 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive search and coverage using point-cloud reinforcement learning
Dec 18, 2023



We consider a problem in which the trajectory of a mobile 3D sensor must be optimized so that certain objects are both found in the overall scene and covered by the point cloud, as fast as possible. This problem is called target search and coverage, and the paper provides an end-to-end deep reinforcement learning (RL) solution to solve it. The deep neural network combines four components: deep hierarchical feature learning occurs in the first stage, followed by multi-head transformers in the second, max-pooling and merging with bypassed information to preserve spatial relationships in the third, and a distributional dueling network in the last stage. To evaluate the method, a simulator is developed where cylinders must be found by a Kinect sensor. A network architecture study shows that deep hierarchical feature learning works for RL and that by using farthest point sampling (FPS) we can reduce the amount of points and achieve not only a reduction of the network size but also better results. We also show that multi-head attention for point-clouds helps to learn the agent faster but converges to the same outcome. Finally, we compare RL using the best network with a greedy baseline that maximizes immediate rewards and requires for that purpose an oracle that predicts the next observation. We decided RL achieves significantly better and more robust results than the greedy strategy.
Are Gradient-based Saliency Maps Useful in Deep Reinforcement Learning?
Dec 02, 2020


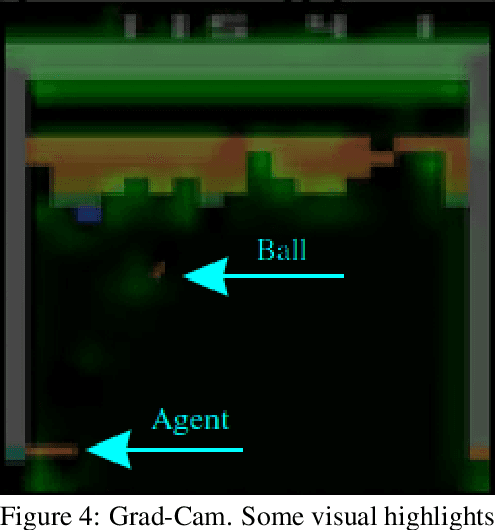
Deep Reinforcement Learning (DRL) connects the classic Reinforcement Learning algorithms with Deep Neural Networks. A problem in DRL is that CNNs are black-boxes and it is hard to understand the decision-making process of agents. In order to be able to use RL agents in highly dangerous environments for humans and machines, the developer needs a debugging tool to assure that the agent does what is expected. Currently, rewards are primarily used to interpret how well an agent is learning. However, this can lead to deceptive conclusions if the agent receives more rewards by memorizing a policy and not learning to respond to the environment. In this work, it is shown that this problem can be recognized with the help of gradient visualization techniques. This work brings some of the best-known visualization methods from the field of image classification to the area of Deep Reinforcement Learning. Furthermore, two new visualization techniques have been developed, one of which provides particularly good results. It is being proven to what extent the algorithms can be used in the area of Reinforcement learning. Also, the question arises on how well the DRL algorithms can be visualized across different environments with varying visualization techniques.