 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREFNet++: Multi-Task Efficient Fusion of Camera and Radar Sensor Data in Bird's-Eye Polar View
May 12, 2026A realistic view of the vehicle's surroundings is generally offered by camera sensors, which is crucial for environmental perception. Affordable radar sensors, on the other hand, are becoming invaluable due to their robustness in variable weather conditions. However, because of their noisy output and reduced classification capability, they work best when combined with other sensor data. Specifically, we address the challenge of multimodal sensor fusion by aligning radar and camera data in a unified domain, prioritizing not only accuracy, but also computational efficiency. Our work leverages the raw range-Doppler (RD) spectrum from radar and front-view camera images as inputs. To enable effective fusion, we employ a variational encoder-decoder architecture that learns the transformation of front-view camera data into the Bird's-Eye View (BEV) polar domain. Concurrently, a radar encoder-decoder learns to recover the angle information from the RD data that produce Range-Azimuth (RA) features. This alignment ensures that both modalities are represented in a compatible domain, facilitating robust and efficient sensor fusion. We evaluated our fusion strategy for vehicle detection and free space segmentation against state-of-the-art methods using the RADIal dataset.
LoopDB: A Loop Closure Dataset for Large Scale Simultaneous Localization and Mapping
Jun 07, 2025



In this study, we introduce LoopDB, which is a challenging loop closure dataset comprising over 1000 images captured across diverse environments, including parks, indoor scenes, parking spaces, as well as centered around individual objects. Each scene is represented by a sequence of five consecutive images. The dataset was collected using a high resolution camera, providing suitable imagery for benchmarking the accuracy of loop closure algorithms, typically used in simultaneous localization and mapping. As ground truth information, we provide computed rotations and translations between each consecutive images. Additional to its benchmarking goal, the dataset can be used to train and fine-tune loop closure methods based on deep neural networks. LoopDB is publicly available at https://github.com/RovisLab/LoopDB.
Inverse RL Scene Dynamics Learning for Nonlinear Predictive Control in Autonomous Vehicles
Apr 02, 2025



This paper introduces the Deep Learning-based Nonlinear Model Predictive Controller with Scene Dynamics (DL-NMPC-SD) method for autonomous navigation. DL-NMPC-SD uses an a-priori nominal vehicle model in combination with a scene dynamics model learned from temporal range sensing information. The scene dynamics model is responsible for estimating the desired vehicle trajectory, as well as to adjust the true system model used by the underlying model predictive controller. We propose to encode the scene dynamics model within the layers of a deep neural network, which acts as a nonlinear approximator for the high order state-space of the operating conditions. The model is learned based on temporal sequences of range sensing observations and system states, both integrated by an Augmented Memory component. We use Inverse Reinforcement Learning and the Bellman optimality principle to train our learning controller with a modified version of the Deep Q-Learning algorithm, enabling us to estimate the desired state trajectory as an optimal action-value function. We have evaluated DL-NMPC-SD against the baseline Dynamic Window Approach (DWA), as well as against two state-of-the-art End2End and reinforcement learning methods, respectively. The performance has been measured in three experiments: i) in our GridSim virtual environment, ii) on indoor and outdoor navigation tasks using our RovisLab AMTU (Autonomous Mobile Test Unit) platform and iii) on a full scale autonomous test vehicle driving on public roads.
* 21 pages, 14 figures, journal paper
A Resource Efficient Fusion Network for Object Detection in Bird's-Eye View using Camera and Raw Radar Data
Nov 20, 2024



Cameras can be used to perceive the environment around the vehicle, while affordable radar sensors are popular in autonomous driving systems as they can withstand adverse weather conditions unlike cameras. However, radar point clouds are sparser with low azimuth and elevation resolution that lack semantic and structural information of the scenes, resulting in generally lower radar detection performance. In this work, we directly use the raw range-Doppler (RD) spectrum of radar data, thus avoiding radar signal processing. We independently process camera images within the proposed comprehensive image processing pipeline. Specifically, first, we transform the camera images to Bird's-Eye View (BEV) Polar domain and extract the corresponding features with our camera encoder-decoder architecture. The resultant feature maps are fused with Range-Azimuth (RA) features, recovered from the RD spectrum input from the radar decoder to perform object detection. We evaluate our fusion strategy with other existing methods not only in terms of accuracy but also on computational complexity metrics on RADIal dataset.
