 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Data-Efficient Video Pre-training with Frozen Image Foundation Models
May 18, 2026Video foundation models achieve strong performance across many video understanding tasks, but typically require large-scale pre-training on massive video datasets, resulting in substantial data and compute costs. In contrast, modern image foundation models already provide powerful spatial representations. This raises an important question: can competitive video models be built by reusing these spatial representations and pre-training only for temporal reasoning? We take initial steps toward exploring a lightweight training paradigm that freezes a pre-trained image foundation model and trains only a recurrent temporal module to process streaming video. By reusing an image foundation model as a spatial encoder, this approach could significantly reduce the amount of video data and compute required compared to end-to-end video pre-training. In this work, we explore the feasibility of this approach before investing in computing for video pre-training. Our empirical findings across multiple video understanding tasks suggest that strong temporal performance can emerge without large-scale video pre-training, motivating future work on recurrent video foundation models obtained by pre-training a temporal module on top of a frozen image foundation model. Code: https://github.com/tue-mps/towards-video-image-frozen .
REFNet++: Multi-Task Efficient Fusion of Camera and Radar Sensor Data in Bird's-Eye Polar View
May 12, 2026A realistic view of the vehicle's surroundings is generally offered by camera sensors, which is crucial for environmental perception. Affordable radar sensors, on the other hand, are becoming invaluable due to their robustness in variable weather conditions. However, because of their noisy output and reduced classification capability, they work best when combined with other sensor data. Specifically, we address the challenge of multimodal sensor fusion by aligning radar and camera data in a unified domain, prioritizing not only accuracy, but also computational efficiency. Our work leverages the raw range-Doppler (RD) spectrum from radar and front-view camera images as inputs. To enable effective fusion, we employ a variational encoder-decoder architecture that learns the transformation of front-view camera data into the Bird's-Eye View (BEV) polar domain. Concurrently, a radar encoder-decoder learns to recover the angle information from the RD data that produce Range-Azimuth (RA) features. This alignment ensures that both modalities are represented in a compatible domain, facilitating robust and efficient sensor fusion. We evaluated our fusion strategy for vehicle detection and free space segmentation against state-of-the-art methods using the RADIal dataset.
Revisiting Radar Perception With Spectral Point Clouds
Apr 09, 2026Radar perception models are trained with different inputs, from range-Doppler spectra to sparse point clouds. Dense spectra are assumed to outperform sparse point clouds, yet they can vary considerably across sensors and configurations, which hinders transfer. In this paper, we provide alternatives for incorporating spectral information into radar point clouds and show that, point clouds need not underperform compared to spectra. We introduce the spectral point cloud paradigm, where point clouds are treated as sparse, compressed representations of the radar spectra, and argue that, when enriched with spectral information, they serve as strong candidates for a unified input representation that is more robust against sensor-specific differences. We develop an experimental framework that compares spectral point cloud (PC) models at varying densities against a dense range-Doppler (RD) benchmark, and report the density levels where the PC configurations meet the performance of the RD benchmark. Furthermore, we experiment with two basic spectral enrichment approaches, that inject additional target-relevant information into the point clouds. Contrary to the common belief that the dense RD approach is superior, we show that point clouds can do just as well, and can surpass the RD benchmark when enrichment is applied. Spectral point clouds can therefore serve as strong candidates for unified radar perception, paving the way for future radar foundation models.
Orion-Lite: Distilling LLM Reasoning into Efficient Vision-Only Driving Models
Apr 09, 2026Leveraging the general world knowledge of Large Language Models (LLMs) holds significant promise for improving the ability of autonomous driving systems to handle rare and complex scenarios. While integrating LLMs into Vision-Language-Action (VLA) models has yielded state-of-the-art performance, their massive parameter counts pose severe challenges for latency-sensitive and energy-efficient deployment. Distilling LLM knowledge into a compact driving model offers a compelling solution to retain these reasoning capabilities while maintaining a manageable computational footprint. Although previous works have demonstrated the efficacy of distillation, these efforts have primarily focused on relatively simple scenarios and open-loop evaluations. Therefore, in this work, we investigate LLM distillation in more complex, interactive scenarios under closed-loop evaluation. We demonstrate that through a combination of latent feature distillation and ground-truth trajectory supervision, an efficient vision-only student model \textbf{Orion-Lite} can even surpass the performance of its massive VLA teacher, ORION. Setting a new state-of-the-art on the rigorous Bench2Drive benchmark, with a Driving Score of 80.6. Ultimately, this reveals that vision-only architectures still possess significant, untapped potential for high-performance reactive planning.
