 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForward-Looking Sonar Patch Matching: Modern CNNs, Ensembling, and Uncertainty
Aug 02, 2021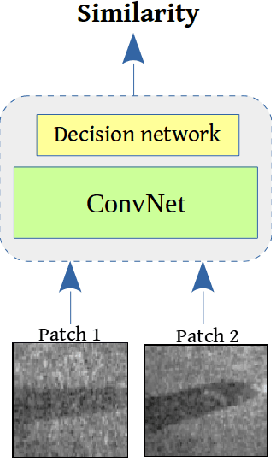
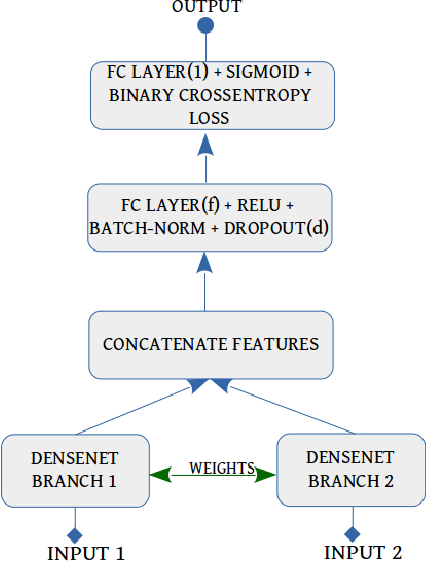
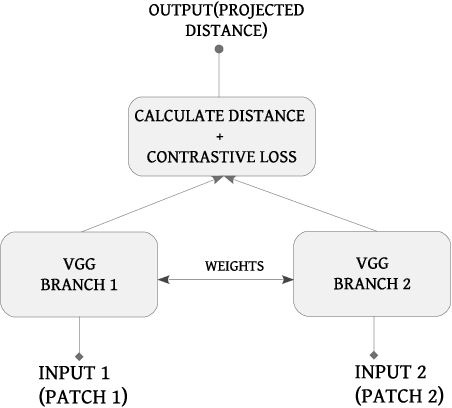
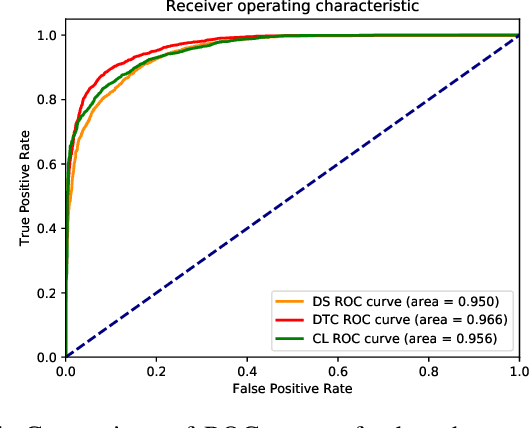
Application of underwater robots are on the rise, most of them are dependent on sonar for underwater vision, but the lack of strong perception capabilities limits them in this task. An important issue in sonar perception is matching image patches, which can enable other techniques like localization, change detection, and mapping. There is a rich literature for this problem in color images, but for acoustic images, it is lacking, due to the physics that produce these images. In this paper we improve on our previous results for this problem (Valdenegro-Toro et al, 2017), instead of modeling features manually, a Convolutional Neural Network (CNN) learns a similarity function and predicts if two input sonar images are similar or not. With the objective of improving the sonar image matching problem further, three state of the art CNN architectures are evaluated on the Marine Debris dataset, namely DenseNet, and VGG, with a siamese or two-channel architecture, and contrastive loss. To ensure a fair evaluation of each network, thorough hyper-parameter optimization is executed. We find that the best performing models are DenseNet Two-Channel network with 0.955 AUC, VGG-Siamese with contrastive loss at 0.949 AUC and DenseNet Siamese with 0.921 AUC. By ensembling the top performing DenseNet two-channel and DenseNet-Siamese models overall highest prediction accuracy obtained is 0.978 AUC, showing a large improvement over the 0.91 AUC in the state of the art.
