 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClosing the gap on tabular data with Fourier and Implicit Categorical Features
Feb 26, 2026While Deep Learning has demonstrated impressive results in applications on various data types, it continues to lag behind tree-based methods when applied to tabular data, often referred to as the last "unconquered castle" for neural networks. We hypothesize that a significant advantage of tree-based methods lies in their intrinsic capability to model and exploit non-linear interactions induced by features with categorical characteristics. In contrast, neural-based methods exhibit biases toward uniform numerical processing of features and smooth solutions, making it challenging for them to effectively leverage such patterns. We address this performance gap by using statistical-based feature processing techniques to identify features that are strongly correlated with the target once discretized. We further mitigate the bias of deep models for overly-smooth solutions, a bias that does not align with the inherent properties of the data, using Learned Fourier. We show that our proposed feature preprocessing significantly boosts the performance of deep learning models and enables them to achieve a performance that closely matches or surpasses XGBoost on a comprehensive tabular data benchmark.
Do We Always Need the Simplicity Bias? Looking for Optimal Inductive Biases in the Wild
Mar 13, 2025

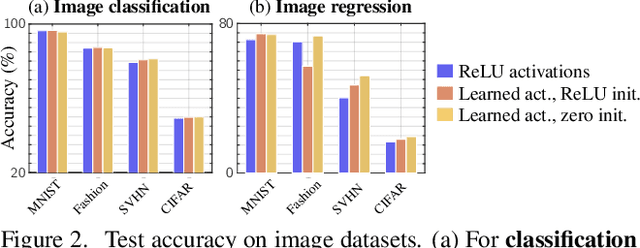
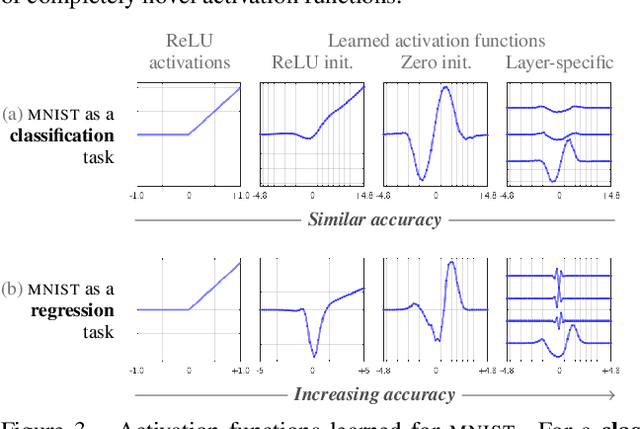
Neural architectures tend to fit their data with relatively simple functions. This "simplicity bias" is widely regarded as key to their success. This paper explores the limits of this principle. Building on recent findings that the simplicity bias stems from ReLU activations [96], we introduce a method to meta-learn new activation functions and inductive biases better suited to specific tasks. Findings: We identify multiple tasks where the simplicity bias is inadequate and ReLUs suboptimal. In these cases, we learn new activation functions that perform better by inducing a prior of higher complexity. Interestingly, these cases correspond to domains where neural networks have historically struggled: tabular data, regression tasks, cases of shortcut learning, and algorithmic grokking tasks. In comparison, the simplicity bias induced by ReLUs proves adequate on image tasks where the best learned activations are nearly identical to ReLUs and GeLUs. Implications: Contrary to popular belief, the simplicity bias of ReLU networks is not universally useful. It is near-optimal for image classification, but other inductive biases are sometimes preferable. We showed that activation functions can control these inductive biases, but future tailored architectures might provide further benefits. Advances are still needed to characterize a model's inductive biases beyond "complexity", and their adequacy with the data.
