 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA BlueROV2-based platform for underwater mapping experiments
Jul 15, 2024We propose a low-cost laboratory platform for development and validation of underwater mapping techniques, using the BlueROV2 Remotely Operated Vehicle (ROV). Both the ROV and the objects to be mapped are placed in a pool that is imaged via an overhead camera. In our prototype mapping application, the ROV's pose is found using extended Kalman filtering on measurements from the overhead camera, inertial, and pressure sensors; while objects are detected with a deep neural network in the ROV camera stream. Validation experiments are performed for pose estimation, detection, and mapping. The litter detection dataset and code are made publicly available.
Active search and coverage using point-cloud reinforcement learning
Dec 18, 2023



We consider a problem in which the trajectory of a mobile 3D sensor must be optimized so that certain objects are both found in the overall scene and covered by the point cloud, as fast as possible. This problem is called target search and coverage, and the paper provides an end-to-end deep reinforcement learning (RL) solution to solve it. The deep neural network combines four components: deep hierarchical feature learning occurs in the first stage, followed by multi-head transformers in the second, max-pooling and merging with bypassed information to preserve spatial relationships in the third, and a distributional dueling network in the last stage. To evaluate the method, a simulator is developed where cylinders must be found by a Kinect sensor. A network architecture study shows that deep hierarchical feature learning works for RL and that by using farthest point sampling (FPS) we can reduce the amount of points and achieve not only a reduction of the network size but also better results. We also show that multi-head attention for point-clouds helps to learn the agent faster but converges to the same outcome. Finally, we compare RL using the best network with a greedy baseline that maximizes immediate rewards and requires for that purpose an oracle that predicts the next observation. We decided RL achieves significantly better and more robust results than the greedy strategy.
3D exploration-based search for multiple targets using a UAV
Dec 18, 2023Consider an unmanned aerial vehicle (UAV) that searches for an unknown number of targets at unknown positions in 3D space. A particle filter uses imperfect measurements about the targets to update an intensity function that represents the expected number of targets. We propose a receding-horizon planner that selects the next UAV position by maximizing a joint, exploration and target-refinement objective. Confidently localized targets are saved and removed from consideration. A nonlinear controller with an obstacle-avoidance component is used to reach the desired waypoints. We demonstrate the performance of our approach through a series of simulations, as well as in real-robot experiments with a Parrot Mambo drone that searches for targets from a constant altitude. The proposed planner works better than a lawnmower and a target-refinement-only method.
Underwater Robot Pose Estimation Using Acoustic Methods and Intermittent Position Measurements at the Surface
Dec 18, 2023Global positioning systems can provide sufficient positioning accuracy for large scale robotic tasks in open environments. However, in underwater environments, these systems cannot be directly used, and measuring the position of underwater robots becomes more difficult. In this paper we first evaluate the performance of existing pose estimation techniques for an underwater robot equipped with commonly used sensors for underwater control and pose estimation, in a simulated environment. In our case these sensors are inertial measurement units, Doppler velocity log sensors, and ultra-short baseline sensors. Secondly, for situations in which underwater estimation suffers from drift, we investigate the benefit of intermittently correcting the position using a high-precision surface-based sensor, such as regular GPS or an assisting unmanned aerial vehicle that tracks the underwater robot from above using a camera.
Path-aware optimistic optimization for a mobile robot
Dec 18, 2023We consider problems in which a mobile robot samples an unknown function defined over its operating space, so as to find a global optimum of this function. The path traveled by the robot matters, since it influences energy and time requirements. We consider a branch-and-bound algorithm called deterministic optimistic optimization, and extend it to the path-aware setting, obtaining path-aware optimistic optimization (OOPA). In this new algorithm, the robot decides how to move next via an optimal control problem that maximizes the long-term impact of the robot trajectory on lowering the upper bound, weighted by bound and function values to focus the search on the optima. An online version of value iteration is used to solve an approximate version of this optimal control problem. OOPA is evaluated in extensive experiments in two dimensions, where it does better than path-unaware and local-optimization baselines.
