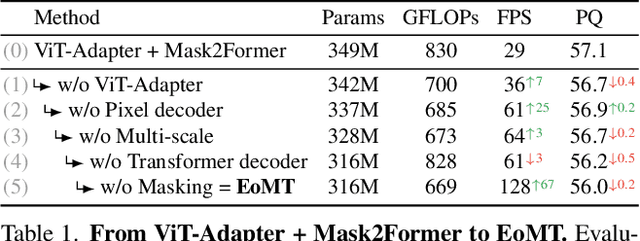
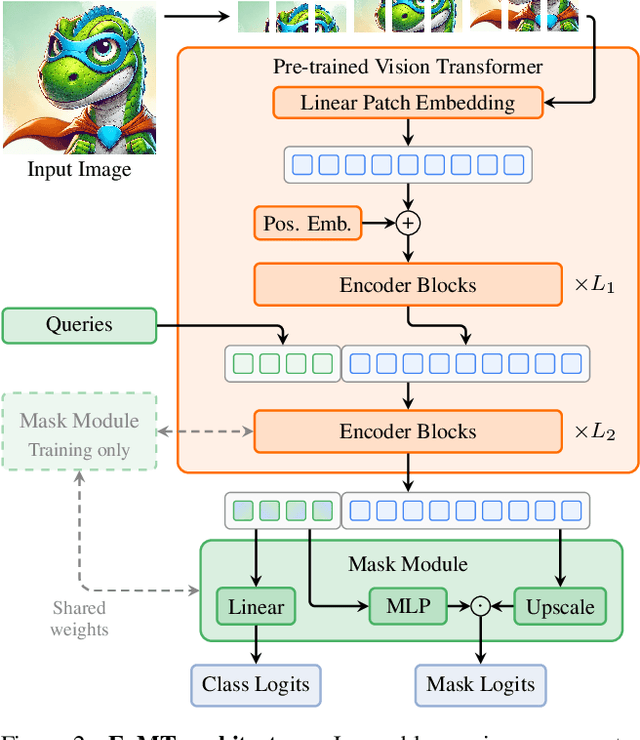
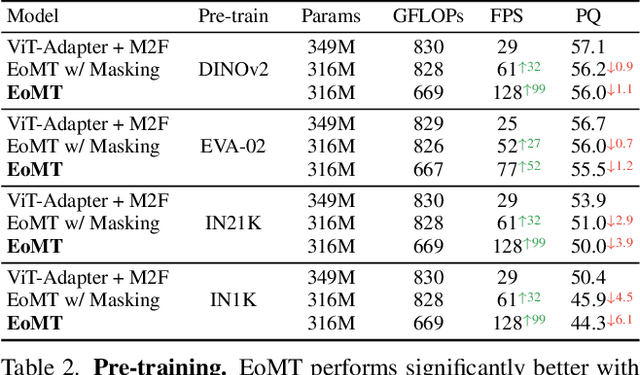
Vision Transformers (ViTs) have shown remarkable performance and scalability across various computer vision tasks. To apply single-scale ViTs to image segmentation, existing methods adopt a convolutional adapter to generate multi-scale features, a pixel decoder to fuse these features, and a Transformer decoder that uses the fused features to make predictions. In this paper, we show that the inductive biases introduced by these task-specific components can instead be learned by the ViT itself, given sufficiently large models and extensive pre-training. Based on these findings, we introduce the Encoder-only Mask Transformer (EoMT), which repurposes the plain ViT architecture to conduct image segmentation. With large-scale models and pre-training, EoMT obtains a segmentation accuracy similar to state-of-the-art models that use task-specific components. At the same time, EoMT is significantly faster than these methods due to its architectural simplicity, e.g., up to 4x faster with ViT-L. Across a range of model sizes, EoMT demonstrates an optimal balance between segmentation accuracy and prediction speed, suggesting that compute resources are better spent on scaling the ViT itself rather than adding architectural complexity. Code: https://www.tue-mps.org/eomt/.
2024 BRAVO Challenge Track 1 1st Place Report: Evaluating Robustness of Vision Foundation Models for Semantic Segmentation
Sep 25, 2024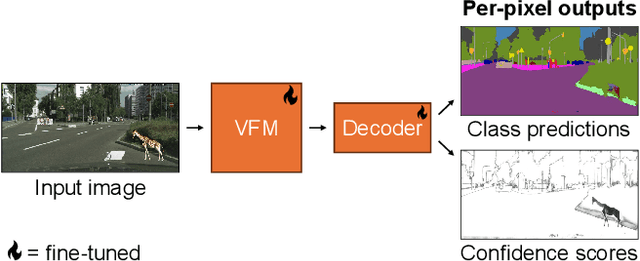



In this report, we present our solution for Track 1 of the 2024 BRAVO Challenge, where a model is trained on Cityscapes and its robustness is evaluated on several out-of-distribution datasets. Our solution leverages the powerful representations learned by vision foundation models, by attaching a simple segmentation decoder to DINOv2 and fine-tuning the entire model. This approach outperforms more complex existing approaches, and achieves 1st place in the challenge. Our code is publicly available at https://github.com/tue-mps/benchmark-vfm-ss.
