 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProcedural Pretraining: Warming Up Language Models with Abstract Data
Jan 29, 2026Pretraining directly on web-scale corpora is the de facto paradigm for building language models. We study an alternative setting where the model is initially exposed to abstract structured data, as a means to ease the subsequent acquisition of rich semantic knowledge, much like humans learn simple logic and mathematics before higher reasoning. We specifically focus on procedural data, generated by formal languages and other simple algorithms, as such abstract data. We first diagnose the algorithmic skills that different forms of procedural data can improve, often significantly. For example, on context recall (Needle-in-a-haystack), the accuracy jumps from 10 to 98% when pretraining on Dyck sequences (balanced brackets). Second, we study how these gains are reflected in pretraining larger models (up to 1.3B). We find that front-loading as little as 0.1% procedural data significantly outperforms standard pretraining on natural language, code, and informal mathematics (C4, CodeParrot, and DeepMind-Math datasets). Notably, this procedural pretraining enables the models to reach the same loss value with only 55, 67, 86% of the original data. Third, we explore the mechanisms behind and find that procedural pretraining instils non-trivial structure in both attention and MLP layers. The former is particularly important for structured domains (e.g. code), and the latter for language. Finally, we lay a path for combining multiple forms of procedural data. Our results show that procedural pretraining is a simple, lightweight means to improving performance and accelerating language model pretraining, ultimately suggesting the promise of disentangling knowledge acquisition from reasoning in LLMs.
Meta-RL Induces Exploration in Language Agents
Dec 18, 2025Reinforcement learning (RL) has enabled the training of large language model (LLM) agents to interact with the environment and to solve multi-turn long-horizon tasks. However, the RL-trained agents often struggle in tasks that require active exploration and fail to efficiently adapt from trial-and-error experiences. In this paper, we present LaMer, a general Meta-RL framework that enables LLM agents to actively explore and learn from the environment feedback at test time. LaMer consists of two key components: (i) a cross-episode training framework to encourage exploration and long-term rewards optimization; and (ii) in-context policy adaptation via reflection, allowing the agent to adapt their policy from task feedback signal without gradient update. Experiments across diverse environments show that LaMer significantly improves performance over RL baselines, with 11%, 14%, and 19% performance gains on Sokoban, MineSweeper and Webshop, respectively. Moreover, LaMer also demonstrates better generalization to more challenging or previously unseen tasks compared to the RL-trained agents. Overall, our results demonstrate that Meta-RL provides a principled approach to induce exploration in language agents, enabling more robust adaptation to novel environments through learned exploration strategies.
Can You Learn to See Without Images? Procedural Warm-Up for Vision Transformers
Nov 17, 2025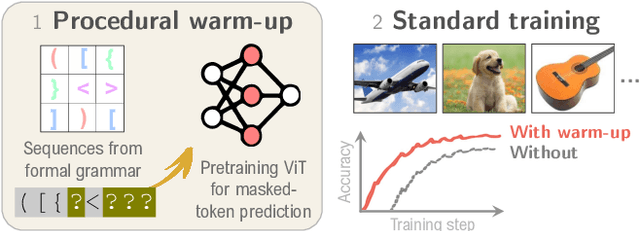


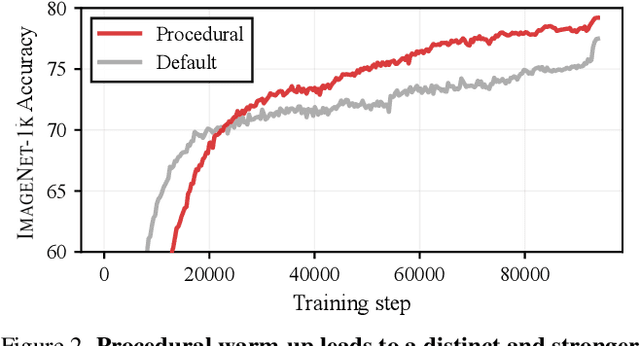
Transformers show remarkable versatility across domains, suggesting the existence of inductive biases beneficial across modalities. In this work, we explore a new way to instil such generic biases in vision transformers (ViTs) by pretraining on procedurally-generated data devoid of visual or semantic content. We generate this data with simple algorithms such as formal grammars, so the results bear no relationship to either natural or synthetic images. We use this procedurally-generated data to pretrain ViTs in a warm-up phase that bypasses their visual patch embedding mechanisms, thus encouraging the models to internalise abstract computational priors. When followed by standard image-based training, this warm-up significantly improves data efficiency, convergence speed, and downstream performance. On ImageNet-1k for example, allocating just 1% of the training budget to procedural data improves final accuracy by over 1.7%. In terms of its effect on performance, 1% procedurally generated data is thus equivalent to 28% of the ImageNet-1k data. These findings suggest a promising path toward new data-efficient and domain-agnostic pretraining strategies.
Transformers Pretrained on Procedural Data Contain Modular Structures for Algorithmic Reasoning
May 28, 2025Pretraining on large, semantically rich datasets is key for developing language models. Surprisingly, recent studies have shown that even synthetic data, generated procedurally through simple semantic-free algorithms, can yield some of the same benefits as natural language pretraining. It is unclear what specific capabilities such simple synthetic data instils in a model, where these capabilities reside in the architecture, and how they manifest within its weights. In this short paper, we identify several beneficial forms of procedural data, together with specific algorithmic reasoning skills that improve in small transformers. Our core finding is that different procedural rules instil distinct but complementary inductive structures in the model. With extensive ablations and partial-transfer experiments, we discover that these structures reside in different parts of the model. Attention layers often carry the most transferable information, but some pretraining rules impart useful structure to MLP blocks instead. Most interestingly, the structures induced by multiple rules can be composed to jointly reinforce multiple capabilities. These results suggest an exciting possibility of disentangling the acquisition of knowledge from reasoning in language models, with the goal of improving their robustness and data efficiency.