Two-Channel Extended Kalman Filtering with Intermittent Measurements
Dec 18, 2023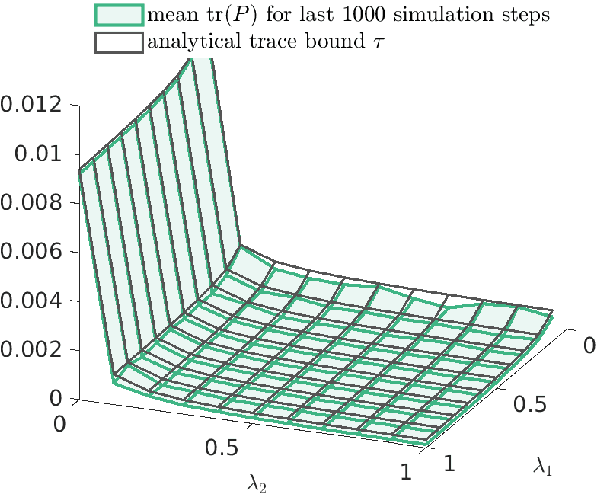
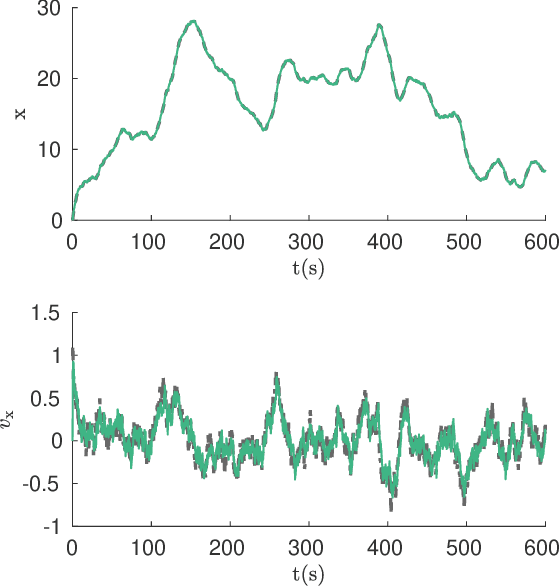
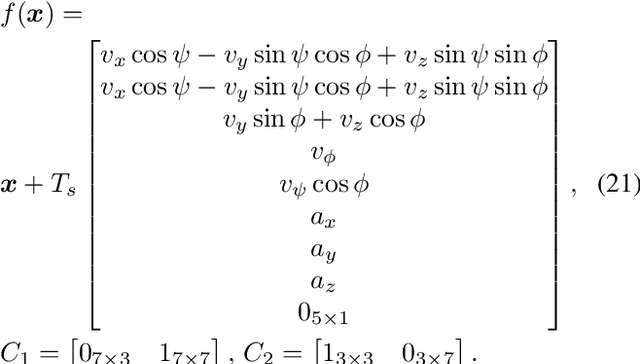
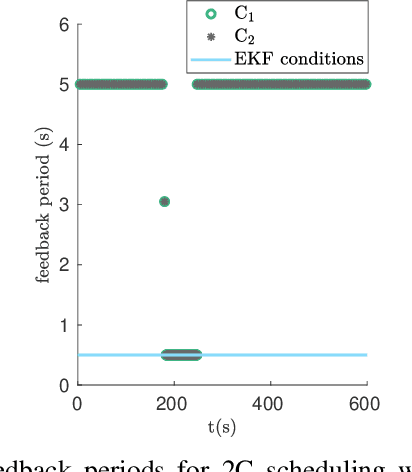
We consider two nonlinear state estimation problems in a setting where an extended Kalman filter receives measurements from two sets of sensors via two channels (2C). In the stochastic-2C problem, the channels drop measurements stochastically, whereas in 2C scheduling, the estimator chooses when to read each channel. In the first problem, we generalize linear-case 2C analysis to obtain -- for a given pair of channel arrival rates -- boundedness conditions for the trace of the error covariance, as well as a worst-case upper bound. For scheduling, an optimization problem is solved to find arrival rates that balance low channel usage with low trace bounds, and channels are read deterministically with the expected periods corresponding to these arrival rates. We validate both solutions in simulations for linear and nonlinear dynamics; as well as in a real experiment with an underwater robot whose position is being intermittently found in a UAV camera image.
