 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to Benchmark Vision Foundation Models for Semantic Segmentation?
Paper and Code
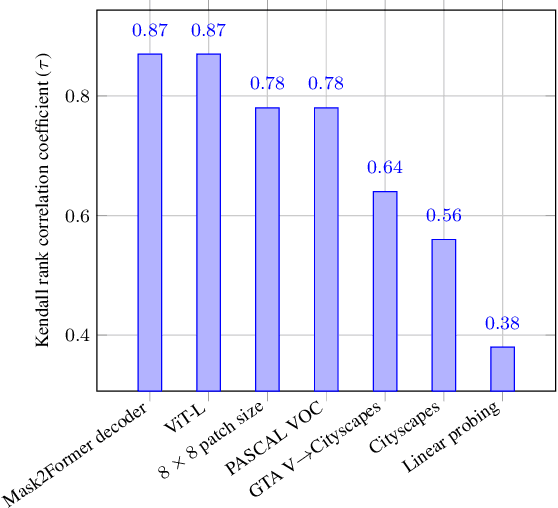
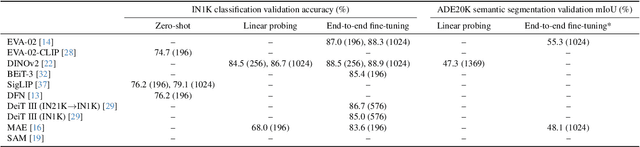

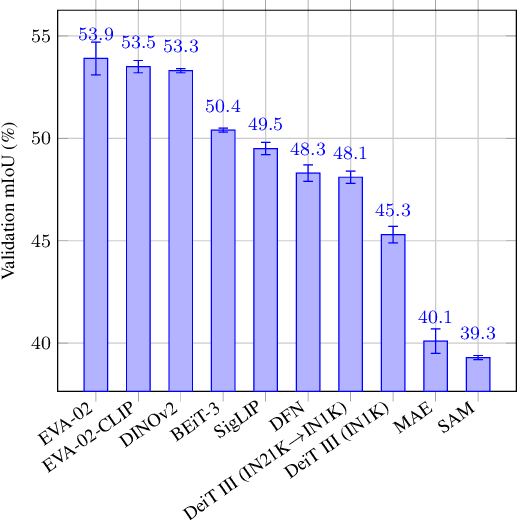
Recent vision foundation models (VFMs) have demonstrated proficiency in various tasks but require supervised fine-tuning to perform the task of semantic segmentation effectively. Benchmarking their performance is essential for selecting current models and guiding future model developments for this task. The lack of a standardized benchmark complicates comparisons. Therefore, the primary objective of this paper is to study how VFMs should be benchmarked for semantic segmentation. To do so, various VFMs are fine-tuned under various settings, and the impact of individual settings on the performance ranking and training time is assessed. Based on the results, the recommendation is to fine-tune the ViT-B variants of VFMs with a 16x16 patch size and a linear decoder, as these settings are representative of using a larger model, more advanced decoder and smaller patch size, while reducing training time by more than 13 times. Using multiple datasets for training and evaluation is also recommended, as the performance ranking across datasets and domain shifts varies. Linear probing, a common practice for some VFMs, is not recommended, as it is not representative of end-to-end fine-tuning. The benchmarking setup recommended in this paper enables a performance analysis of VFMs for semantic segmentation. The findings of such an analysis reveal that pretraining with promptable segmentation is not beneficial, whereas masked image modeling (MIM) with abstract representations is crucial, even more important than the type of supervision used. The code for efficiently fine-tuning VFMs for semantic segmentation can be accessed through the project page at: https://tue-mps.github.io/benchmark-vfm-ss/.