 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentiable Inverse Graphics for Zero-shot Scene Reconstruction and Robot Grasping
Feb 04, 2026Operating effectively in novel real-world environments requires robotic systems to estimate and interact with previously unseen objects. Current state-of-the-art models address this challenge by using large amounts of training data and test-time samples to build black-box scene representations. In this work, we introduce a differentiable neuro-graphics model that combines neural foundation models with physics-based differentiable rendering to perform zero-shot scene reconstruction and robot grasping without relying on any additional 3D data or test-time samples. Our model solves a series of constrained optimization problems to estimate physically consistent scene parameters, such as meshes, lighting conditions, material properties, and 6D poses of previously unseen objects from a single RGBD image and bounding boxes. We evaluated our approach on standard model-free few-shot benchmarks and demonstrated that it outperforms existing algorithms for model-free few-shot pose estimation. Furthermore, we validated the accuracy of our scene reconstructions by applying our algorithm to a zero-shot grasping task. By enabling zero-shot, physically-consistent scene reconstruction and grasping without reliance on extensive datasets or test-time sampling, our approach offers a pathway towards more data efficient, interpretable and generalizable robot autonomy in novel environments.
Bayesian Inverse Physics for Neuro-Symbolic Robot Learning
Jun 10, 2025Real-world robotic applications, from autonomous exploration to assistive technologies, require adaptive, interpretable, and data-efficient learning paradigms. While deep learning architectures and foundation models have driven significant advances in diverse robotic applications, they remain limited in their ability to operate efficiently and reliably in unknown and dynamic environments. In this position paper, we critically assess these limitations and introduce a conceptual framework for combining data-driven learning with deliberate, structured reasoning. Specifically, we propose leveraging differentiable physics for efficient world modeling, Bayesian inference for uncertainty-aware decision-making, and meta-learning for rapid adaptation to new tasks. By embedding physical symbolic reasoning within neural models, robots could generalize beyond their training data, reason about novel situations, and continuously expand their knowledge. We argue that such hybrid neuro-symbolic architectures are essential for the next generation of autonomous systems, and to this end, we provide a research roadmap to guide and accelerate their development.
Bayesian Inverse Graphics for Few-Shot Concept Learning
Sep 12, 2024Humans excel at building generalizations of new concepts from just one single example. Contrary to this, current computer vision models typically require large amount of training samples to achieve a comparable accuracy. In this work we present a Bayesian model of perception that learns using only minimal data, a prototypical probabilistic program of an object. Specifically, we propose a generative inverse graphics model of primitive shapes, to infer posterior distributions over physically consistent parameters from one or several images. We show how this representation can be used for downstream tasks such as few-shot classification and pose estimation. Our model outperforms existing few-shot neural-only classification algorithms and demonstrates generalization across varying lighting conditions, backgrounds, and out-of-distribution shapes. By design, our model is uncertainty-aware and uses our new differentiable renderer for optimizing global scene parameters through gradient descent, sampling posterior distributions over object parameters with Markov Chain Monte Carlo (MCMC), and using a neural based likelihood function.