A Frame is Worth One Token: Efficient Generative World Modeling with Delta Tokens
Apr 06, 2026Anticipating diverse future states is a central challenge in video world modeling. Discriminative world models produce a deterministic prediction that implicitly averages over possible futures, while existing generative world models remain computationally expensive. Recent work demonstrates that predicting the future in the feature space of a vision foundation model (VFM), rather than a latent space optimized for pixel reconstruction, requires significantly fewer world model parameters. However, most such approaches remain discriminative. In this work, we introduce DeltaTok, a tokenizer that encodes the VFM feature difference between consecutive frames into a single continuous "delta" token, and DeltaWorld, a generative world model operating on these tokens to efficiently generate diverse plausible futures. Delta tokens reduce video from a three-dimensional spatio-temporal representation to a one-dimensional temporal sequence, for example yielding a 1,024x token reduction with 512x512 frames. This compact representation enables tractable multi-hypothesis training, where many futures are generated in parallel and only the best is supervised. At inference, this leads to diverse predictions in a single forward pass. Experiments on dense forecasting tasks demonstrate that DeltaWorld forecasts futures that more closely align with real-world outcomes, while having over 35x fewer parameters and using 2,000x fewer FLOPs than existing generative world models. Code and weights: https://deltatok.github.io.
PMT: Plain Mask Transformer for Image and Video Segmentation with Frozen Vision Encoders
Mar 26, 2026Vision Foundation Models (VFMs) pre-trained at scale enable a single frozen encoder to serve multiple downstream tasks simultaneously. Recent VFM-based encoder-only models for image and video segmentation, such as EoMT and VidEoMT, achieve competitive accuracy with remarkably low latency, yet they require finetuning the encoder, sacrificing the multi-task encoder sharing that makes VFMs practically attractive for large-scale deployment. To reconcile encoder-only simplicity and speed with frozen VFM features, we propose the Plain Mask Decoder (PMD), a fast Transformer-based segmentation decoder that operates on top of frozen VFM features. The resulting model, the Plain Mask Transformer (PMT), preserves the architectural simplicity and low latency of encoder-only designs while keeping the encoder representation unchanged and shareable. The design seamlessly applies to both image and video segmentation, inheriting the generality of the encoder-only framework. On standard image segmentation benchmarks, PMT matches the frozen-encoder state of the art while running up to ~3x faster. For video segmentation, it even performs on par with fully finetuned methods, while being up to 8x faster than state-of-the-art frozen-encoder models. Code: https://github.com/tue-mps/pmt.
What is the Added Value of UDA in the VFM Era?
Apr 25, 2025Unsupervised Domain Adaptation (UDA) can improve a perception model's generalization to an unlabeled target domain starting from a labeled source domain. UDA using Vision Foundation Models (VFMs) with synthetic source data can achieve generalization performance comparable to fully-supervised learning with real target data. However, because VFMs have strong generalization from their pre-training, more straightforward, source-only fine-tuning can also perform well on the target. As data scenarios used in academic research are not necessarily representative for real-world applications, it is currently unclear (a) how UDA behaves with more representative and diverse data and (b) if source-only fine-tuning of VFMs can perform equally well in these scenarios. Our research aims to close these gaps and, similar to previous studies, we focus on semantic segmentation as a representative perception task. We assess UDA for synth-to-real and real-to-real use cases with different source and target data combinations. We also investigate the effect of using a small amount of labeled target data in UDA. We clarify that while these scenarios are more realistic, they are not necessarily more challenging. Our results show that, when using stronger synthetic source data, UDA's improvement over source-only fine-tuning of VFMs reduces from +8 mIoU to +2 mIoU, and when using more diverse real source data, UDA has no added value. However, UDA generalization is always higher in all synthetic data scenarios than source-only fine-tuning and, when including only 1/16 of Cityscapes labels, synthetic UDA obtains the same state-of-the-art segmentation quality of 85 mIoU as a fully-supervised model using all labels. Considering the mixed results, we discuss how UDA can best support robust autonomous driving at scale.
