 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo We Always Need the Simplicity Bias? Looking for Optimal Inductive Biases in the Wild
Paper and Code


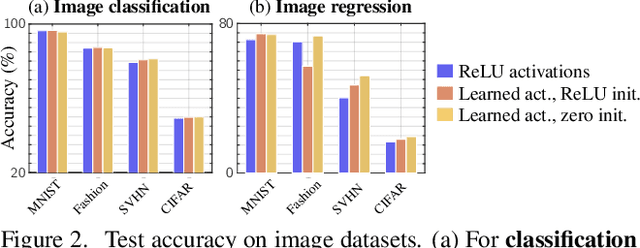
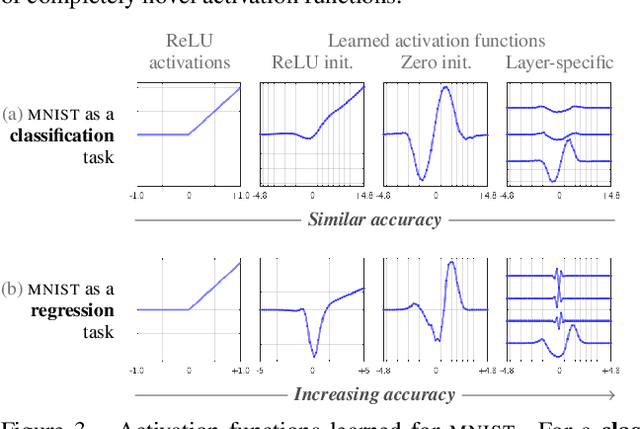
Neural architectures tend to fit their data with relatively simple functions. This "simplicity bias" is widely regarded as key to their success. This paper explores the limits of this principle. Building on recent findings that the simplicity bias stems from ReLU activations [96], we introduce a method to meta-learn new activation functions and inductive biases better suited to specific tasks. Findings: We identify multiple tasks where the simplicity bias is inadequate and ReLUs suboptimal. In these cases, we learn new activation functions that perform better by inducing a prior of higher complexity. Interestingly, these cases correspond to domains where neural networks have historically struggled: tabular data, regression tasks, cases of shortcut learning, and algorithmic grokking tasks. In comparison, the simplicity bias induced by ReLUs proves adequate on image tasks where the best learned activations are nearly identical to ReLUs and GeLUs. Implications: Contrary to popular belief, the simplicity bias of ReLU networks is not universally useful. It is near-optimal for image classification, but other inductive biases are sometimes preferable. We showed that activation functions can control these inductive biases, but future tailored architectures might provide further benefits. Advances are still needed to characterize a model's inductive biases beyond "complexity", and their adequacy with the data.