Sanity Checks for Saliency Methods Explaining Object Detectors
Jun 04, 2023

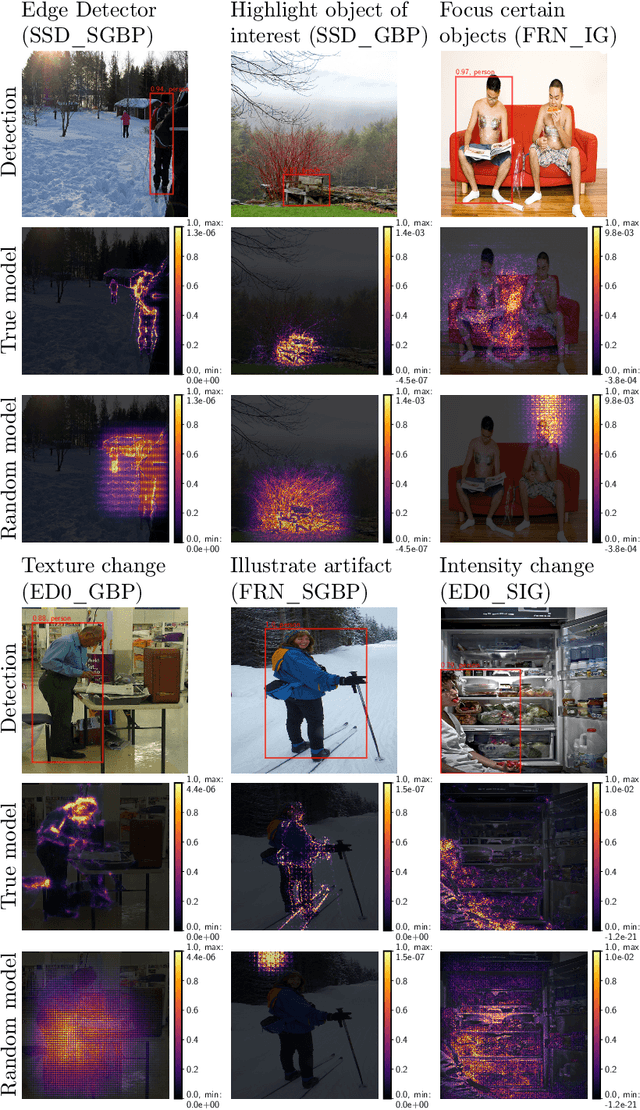

Saliency methods are frequently used to explain Deep Neural Network-based models. Adebayo et al.'s work on evaluating saliency methods for classification models illustrate certain explanation methods fail the model and data randomization tests. However, on extending the tests for various state of the art object detectors we illustrate that the ability to explain a model is more dependent on the model itself than the explanation method. We perform sanity checks for object detection and define new qualitative criteria to evaluate the saliency explanations, both for object classification and bounding box decisions, using Guided Backpropagation, Integrated Gradients, and their Smoothgrad versions, together with Faster R-CNN, SSD, and EfficientDet-D0, trained on COCO. In addition, the sensitivity of the explanation method to model parameters and data labels varies class-wise motivating to perform the sanity checks for each class. We find that EfficientDet-D0 is the most interpretable method independent of the saliency method, which passes the sanity checks with little problems.
Unsupervised Difficulty Estimation with Action Scores
Nov 23, 2020



Evaluating difficulty and biases in machine learning models has become of extreme importance as current models are now being applied in real-world situations. In this paper we present a simple method for calculating a difficulty score based on the accumulation of losses for each sample during training. We call this the action score. Our proposed method does not require any modification of the model neither any external supervision, as it can be implemented as callback that gathers information from the training process. We test and analyze our approach in two different settings: image classification, and object detection, and we show that in both settings the action score can provide insights about model and dataset biases.
Black-Box Optimization of Object Detector Scales
Oct 29, 2020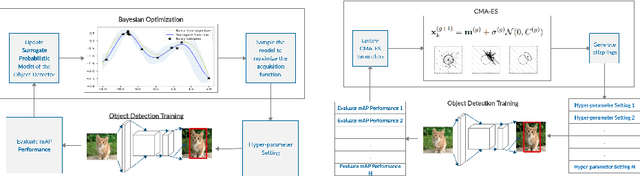
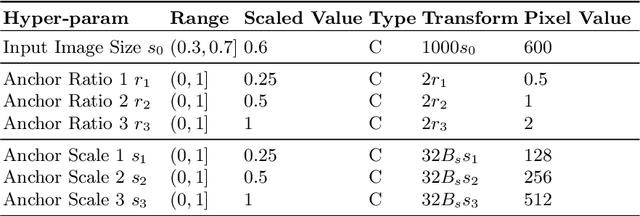
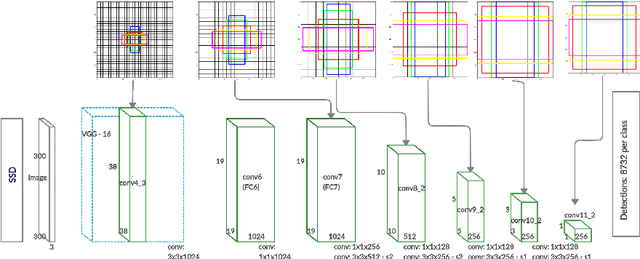
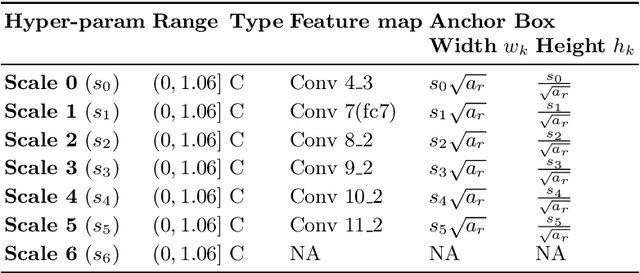
Object detectors have improved considerably in the last years by using advanced CNN architectures. However, many detector hyper-parameters are generally manually tuned, or they are used with values set by the detector authors. Automatic Hyper-parameter optimization has not been explored in improving CNN-based object detectors hyper-parameters. In this work, we propose the use of Black-box optimization methods to tune the prior/default box scales in Faster R-CNN and SSD, using Bayesian Optimization, SMAC, and CMA-ES. We show that by tuning the input image size and prior box anchor scale on Faster R-CNN mAP increases by 2% on PASCAL VOC 2007, and by 3% with SSD. On the COCO dataset with SSD there are mAP improvement in the medium and large objects, but mAP decreases by 1% in small objects. We also perform a regression analysis to find the significant hyper-parameters to tune.