ObserveNet Control: A Vision-Dynamics Learning Approach to Predictive Control in Autonomous Vehicles
Jul 19, 2021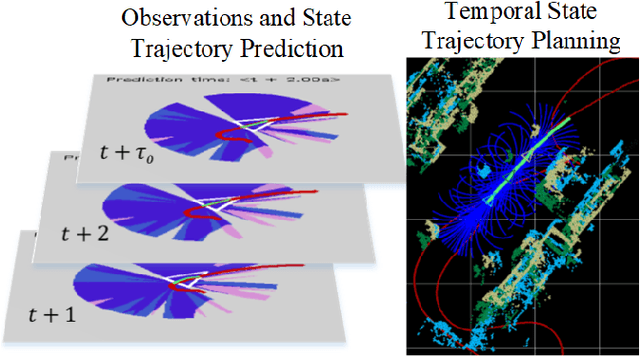
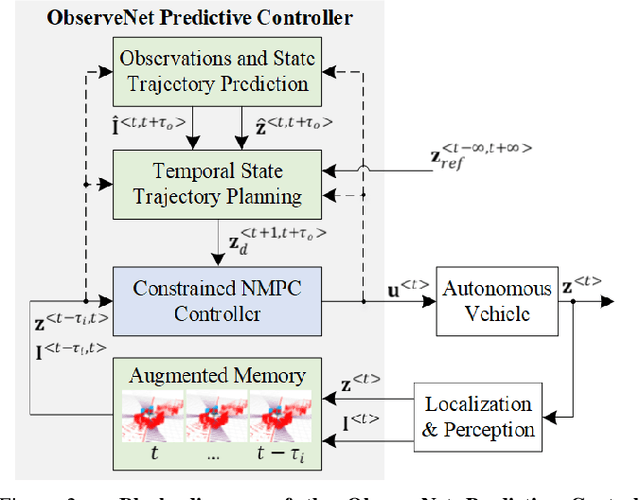
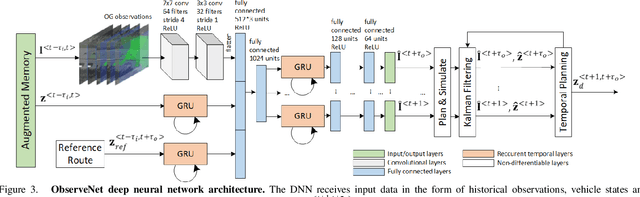
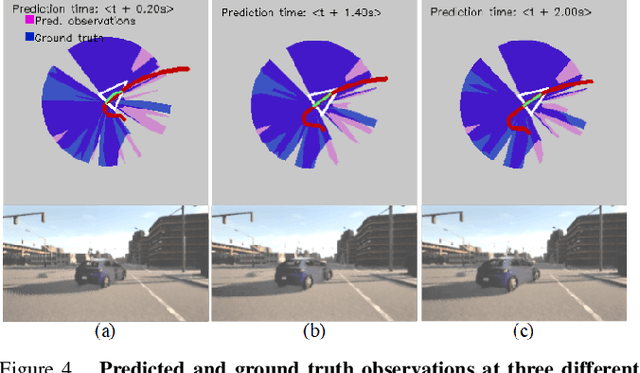
A key component in autonomous driving is the ability of the self-driving car to understand, track and predict the dynamics of the surrounding environment. Although there is significant work in the area of object detection, tracking and observations prediction, there is no prior work demonstrating that raw observations prediction can be used for motion planning and control. In this paper, we propose ObserveNet Control, which is a vision-dynamics approach to the predictive control problem of autonomous vehicles. Our method is composed of a: i) deep neural network able to confidently predict future sensory data on a time horizon of up to 10s and ii) a temporal planner designed to compute a safe vehicle state trajectory based on the predicted sensory data. Given the vehicle's historical state and sensing data in the form of Lidar point clouds, the method aims to learn the dynamics of the observed driving environment in a self-supervised manner, without the need to manually specify training labels. The experiments are performed both in simulation and real-life, using CARLA and RovisLab's AMTU mobile platform as a 1:4 scaled model of a car. We evaluate the capabilities of ObserveNet Control in aggressive driving contexts, such as overtaking maneuvers or side cut-off situations, while comparing the results with a baseline Dynamic Window Approach (DWA) and two state-of-the-art imitation learning systems, that is, Learning by Cheating (LBC) and World on Rails (WOR).