Your ViT is Secretly an Image Segmentation Model
Mar 24, 2025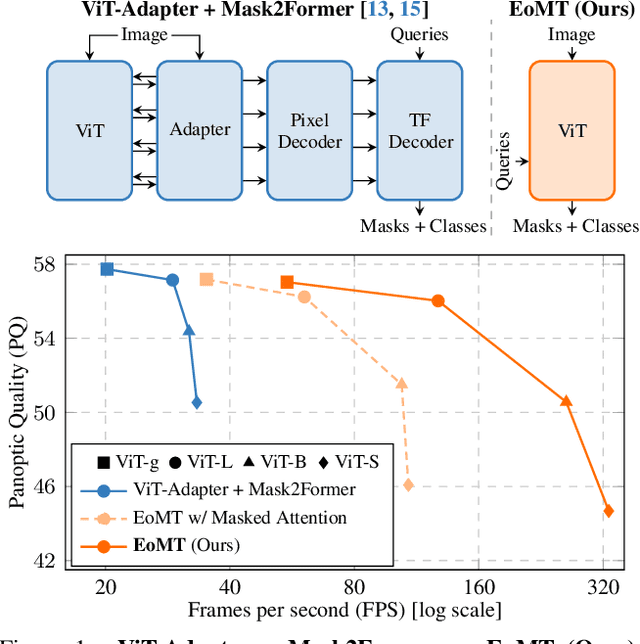
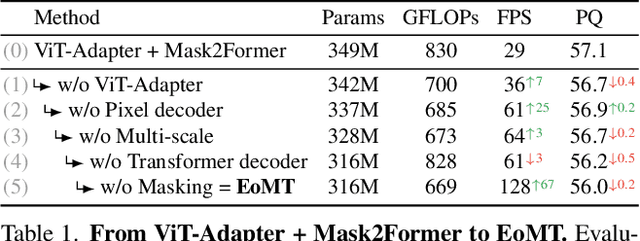
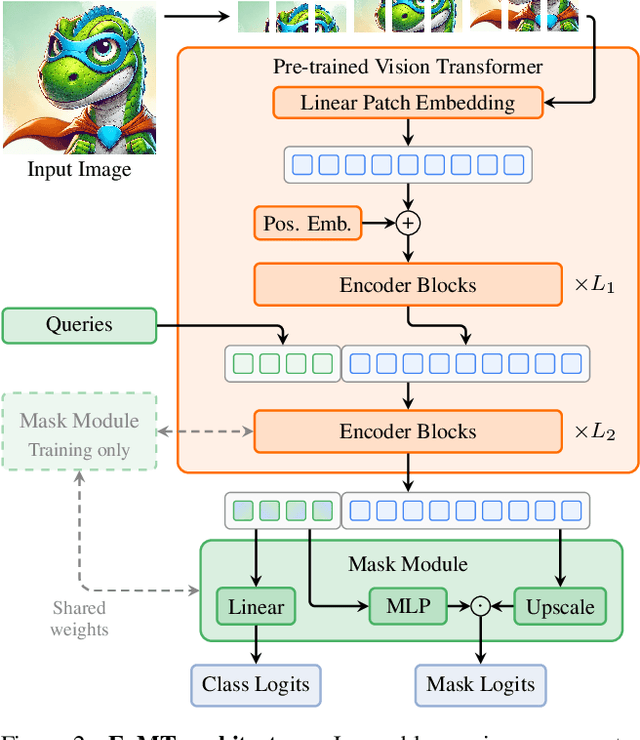
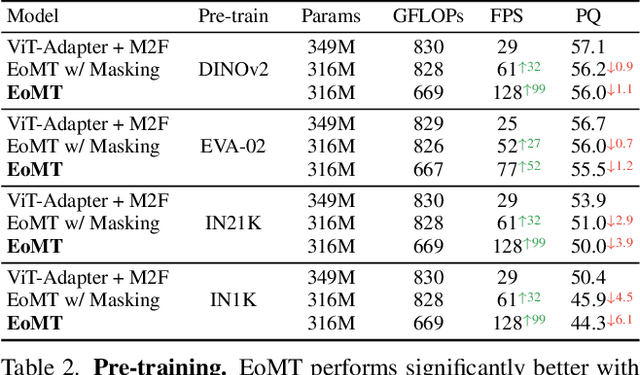
Vision Transformers (ViTs) have shown remarkable performance and scalability across various computer vision tasks. To apply single-scale ViTs to image segmentation, existing methods adopt a convolutional adapter to generate multi-scale features, a pixel decoder to fuse these features, and a Transformer decoder that uses the fused features to make predictions. In this paper, we show that the inductive biases introduced by these task-specific components can instead be learned by the ViT itself, given sufficiently large models and extensive pre-training. Based on these findings, we introduce the Encoder-only Mask Transformer (EoMT), which repurposes the plain ViT architecture to conduct image segmentation. With large-scale models and pre-training, EoMT obtains a segmentation accuracy similar to state-of-the-art models that use task-specific components. At the same time, EoMT is significantly faster than these methods due to its architectural simplicity, e.g., up to 4x faster with ViT-L. Across a range of model sizes, EoMT demonstrates an optimal balance between segmentation accuracy and prediction speed, suggesting that compute resources are better spent on scaling the ViT itself rather than adding architectural complexity. Code: https://www.tue-mps.org/eomt/.
A Resource Efficient Fusion Network for Object Detection in Bird's-Eye View using Camera and Raw Radar Data
Nov 20, 2024