CyberCortex.AI: An AI-based Operating System for Autonomous Robotics and Complex Automation
Sep 02, 2024The underlying framework for controlling autonomous robots and complex automation applications are Operating Systems (OS) capable of scheduling perception-and-control tasks, as well as providing real-time data communication to other robotic peers and remote cloud computers. In this paper, we introduce CyberCortex.AI, a robotics OS designed to enable heterogeneous AI-based robotics and complex automation applications. CyberCortex.AI is a decentralized distributed OS which enables robots to talk to each other, as well as to High Performance Computers (HPC) in the cloud. Sensory and control data from the robots is streamed towards HPC systems with the purpose of training AI algorithms, which are afterwards deployed on the robots. Each functionality of a robot (e.g. sensory data acquisition, path planning, motion control, etc.) is executed within a so-called DataBlock of Filters shared through the internet, where each filter is computed either locally on the robot itself, or remotely on a different robotic system. The data is stored and accessed via a so-called \textit{Temporal Addressable Memory} (TAM), which acts as a gateway between each filter's input and output. CyberCortex.AI has two main components: i) the CyberCortex.AI.inference system, which is a real-time implementation of the DataBlock running on the robots' embedded hardware, and ii) the CyberCortex.AI.dojo, which runs on an HPC computer in the cloud, and it is used to design, train and deploy AI algorithms. We present a quantitative and qualitative performance analysis of the proposed approach using two collaborative robotics applications: \textit{i}) a forest fires prevention system based on an Unitree A1 legged robot and an Anafi Parrot 4K drone, as well as \textit{ii}) an autonomous driving system which uses CyberCortex.AI for collaborative perception and motion control.
ObserveNet Control: A Vision-Dynamics Learning Approach to Predictive Control in Autonomous Vehicles
Jul 19, 2021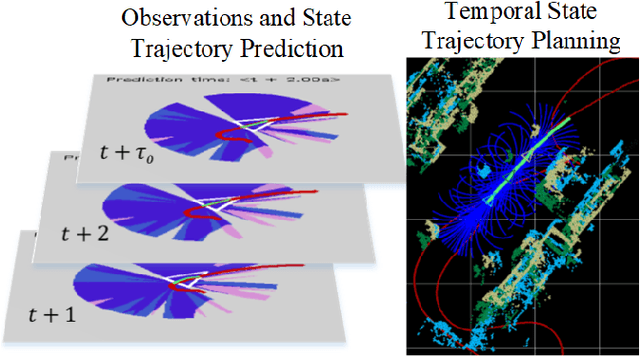
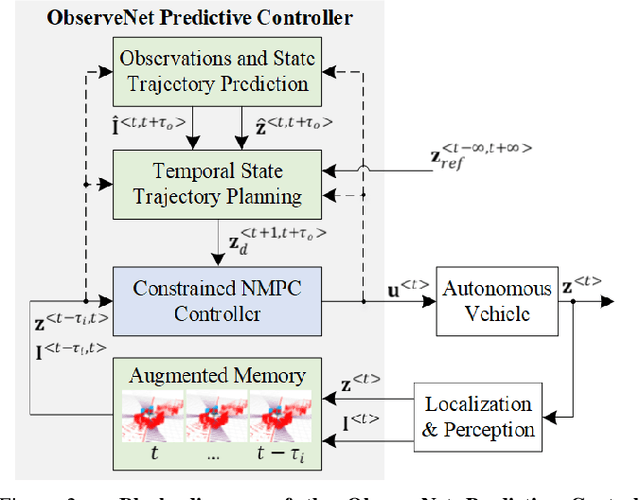
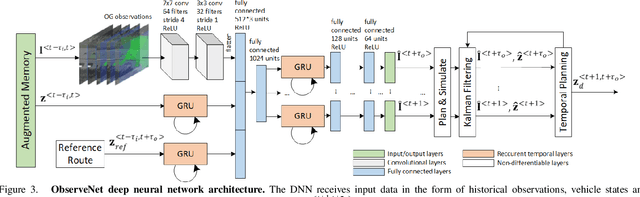
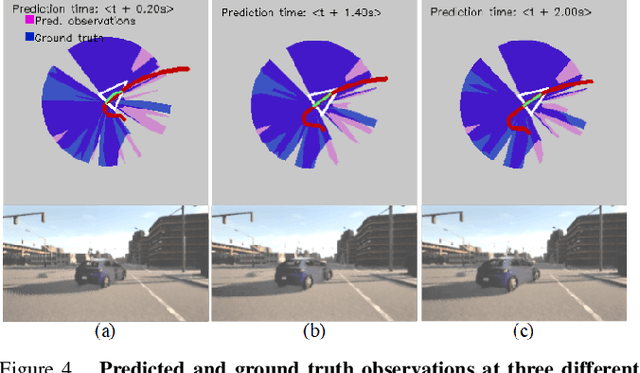
A key component in autonomous driving is the ability of the self-driving car to understand, track and predict the dynamics of the surrounding environment. Although there is significant work in the area of object detection, tracking and observations prediction, there is no prior work demonstrating that raw observations prediction can be used for motion planning and control. In this paper, we propose ObserveNet Control, which is a vision-dynamics approach to the predictive control problem of autonomous