 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextual Multi-Task Reinforcement Learning for Autonomous Reef Monitoring
Apr 14, 2026Although autonomous underwater vehicles promise the capability of marine ecosystem monitoring, their deployment is fundamentally limited by the difficulty of controlling vehicles under highly uncertain and non-stationary underwater dynamics. To address these challenges, we employ a data-driven reinforcement learning approach to compensate for unknown dynamics and task variations.Traditional single-task reinforcement learning has a tendency to overfit the training environment, thus, limit the long-term usefulness of the learnt policy. Hence, we propose to use a contextual multi-task reinforcement learning paradigm instead, allowing us to learn controllers that can be reused for various tasks, e.g., detecting oysters in one reef and detecting corals in another. We evaluate whether contextual multi-task reinforcement learning can efficiently learn robust and generalisable control policies for autonomous underwater reef monitoring. We train a single context-dependent policy that is able to solve multiple related monitoring tasks in a simulated reef environment in HoloOcean. In our experiments, we empirically evaluate the contextual policies regarding sample-efficiency, zero-shot generalisation to unseen tasks, and robustness to varying water currents. By utilising multi-task reinforcement learning, we aim to improve the training effectiveness, as well as the reusability of learnt policies to take a step towards more sustainable procedures in autonomous reef monitoring.
DINO-Explorer: Active Underwater Discovery via Ego-Motion Compensated Semantic Predictive Coding
Apr 14, 2026Marine ecosystem degradation necessitates continuous, scientifically selective underwater monitoring. However, most autonomous underwater vehicles (AUVs) operate as passive data loggers, capturing exhaustive video for offline review and frequently missing transient events of high scientific value. Transitioning to active perception requires a causal, online signal that highlights significant phenomena while suppressing maneuver-induced visual changes. We propose DINO-Explorer, a novelty-aware perception framework driven by a continuous semantic surprise signal. Operating within the latent space of a frozen DINOv3 foundation model, it leverages a lightweight, action-conditioned recurrent predictor to anticipate short-horizon semantic evolution. An efference-copy-inspired module utilizes globally pooled optical flow to discount self-induced visual changes without suppressing genuine environmental novelty. We evaluate this signal on the downstream task of asynchronous event triage under variant telemetry constraints. Results demonstrate that DINO-Explorer provides a robust, bandwidth-efficient attention mechanism. At a fixed operating point, the system retains 78.8% of post-discovery human-reviewer consensus events with a 56.8% trigger confirmation rate, effectively surfacing mission-relevant phenomena. Crucially, ego-motion conditioning suppresses 45.5% of false positives relative to an uncompensated surprise signal baseline. In a replay-side Pareto ablation study, DINO-Explorer robustly dominates the validated peak F1 versus telemetry bandwidth frontier, reducing telemetry bandwidth by 48.2% at the selected operating point while maintaining a 62.2% peak F1 score, successfully concentrating data transmission around human-verified novelty events.
Adaptive Model-Base Control of Quadrupeds via Online System Identification using Kalman Filter
Jun 16, 2025Many real-world applications require legged robots to be able to carry variable payloads. Model-based controllers such as model predictive control (MPC) have become the de facto standard in research for controlling these systems. However, most model-based control architectures use fixed plant models, which limits their applicability to different tasks. In this paper, we present a Kalman filter (KF) formulation for online identification of the mass and center of mass (COM) of a four-legged robot. We evaluate our method on a quadrupedal robot carrying various payloads and find that it is more robust to strong measurement noise than classical recursive least squares (RLS) methods. Moreover, it improves the tracking performance of the model-based controller with varying payloads when the model parameters are adjusted at runtime.
Bayesian Inverse Physics for Neuro-Symbolic Robot Learning
Jun 10, 2025Real-world robotic applications, from autonomous exploration to assistive technologies, require adaptive, interpretable, and data-efficient learning paradigms. While deep learning architectures and foundation models have driven significant advances in diverse robotic applications, they remain limited in their ability to operate efficiently and reliably in unknown and dynamic environments. In this position paper, we critically assess these limitations and introduce a conceptual framework for combining data-driven learning with deliberate, structured reasoning. Specifically, we propose leveraging differentiable physics for efficient world modeling, Bayesian inference for uncertainty-aware decision-making, and meta-learning for rapid adaptation to new tasks. By embedding physical symbolic reasoning within neural models, robots could generalize beyond their training data, reason about novel situations, and continuously expand their knowledge. We argue that such hybrid neuro-symbolic architectures are essential for the next generation of autonomous systems, and to this end, we provide a research roadmap to guide and accelerate their development.