Spectral Normalisation for Deep Reinforcement Learning: an Optimisation Perspective
May 11, 2021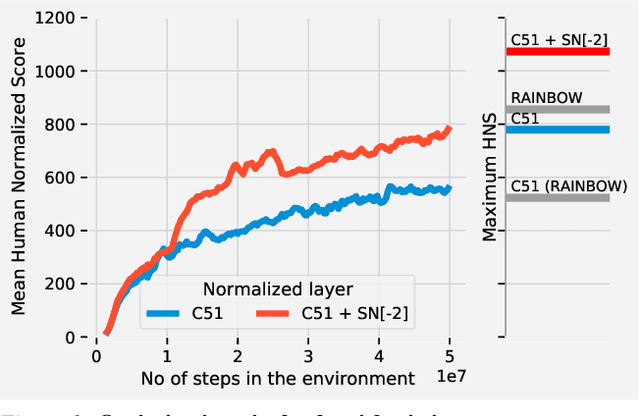
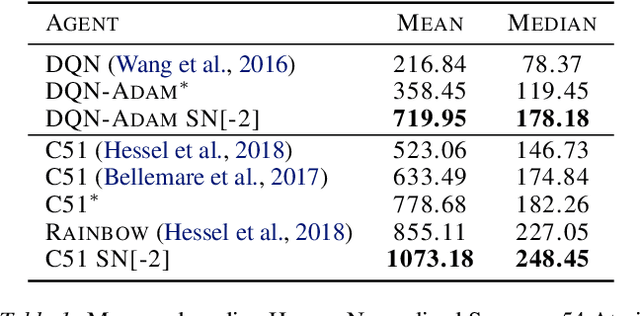
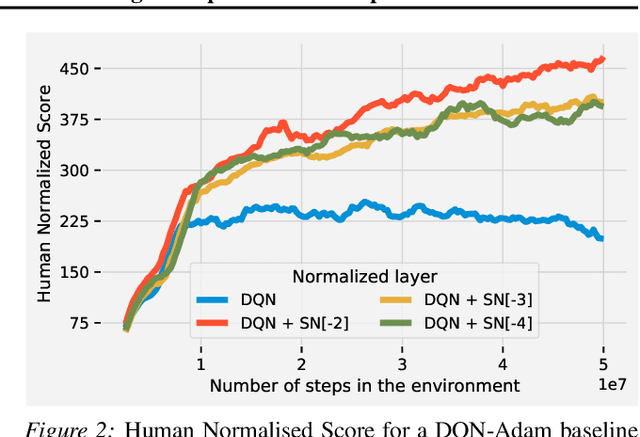

Most of the recent deep reinforcement learning advances take an RL-centric perspective and focus on refinements of the training objective. We diverge from this view and show we can recover the performance of these developments not by changing the objective, but by regularising the value-function estimator. Constraining the Lipschitz constant of a single layer using spectral normalisation is sufficient to elevate the performance of a Categorical-DQN agent to that of a more elaborated \rainbow{} agent on the challenging Atari domain. We conduct ablation studies to disentangle the various effects normalisation has on the learning dynamics and show that is sufficient to modulate the parameter updates to recover most of the performance of spectral normalisation. These findings hint towards the need to also focus on the neural component and its learning dynamics to tackle the peculiarities of Deep Reinforcement Learning.