vehicles. Our method is composed of a: i) deep neural network able to confidently predict future sensory data on a time horizon of up to 10s and ii) a temporal planner designed to compute a safe vehicle state trajectory based on the predicted sensory data. Given the vehicle's historical state and sensing data in the form of Lidar point clouds, the method aims to learn the dynamics of the observed driving environment in a self-supervised manner, without the need to manually specify training labels. The experiments are performed both in simulation and real-life, using CARLA and RovisLab's AMTU mobile platform as a 1:4 scaled model of a car. We evaluate the capabilities of ObserveNet Control in aggressive driving contexts, such as overtaking maneuvers or side cut-off situations, while comparing the results with a baseline Dynamic Window Approach (DWA) and two state-of-the-art imitation learning systems, that is, Learning by Cheating (LBC) and World on Rails (WOR).
OctoPath: An OcTree Based Self-Supervised Learning Approach to Local Trajectory Planning for Mobile Robots
Jun 02, 2021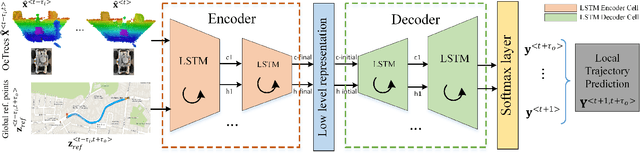
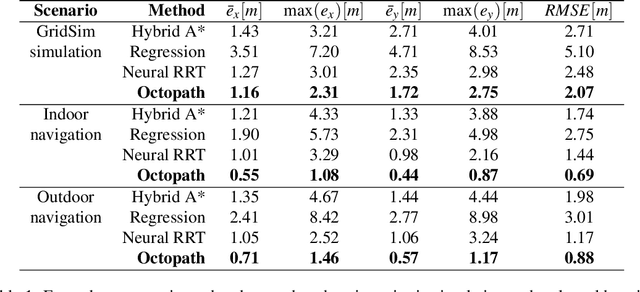
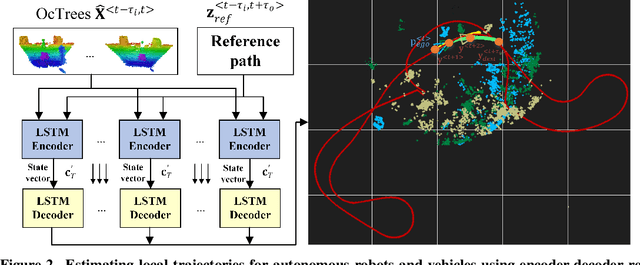

Autonomous mobile robots are usually faced with challenging situations when driving in complex environments. Namely, they have to recognize the static and dynamic obstacles, plan the driving path and execute their motion. For addressing the issue of perception and path planning, in this paper, we introduce OctoPath , which is an encoder-decoder deep neural network, trained in a self-supervised manner to predict the local optimal trajectory for the ego-vehicle. Using the discretization provided by a 3D octree environment model, our approach reformulates trajectory prediction as a classification problem with a configurable resolution. During training, OctoPath minimizes the error between the predicted and the manually driven trajectories in a given training dataset. This allows us to avoid the pitfall of regression-based trajectory estimation, in which there is an infinite state space for the output trajectory points. Environment sensing is performed using a 40-channel mechanical LiDAR sensor, fused with an inertial measurement unit and wheels odometry for state estimation. The experiments are performed both in simulation and real-life, using our own developed GridSim simulator and RovisLab's Autonomous Mobile Test Unit platform. We evaluate the predictions of OctoPath in different driving scenarios, both indoor and outdoor, while benchmarking our system against a baseline hybrid A-Star algorithm and a regression-based supervised learning method, as well as against a CNN learning-based optimal path planning method.