Black-Box Optimization of Object Detector Scales
Oct 29, 2020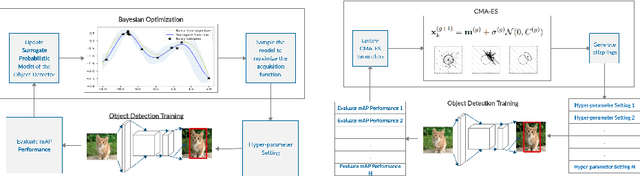
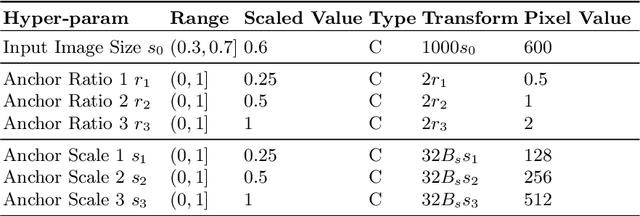
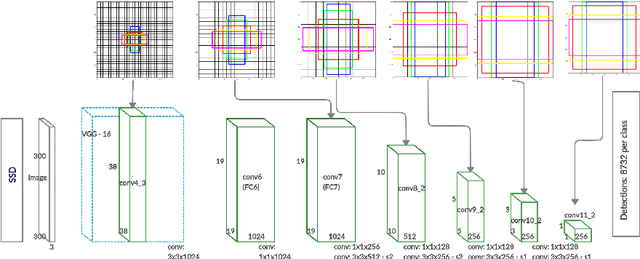
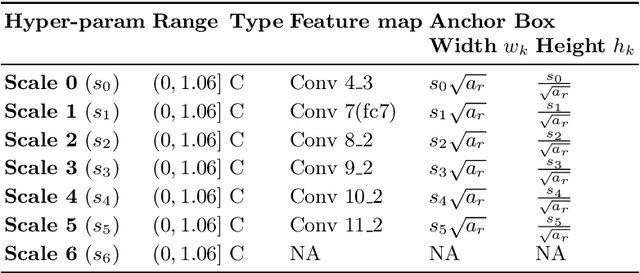
Object detectors have improved considerably in the last years by using advanced CNN architectures. However, many detector hyper-parameters are generally manually tuned, or they are used with values set by the detector authors. Automatic Hyper-parameter optimization has not been explored in improving CNN-based object detectors hyper-parameters. In this work, we propose the use of Black-box optimization methods to tune the prior/default box scales in Faster R-CNN and SSD, using Bayesian Optimization, SMAC, and CMA-ES. We show that by tuning the input image size and prior box anchor scale on Faster R-CNN mAP increases by 2% on PASCAL VOC 2007, and by 3% with SSD. On the COCO dataset with SSD there are mAP improvement in the medium and large objects, but mAP decreases by 1% in small objects. We also perform a regression analysis to find the significant hyper-parameters to tune.
Evaluating Uncertainty Estimation Methods on 3D Semantic Segmentation of Point Clouds
Jul 03, 2020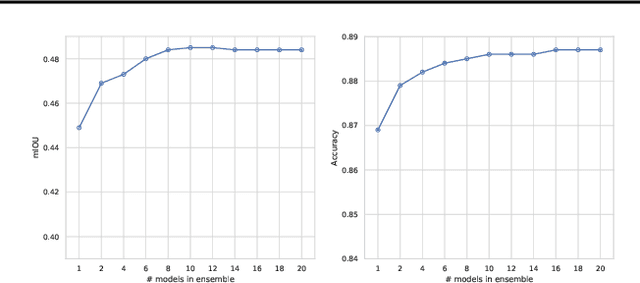
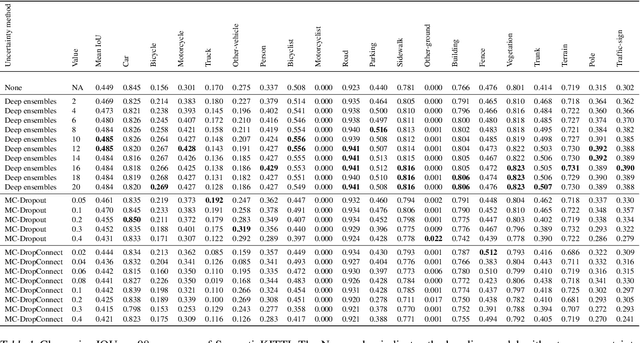
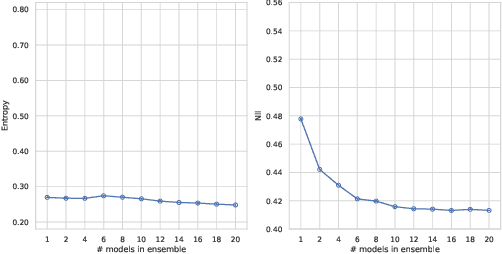
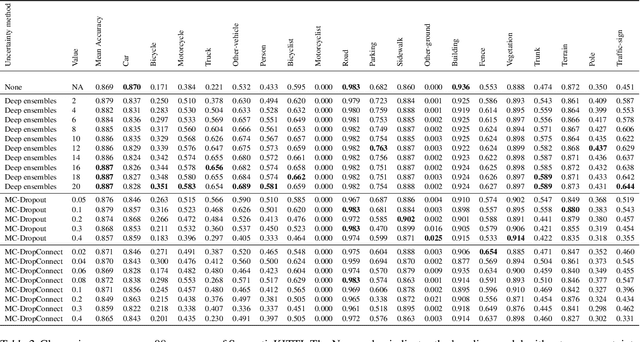
Deep learning models are extensively used in various safety critical applications. Hence these models along with being accurate need to be highly reliable. One way of achieving this is by quantifying uncertainty. Bayesian methods for UQ have been extensively studied for Deep Learning models applied on images but have been less explored for 3D modalities such as point clouds often used for Robots and Autonomous Systems. In this work, we evaluate three uncertainty quantification methods namely Deep Ensembles, MC-Dropout and MC-DropConnect on the DarkNet21Seg 3D semantic segmentation model and comprehensively analyze the impact of various parameters such as number of models in ensembles or forward passes, and drop probability values, on task performance and uncertainty estimate quality. We find that Deep Ensembles outperforms other methods in both performance and uncertainty metrics. Deep ensembles outperform other methods by a margin of 2.4% in terms of mIOU, 1.3% in terms of accuracy, while providing reliable uncertainty for decision making.