ObserveNet Control: A Vision-Dynamics Learning Approach to Predictive Control in Autonomous Vehicles
Jul 19, 2021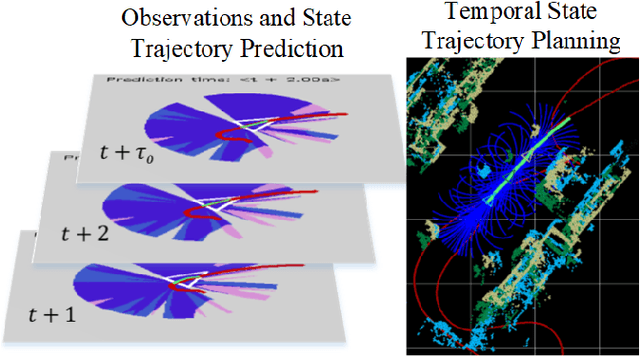
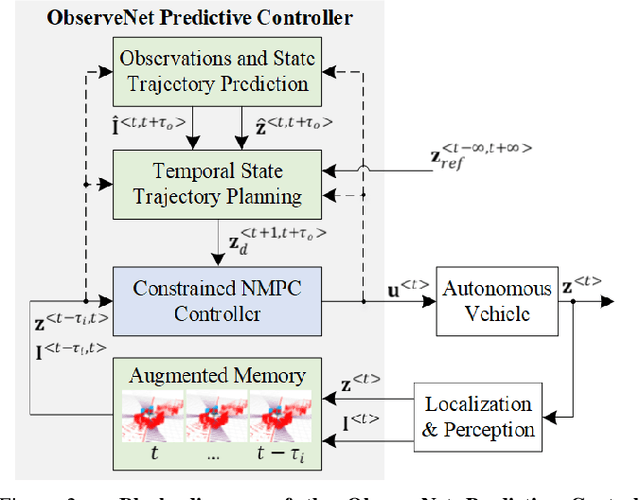
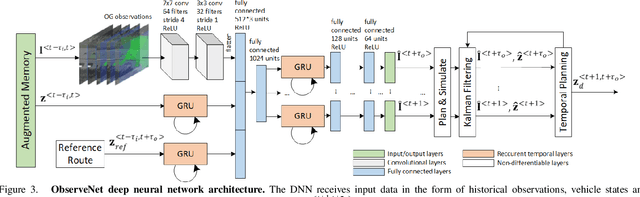
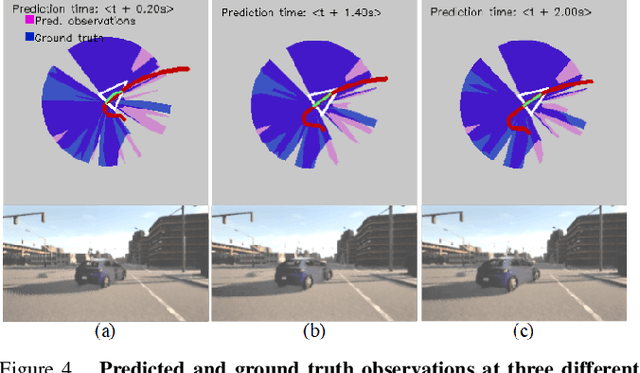
A key component in autonomous driving is the ability of the self-driving car to understand, track and predict the dynamics of the surrounding environment. Although there is significant work in the area of object detection, tracking and observations prediction, there is no prior work demonstrating that raw observations prediction can be used for motion planning and control. In this paper, we propose ObserveNet Control, which is a vision-dynamics approach to the predictive control problem of autonomous vehicles. Our method is composed of a: i) deep neural network able to confidently predict future sensory data on a time horizon of up to 10s and ii) a temporal planner designed to compute a safe vehicle state trajectory based on the predicted sensory data. Given the vehicle's historical state and sensing data in the form of Lidar point clouds, the method aims to learn the dynamics of the observed driving environment in a self-supervised manner, without the need to manually specify training labels. The experiments are performed both in simulation and real-life, using CARLA and RovisLab's AMTU mobile platform as a 1:4 scaled model of a car. We evaluate the capabilities of ObserveNet Control in aggressive driving contexts, such as overtaking maneuvers or side cut-off situations, while comparing the results with a baseline Dynamic Window Approach (DWA) and two state-of-the-art imitation learning systems, that is, Learning by Cheating (LBC) and World on Rails (WOR).
Spectral Normalisation for Deep Reinforcement Learning: an Optimisation Perspective
May 11, 2021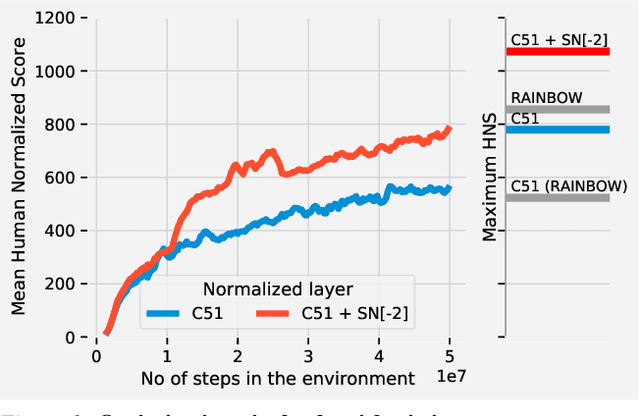
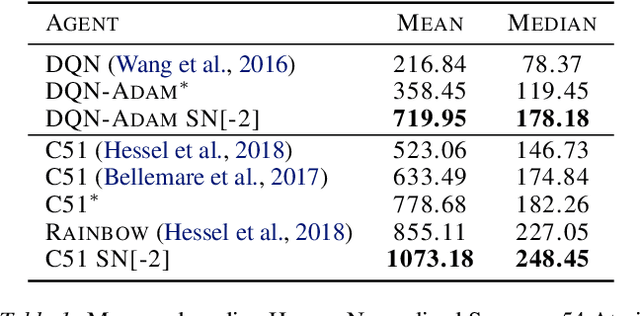
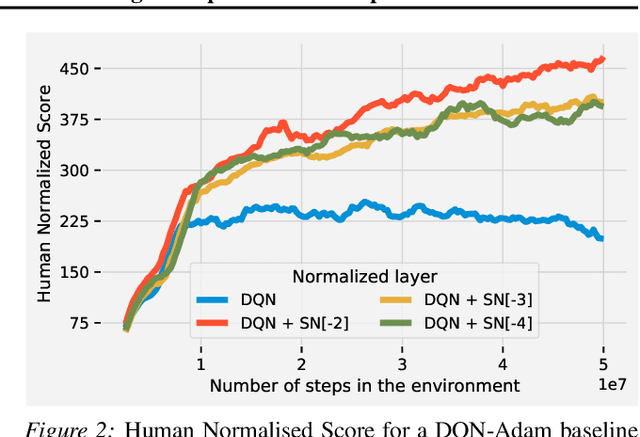

Most of the recent deep reinforcement learning advances take an RL-centric perspective and focus on refinements of the training objective. We diverge from this view and show we can recover the performance of these developments not by changing the objective, but by regularising the value-function estimator. Constraining the Lipschitz constant of a single layer using spectral normalisation is sufficient to elevate the performance of a Categorical-DQN agent to that of a more elaborated \rainbow{} agent on the challenging Atari domain. We conduct ablation studies to disentangle the various effects normalisation has on the learning dynamics and show that is sufficient to modulate the parameter updates to recover most of the performance of spectral normalisation. These findings hint towards the need to also focus on the neural component and its learning dynamics to tackle the peculiarities of Deep Reinforcement Learning.