Fine-Tuning Image-Conditional Diffusion Models is Easier than You Think
Sep 17, 2024



Recent work showed that large diffusion models can be reused as highly precise monocular depth estimators by casting depth estimation as an image-conditional image generation task. While the proposed model achieved state-of-the-art results, high computational demands due to multi-step inference limited its use in many scenarios. In this paper, we show that the perceived inefficiency was caused by a flaw in the inference pipeline that has so far gone unnoticed. The fixed model performs comparably to the best previously reported configuration while being more than 200$\times$ faster. To optimize for downstream task performance, we perform end-to-end fine-tuning on top of the single-step model with task-specific losses and get a deterministic model that outperforms all other diffusion-based depth and normal estimation models on common zero-shot benchmarks. We surprisingly find that this fine-tuning protocol also works directly on Stable Diffusion and achieves comparable performance to current state-of-the-art diffusion-based depth and normal estimation models, calling into question some of the conclusions drawn from prior works.
Exploring the Benefits of Vision Foundation Models for Unsupervised Domain Adaptation
Jun 17, 2024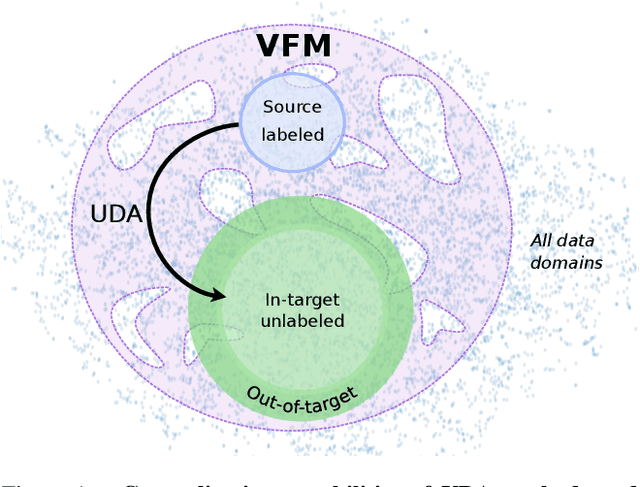
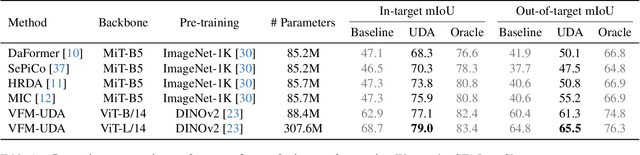
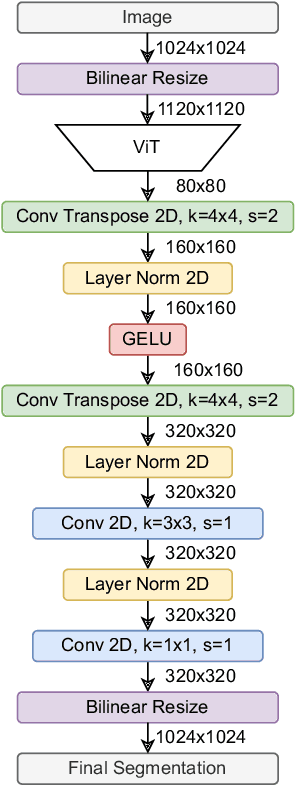
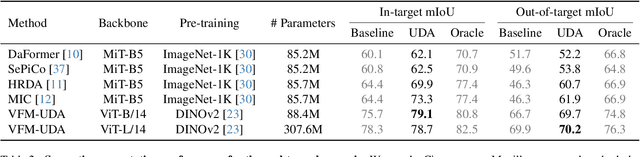
Achieving robust generalization across diverse data domains remains a significant challenge in computer vision. This challenge is important in safety-critical applications, where deep-neural-network-based systems must perform reliably under various environmental conditions not seen during training. Our study investigates whether the generalization capabilities of Vision Foundation Models (VFMs) and Unsupervised Domain Adaptation (UDA) methods for the semantic segmentation task are complementary. Results show that combining VFMs with UDA has two main benefits: (a) it allows for better UDA performance while maintaining the out-of-distribution performance of VFMs, and (b) it makes certain time-consuming UDA components redundant, thus enabling significant inference speedups. Specifically, with equivalent model sizes, the resulting VFM-UDA method achieves an 8.4$\times$ speed increase over the prior non-VFM state of the art, while also improving performance by +1.2 mIoU in the UDA setting and by +6.1 mIoU in terms of out-of-distribution generalization. Moreover, when we use a VFM with 3.6$\times$ more parameters, the VFM-UDA approach maintains a 3.3$\times$ speed up, while improving the UDA performance by +3.1 mIoU and the out-of-distribution performance by +10.3 mIoU. These results underscore the significant benefits of combining VFMs with UDA, setting new standards and baselines for Unsupervised Domain Adaptation in semantic segmentation.
Task-aligned Part-aware Panoptic Segmentation through Joint Object-Part Representations
Jun 14, 2024Part-aware panoptic segmentation (PPS) requires (a) that each foreground object and background region in an image is segmented and classified, and (b) that all parts within foreground objects are segmented, classified and linked to their parent object. Existing methods approach PPS by separately conducting object-level and part-level segmentation. However, their part-level predictions are not linked to individual parent objects. Therefore, their learning objective is not aligned with the PPS task objective, which harms the PPS performance. To solve this, and make more accurate PPS predictions, we propose Task-Aligned Part-aware Panoptic Segmentation (TAPPS). This method uses a set of shared queries to jointly predict (a) object-level segments, and (b) the part-level segments within those same objects. As a result, TAPPS learns to predict part-level segments that are linked to individual parent objects, aligning the learning objective with the task objective, and allowing TAPPS to leverage joint object-part representations. With experiments, we show that TAPPS considerably outperforms methods that predict objects and parts separately, and achieves new state-of-the-art PPS results.