Reinforcement Learning for Robust Athletic Intelligence: Lessons from the 2nd 'AI Olympics with RealAIGym' Competition
Mar 19, 2025In the field of robotics many different approaches ranging from classical planning over optimal control to reinforcement learning (RL) are developed and borrowed from other fields to achieve reliable control in diverse tasks. In order to get a clear understanding of their individual strengths and weaknesses and their applicability in real world robotic scenarios is it important to benchmark and compare their performances not only in a simulation but also on real hardware. The '2nd AI Olympics with RealAIGym' competition was held at the IROS 2024 conference to contribute to this cause and evaluate different controllers according to their ability to solve a dynamic control problem on an underactuated double pendulum system with chaotic dynamics. This paper describes the four different RL methods submitted by the participating teams, presents their performance in the swing-up task on a real double pendulum, measured against various criteria, and discusses their transferability from simulation to real hardware and their robustness to external disturbances.
Benchmarking Different QP Formulations and Solvers for Dynamic Quadrupedal Walking
Feb 03, 2025
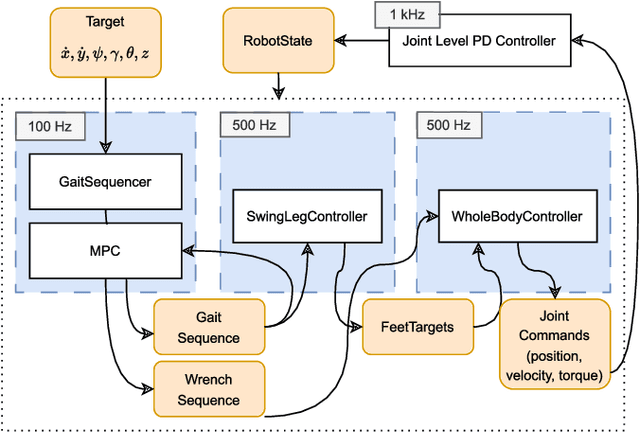
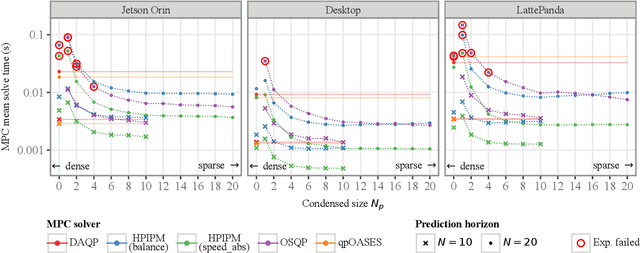
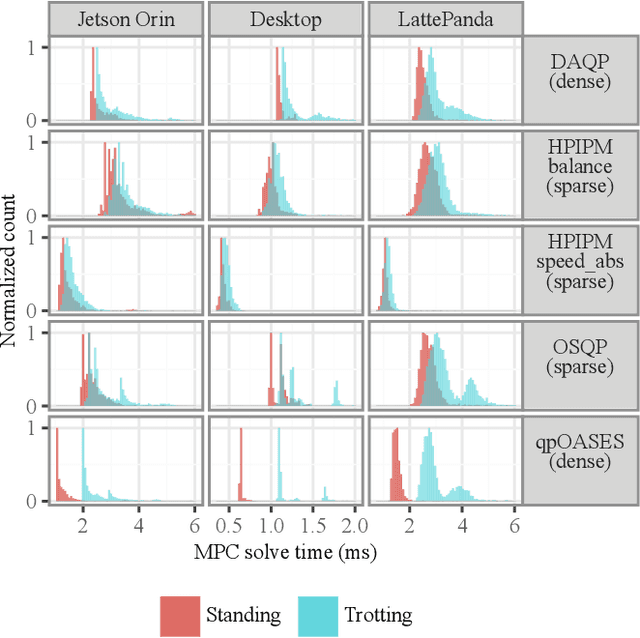
Quadratic Programs (QPs) are widely used in the control of walking robots, especially in Model Predictive Control (MPC) and Whole-Body Control (WBC). In both cases, the controller design requires the formulation of a QP and the selection of a suitable QP solver, both requiring considerable time and expertise. While computational performance benchmarks exist for QP solvers, studies comparing optimal combinations of computational hardware (HW), QP formulation, and solver performance are lacking. In this work, we compare dense and sparse QP formulations, and multiple solving methods on different HW architectures, focusing on their computational efficiency in dynamic walking of four legged robots using MPC. We introduce the Solve Frequency per Watt (SFPW) as a performance measure to enable a cross hardware comparison of the efficiency of QP solvers. We also benchmark different QP solvers for WBC that we use for trajectory stabilization in quadrupedal walking. As a result, this paper provides recommendations for the selection of QP formulations and solvers for different HW architectures in walking robots and indicates which problems should be devoted the greater technical effort in this domain in future.
Sitting, Standing and Walking Control of the Series-Parallel Hybrid Recupera-Reha Exoskeleton
Oct 08, 2024



This paper presents advancements in the functionalities of the Recupera-Reha lower extremity exoskeleton robot. The exoskeleton features a series-parallel hybrid design characterized by multiple kinematic loops resulting in 148 degrees of freedom in its spanning tree and 102 independent loop closure constraints, which poses significant challenges for modeling and control. To address these challenges, we applied an optimal control approach to generate feasible trajectories such as sitting, standing, and static walking, and tested these trajectories on the exoskeleton robot. Our method efficiently solves the optimal control problem using a serial abstraction of the model to generate trajectories. It then utilizes the full series-parallel hybrid model, which takes all the kinematic loop constraints into account to generate the final actuator commands. The experimental results demonstrate the effectiveness of our approach in generating the desired motions for the exoskeleton.