Perception for Autonomous Systems (PAZ)
Oct 27, 2020
In this paper we introduce the Perception for Autonomous Systems (PAZ) software library. PAZ is a hierarchical perception library that allow users to manipulate multiple levels of abstraction in accordance to their requirements or skill level. More specifically, PAZ is divided into three hierarchical levels which we refer to as pipelines, processors, and backends. These abstractions allows users to compose functions in a hierarchical modular scheme that can be applied for preprocessing, data-augmentation, prediction and postprocessing of inputs and outputs of machine learning (ML) models. PAZ uses these abstractions to build reusable training and prediction pipelines for multiple robot perception tasks such as: 2D keypoint estimation, 2D object detection, 3D keypoint discovery, 6D pose estimation, emotion classification, face recognition, instance segmentation, and attention mechanisms.
Learning of Multi-Context Models for Autonomous Underwater Vehicles
Sep 17, 2018
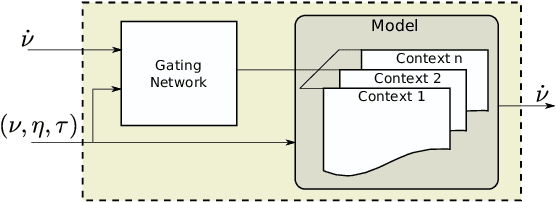
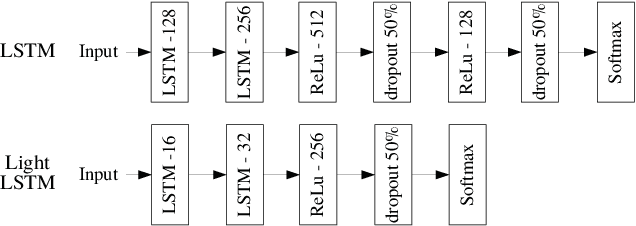
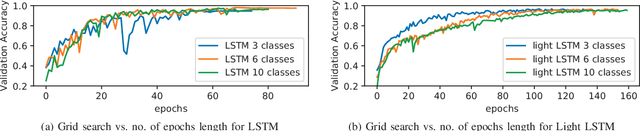
Multi-context model learning is crucial for marine robotics where several factors can cause disturbances to the system's dynamics. This work addresses the problem of identifying multiple contexts of an AUV model. We build a simulation model of the robot from experimental data, and use it to fill in the missing data and generate different model contexts. We implement an architecture based on long-short-term-memory (LSTM) networks to learn the different contexts directly from the data. We show that the LSTM network can achieve high classification accuracy compared to baseline methods, showing robustness against noise and scaling efficiently on large datasets.
Image Captioning and Classification of Dangerous Situations
Nov 07, 2017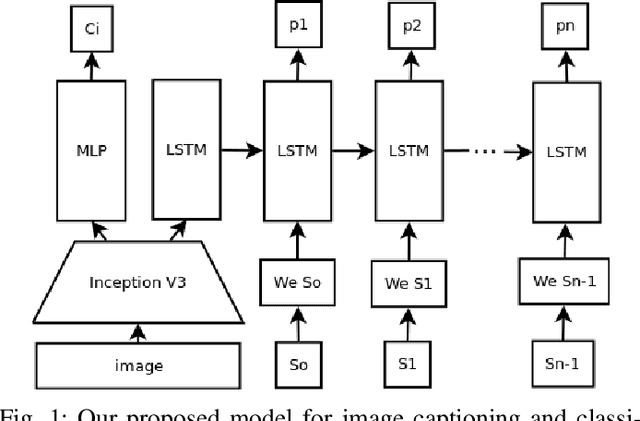



Current robot platforms are being employed to collaborate with humans in a wide range of domestic and industrial tasks. These environments require autonomous systems that are able to classify and communicate anomalous situations such as fires, injured persons, car accidents; or generally, any potentially dangerous situation for humans. In this paper we introduce an anomaly detection dataset for the purpose of robot applications as well as the design and implementation of a deep learning architecture that classifies and describes dangerous situations using only a single image as input. We report a classification accuracy of 97 % and METEOR score of 16.2. We will make the dataset publicly available after this paper is accepted.