LVD-NMPC: A Learning-based Vision Dynamics Approach to Nonlinear Model Predictive Control for Autonomous Vehicles
May 27, 2021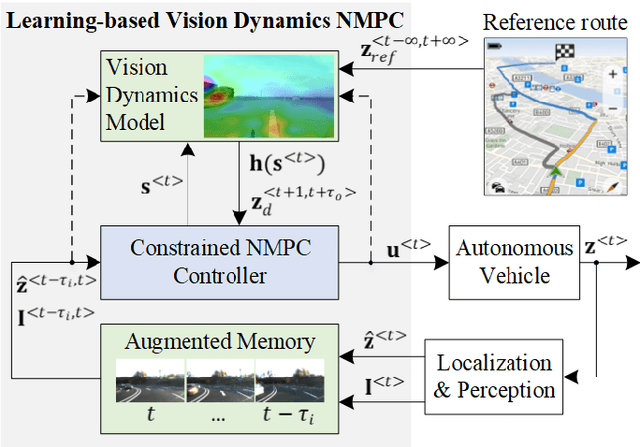
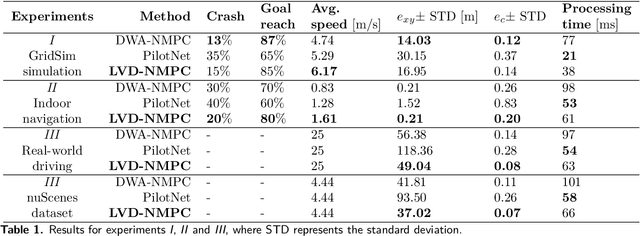

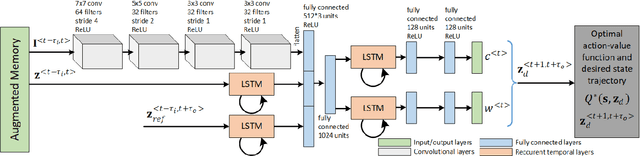
In this paper, we introduce a learning-based vision dynamics approach to nonlinear model predictive control for autonomous vehicles, coined LVD-NMPC. LVD-NMPC uses an a-priori process model and a learned vision dynamics model used to calculate the dynamics of the driving scene, the controlled system's desired state trajectory and the weighting gains of the quadratic cost function optimized by a constrained predictive controller. The vision system is defined as a deep neural network designed to estimate the dynamics of the images scene. The input is based on historic sequences of sensory observations and vehicle states, integrated by an Augmented Memory component. Deep Q-Learning is used to train the deep network, which once trained can be used to also calculate the desired trajectory of the vehicle. We evaluate LVD-NMPC against a baseline Dynamic Window Approach (DWA) path planning executed using standard NMPC, as well as against the PilotNet neural network. Performance is measured in our simulation environment GridSim, on a real-world 1:8 scaled model car, as well as on a real size autonomous test vehicle and the nuScenes computer vision dataset.
Embedded Vision for Self-Driving on Forest Roads
May 27, 2021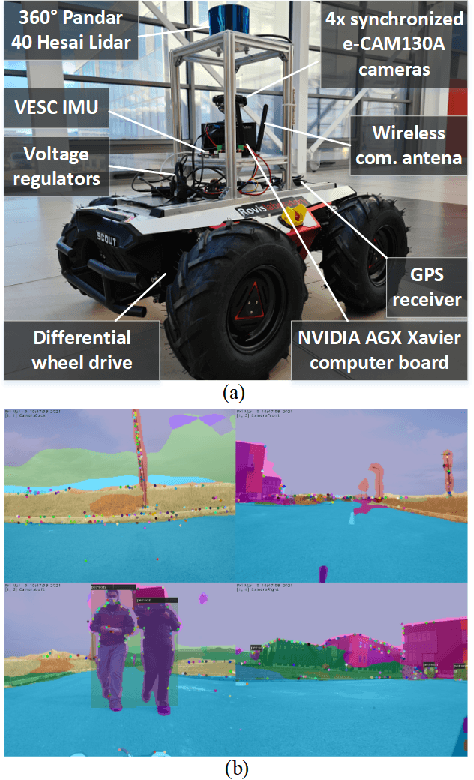


Forest roads in Romania are unique natural wildlife sites used for recreation by countless tourists. In order to protect and maintain these roads, we propose RovisLab AMTU (Autonomous Mobile Test Unit), which is a robotic system designed to autonomously navigate off-road terrain and inspect if any deforestation or damage occurred along tracked route. AMTU's core component is its embedded vision module, optimized for real-time environment perception. For achieving a high computation speed, we use a learning system to train a multi-task Deep Neural Network (DNN) for scene and instance segmentation of objects, while the keypoints required for simultaneous localization and mapping are calculated using a handcrafted FAST feature detector and the Lucas-Kanade tracking algorithm. Both the DNN and the handcrafted backbone are run in parallel on the GPU of an NVIDIA AGX Xavier board. We show experimental results on the test track of our research facility.