Bayesian Inverse Graphics for Few-Shot Concept Learning
Sep 12, 2024Humans excel at building generalizations of new concepts from just one single example. Contrary to this, current computer vision models typically require large amount of training samples to achieve a comparable accuracy. In this work we present a Bayesian model of perception that learns using only minimal data, a prototypical probabilistic program of an object. Specifically, we propose a generative inverse graphics model of primitive shapes, to infer posterior distributions over physically consistent parameters from one or several images. We show how this representation can be used for downstream tasks such as few-shot classification and pose estimation. Our model outperforms existing few-shot neural-only classification algorithms and demonstrates generalization across varying lighting conditions, backgrounds, and out-of-distribution shapes. By design, our model is uncertainty-aware and uses our new differentiable renderer for optimizing global scene parameters through gradient descent, sampling posterior distributions over object parameters with Markov Chain Monte Carlo (MCMC), and using a neural based likelihood function.
Model Predictive Parkour Control of a Monoped Hopper in Dynamically Changing Environments
Aug 26, 2024
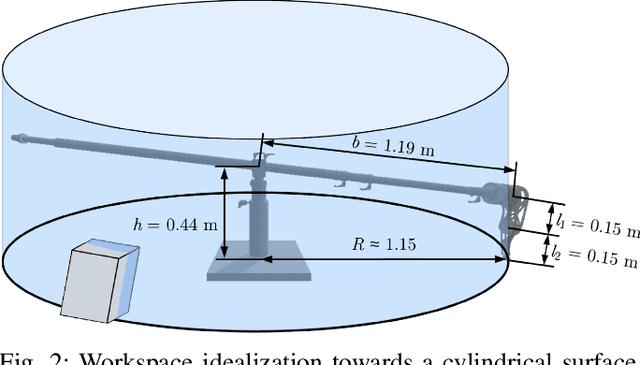
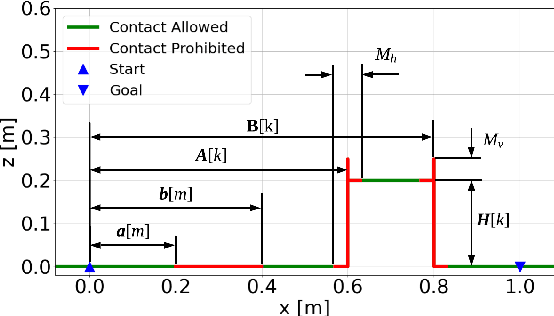
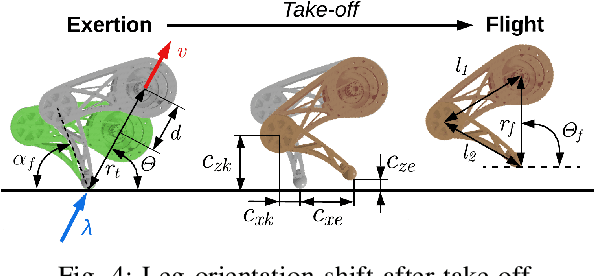
A great advantage of legged robots is their ability to operate on particularly difficult and obstructed terrain, which demands dynamic, robust, and precise movements. The study of obstacle courses provides invaluable insights into the challenges legged robots face, offering a controlled environment to assess and enhance their capabilities. Traversing it with a one-legged hopper introduces intricate challenges, such as planning over contacts and dealing with flight phases, which necessitates a sophisticated controller. A novel model predictive parkour controller is introduced, that finds an optimal path through a real-time changing obstacle course with mixed integer motion planning. The execution of this optimized path is then achieved through a state machine employing a PD control scheme with feedforward torques, ensuring robust and accurate performance.
MARLIN: A Cloud Integrated Robotic Solution to Support Intralogistics in Retail
Jul 02, 2024In this paper, we present the service robot MARLIN and its integration with the K4R platform, a cloud system for complex AI applications in retail. At its core, this platform contains so-called semantic digital twins, a semantically annotated representation of the retail store. MARLIN continuously exchanges data with the K4R platform, improving the robot's capabilities in perception, autonomous navigation, and task planning. We exploit these capabilities in a retail intralogistics scenario, specifically by assisting store employees in stocking shelves. We demonstrate that MARLIN is able to update the digital representation of the retail store by detecting and classifying obstacles, autonomously planning and executing replenishment missions, adapting to unforeseen changes in the environment, and interacting with store employees. Experiments are conducted in simulation, in a laboratory environment, and in a real store. We also describe and evaluate a novel algorithm for autonomous navigation of articulated tractor-trailer systems. The algorithm outperforms the manufacturer's proprietary navigation approach and improves MARLIN's navigation capabilities in confined spaces.