Real-time Convolutional Neural Networks for Emotion and Gender Classification
Oct 20, 2017

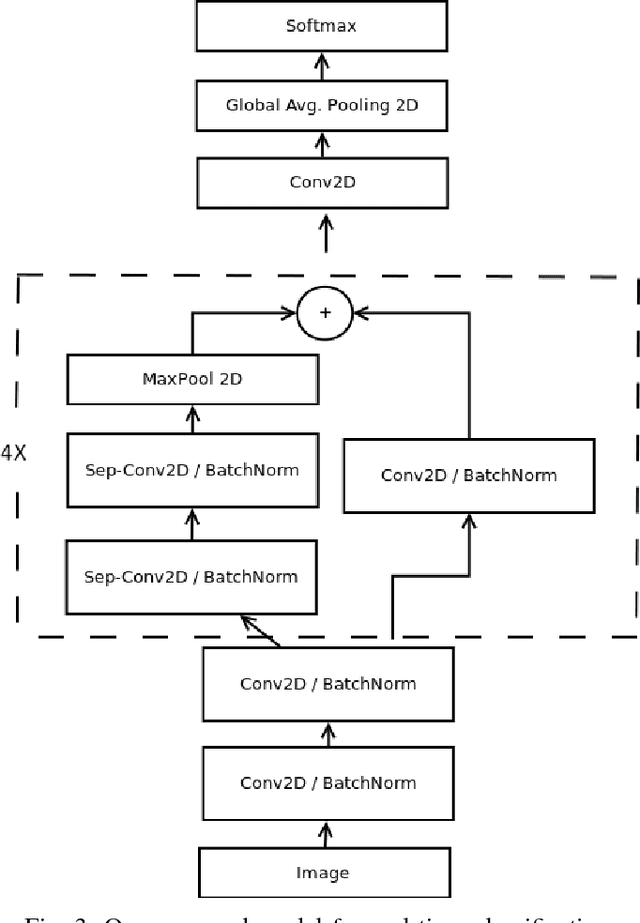
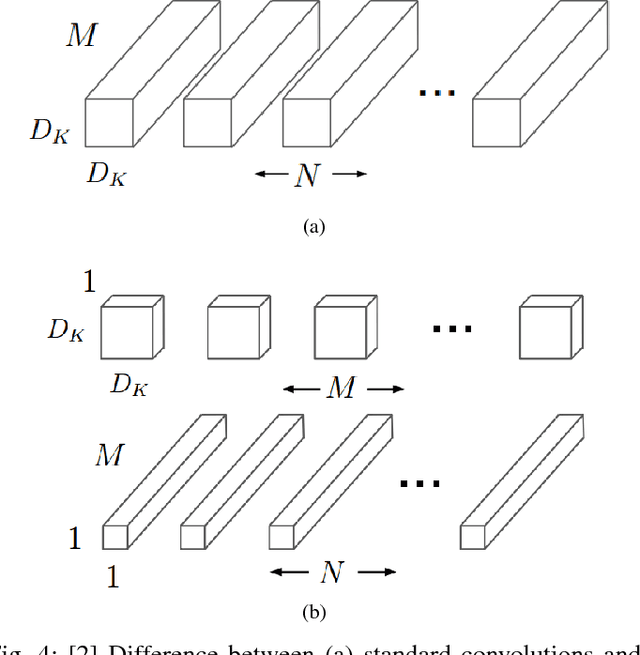
In this paper we propose an implement a general convolutional neural network (CNN) building framework for designing real-time CNNs. We validate our models by creating a real-time vision system which accomplishes the tasks of face detection, gender classification and emotion classification simultaneously in one blended step using our proposed CNN architecture. After presenting the details of the training procedure setup we proceed to evaluate on standard benchmark sets. We report accuracies of 96% in the IMDB gender dataset and 66% in the FER-2013 emotion dataset. Along with this we also introduced the very recent real-time enabled guided back-propagation visualization technique. Guided back-propagation uncovers the dynamics of the weight changes and evaluates the learned features. We argue that the careful implementation of modern CNN architectures, the use of the current regularization methods and the visualization of previously hidden features are necessary in order to reduce the gap between slow performances and real-time architectures. Our system has been validated by its deployment on a Care-O-bot 3 robot used during RoboCup@Home competitions. All our code, demos and pre-trained architectures have been released under an open-source license in our public repository.