Image Captioning and Classification of Dangerous Situations
Nov 07, 2017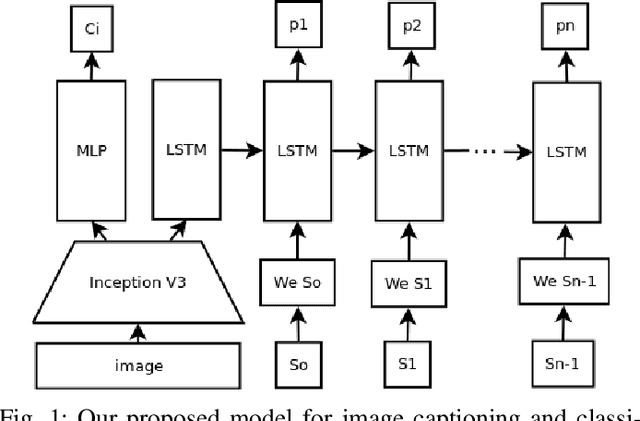



Current robot platforms are being employed to collaborate with humans in a wide range of domestic and industrial tasks. These environments require autonomous systems that are able to classify and communicate anomalous situations such as fires, injured persons, car accidents; or generally, any potentially dangerous situation for humans. In this paper we introduce an anomaly detection dataset for the purpose of robot applications as well as the design and implementation of a deep learning architecture that classifies and describes dangerous situations using only a single image as input. We report a classification accuracy of 97 % and METEOR score of 16.2. We will make the dataset publicly available after this paper is accepted.
Real-time Convolutional Neural Networks for Emotion and Gender Classification
Oct 20, 2017

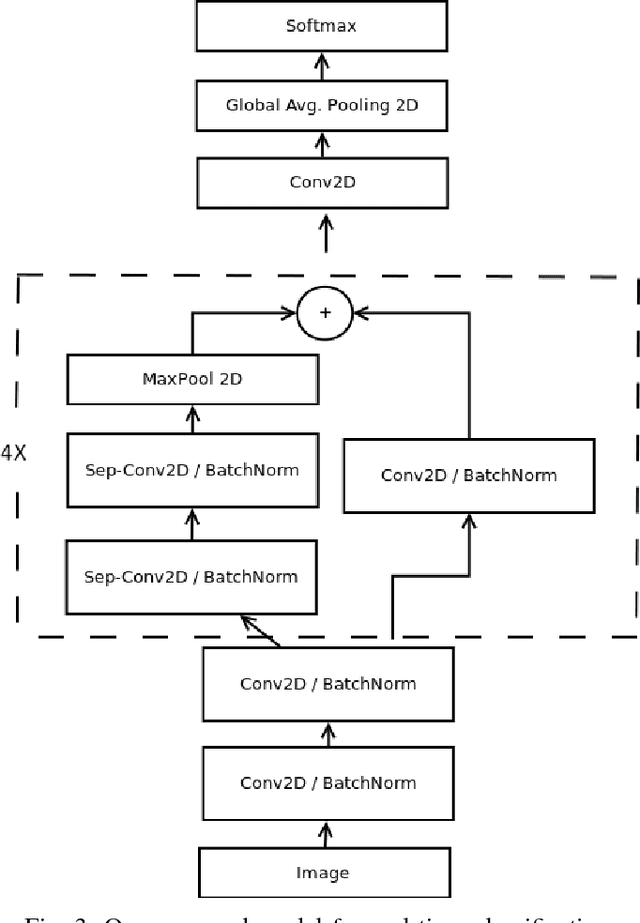
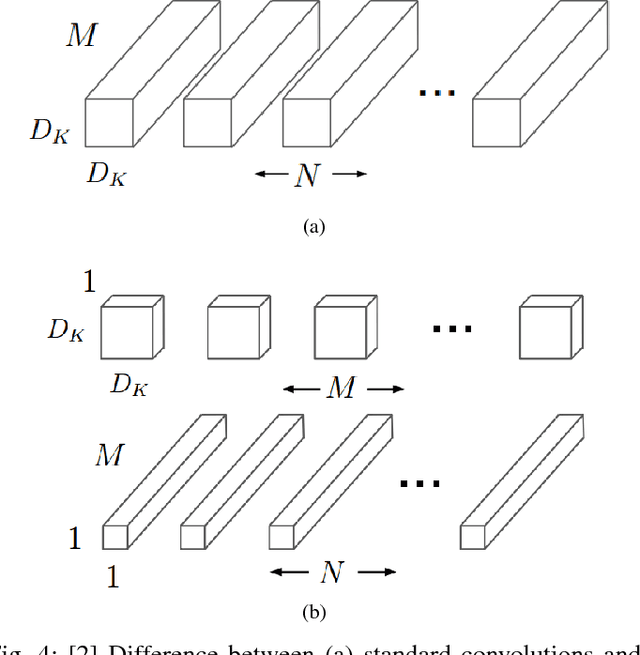
In this paper we propose an implement a general convolutional neural network (CNN) building framework for designing real-time CNNs. We validate our models by creating a real-time vision system which accomplishes the tasks of face detection, gender classification and emotion classification simultaneously in one blended step using our proposed CNN architecture. After presenting the details of the training procedure setup we proceed to evaluate on standard benchmark sets. We report accuracies of 96% in the IMDB gender