Cloud2Edge Elastic AI Framework for Prototyping and Deployment of AI Inference Engines in Autonomous Vehicles
Sep 23, 2020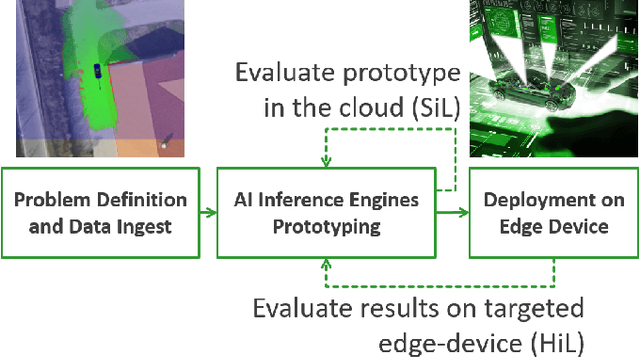
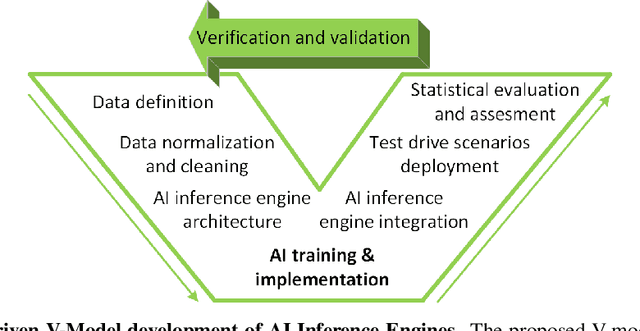
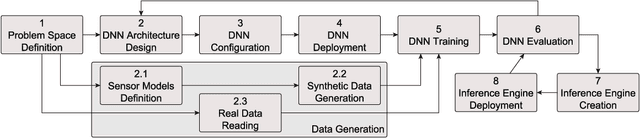
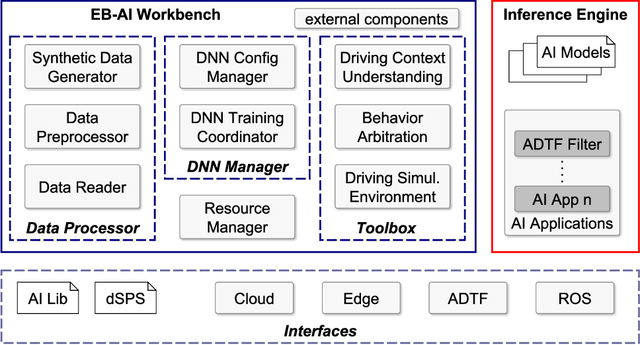
Self-driving cars and autonomous vehicles are revolutionizing the automotive sector, shaping the future of mobility altogether. Although the integration of novel technologies such as Artificial Intelligence (AI) and Cloud/Edge computing provides golden opportunities to improve autonomous driving applications, there is the need to modernize accordingly the whole prototyping and deployment cycle of AI components. This paper proposes a novel framework for developing so-called AI Inference Engines for autonomous driving applications based on deep learning modules, where training tasks are deployed elastically over both Cloud and Edge resources, with the purpose of reducing the required network bandwidth, as well as mitigating privacy issues. Based on our proposed data driven V-Model, we introduce a simple yet elegant solution for the AI components development cycle, where prototyping takes place in the cloud according to the Software-in-the-Loop (SiL) paradigm, while deployment and evaluation on the target ECUs (Electronic Control Units) is performed as Hardware-in-the-Loop (HiL) testing. The effectiveness of the proposed framework is demonstrated using two real-world use-cases of AI inference engines for autonomous vehicles, that is environment perception and most probable path prediction.