Cameras can be used to perceive the environment around the vehicle, while affordable radar sensors are popular in autonomous driving systems as they can withstand adverse weather conditions unlike cameras. However, radar point clouds are sparser with low azimuth and elevation resolution that lack semantic and structural information of the scenes, resulting in generally lower radar detection performance. In this work, we directly use the raw range-Doppler (RD) spectrum of radar data, thus avoiding radar signal processing. We independently process camera images within the proposed comprehensive image processing pipeline. Specifically, first, we transform the camera images to Bird's-Eye View (BEV) Polar domain and extract the corresponding features with our camera encoder-decoder architecture. The resultant feature maps are fused with Range-Azimuth (RA) features, recovered from the RD spectrum input from the radar decoder to perform object detection. We evaluate our fusion strategy with other existing methods not only in terms of accuracy but also on computational complexity metrics on RADIal dataset.
2024 BRAVO Challenge Track 1 1st Place Report: Evaluating Robustness of Vision Foundation Models for Semantic Segmentation
Sep 25, 2024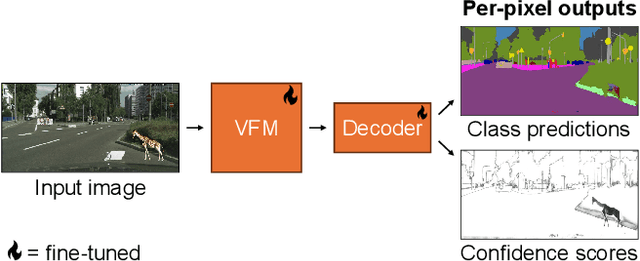



In this report, we present our solution for Track 1 of the 2024 BRAVO Challenge, where a model is trained on Cityscapes and its robustness is evaluated on several out-of-distribution datasets. Our solution leverages the powerful representations learned by vision foundation models, by attaching a simple segmentation decoder to DINOv2 and fine-tuning the entire model. This approach outperforms more complex existing approaches, and achieves 1st place in the challenge. Our code is publicly available at https://github.com/tue-mps/benchmark-vfm-ss.