dataset and 66% in the FER-2013 emotion dataset. Along with this we also introduced the very recent real-time enabled guided back-propagation visualization technique. Guided back-propagation uncovers the dynamics of the weight changes and evaluates the learned features. We argue that the careful implementation of modern CNN architectures, the use of the current regularization methods and the visualization of previously hidden features are necessary in order to reduce the gap between slow performances and real-time architectures. Our system has been validated by its deployment on a Care-O-bot 3 robot used during RoboCup@Home competitions. All our code, demos and pre-trained architectures have been released under an open-source license in our public repository.
On Recognizing Transparent Objects in Domestic Environments Using Fusion of Multiple Sensor Modalities
Jun 03, 2016
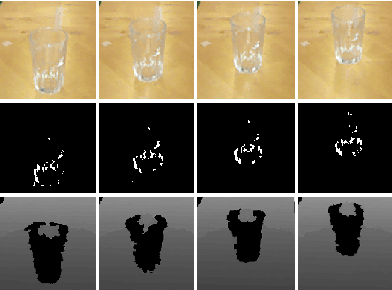
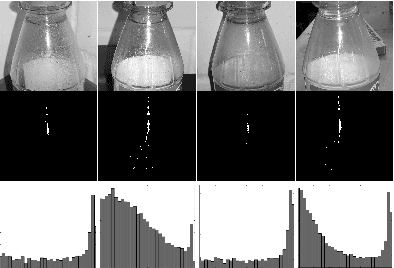
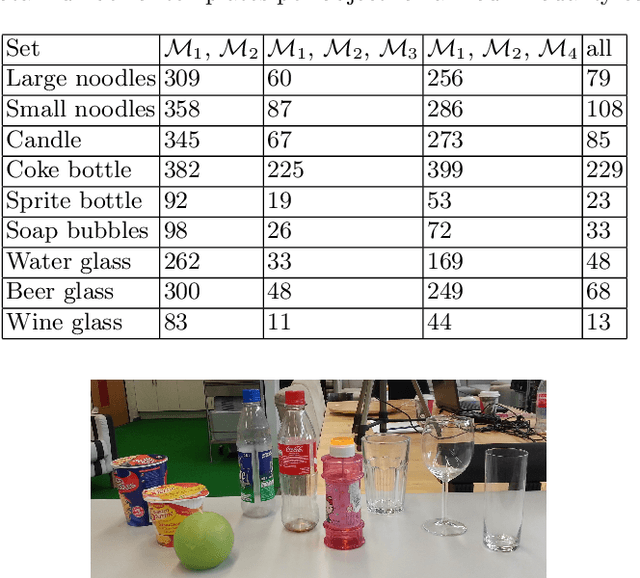
Current object recognition methods fail on object sets that include both diffuse, reflective and transparent materials, although they are very common in domestic scenarios. We show that a combination of cues from multiple sensor modalities, including specular reflectance and unavailable depth information, allows us to capture a larger subset of household objects by extending a state of the art object recognition method. This leads to a significant increase in robustness of recognition over a larger set of commonly used objects.