Do We Always Need the Simplicity Bias? Looking for Optimal Inductive Biases in the Wild
Mar 13, 2025

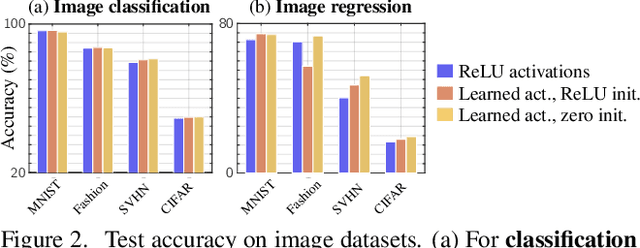
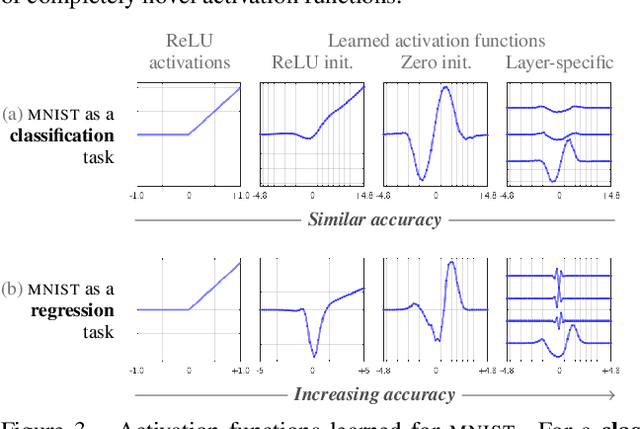
Neural architectures tend to fit their data with relatively simple functions. This "simplicity bias" is widely regarded as key to their success. This paper explores the limits of this principle. Building on recent findings that the simplicity bias stems from ReLU activations [96], we introduce a method to meta-learn new activation functions and inductive biases better suited to specific tasks. Findings: We identify multiple tasks where the simplicity bias is inadequate and ReLUs suboptimal. In these cases, we learn new activation functions that perform better by inducing a prior of higher complexity. Interestingly, these cases correspond to domains where neural networks have historically struggled: tabular data, regression tasks, cases of shortcut learning, and algorithmic grokking tasks. In comparison, the simplicity bias induced by ReLUs proves adequate on image tasks where the best learned activations are nearly identical to ReLUs and GeLUs. Implications: Contrary to popular belief, the simplicity bias of ReLU networks is not universally useful. It is near-optimal for image classification, but other inductive biases are sometimes preferable. We showed that activation functions can control these inductive biases, but future tailored architectures might provide further benefits. Advances are still needed to characterize a model's inductive biases beyond "complexity", and their adequacy with the data.
OOD-Chameleon: Is Algorithm Selection for OOD Generalization Learnable?
Oct 03, 2024Out-of-distribution (OOD) generalization is challenging because distribution shifts come in many forms. A multitude of learning algorithms exist and each can improve performance in specific OOD situations. We posit that much of the challenge of OOD generalization lies in choosing the right algorithm for the right dataset. However, such algorithm selection is often elusive under complex real-world shifts. In this work, we formalize the task of algorithm selection for OOD generalization and investigate whether it could be approached by learning. We propose a solution, dubbed OOD-Chameleon that treats the task as a supervised classification over candidate algorithms. We construct a dataset of datasets to learn from, which represents diverse types, magnitudes and combinations of shifts (covariate shift, label shift, spurious correlations). We train the model to predict the relative performance of algorithms given a dataset's characteristics. This enables a priori selection of the best learning strategy, i.e. without training various models as needed with traditional model selection. Our experiments show that the adaptive selection outperforms any individual algorithm and simple selection heuristics, on unseen datasets of controllable and realistic image data. Inspecting the model shows that it learns non-trivial data/algorithms interactions, and reveals the conditions for any one algorithm to surpass another. This opens new avenues for (1) enhancing OOD generalization with existing algorithms instead of designing new ones, and (2) gaining insights into the applicability of existing algorithms with respect to datasets' properties.
Unraveling the Key Components of OOD Generalization via Diversification
Dec 26, 2023Real-world datasets may contain multiple features that explain the training data equally well, i.e., learning any of them would lead to correct predictions on the training data. However, many of them can be spurious, i.e., lose their predictive power under a distribution shift and fail to generalize to out-of-distribution (OOD) data. Recently developed ``diversification'' methods approach this problem by finding multiple diverse hypotheses that rely on different features. This paper aims to study this class of methods and identify the key components contributing to their OOD generalization abilities. We show that (1) diversification methods are highly sensitive to the distribution of the unlabeled data used for diversification and can underperform significantly when away from a method-specific sweet spot. (2) Diversification alone is insufficient for OOD generalization. The choice of the used learning algorithm, e.g., the model's architecture and pretraining, is crucial, and using the second-best choice leads to an up to 20% absolute drop in accuracy.(3) The optimal choice of learning algorithm depends on the unlabeled data, and vice versa.Finally, we show that the above pitfalls cannot be alleviated by increasing the number of diverse hypotheses, allegedly the major feature of diversification methods. These findings provide a clearer understanding of the critical design factors influencing the OOD generalization of diversification methods. They can guide practitioners in how to use the existing methods best and guide researchers in developing new, better ones.
Test-Time Robust Personalization for Federated Learning
May 22, 2022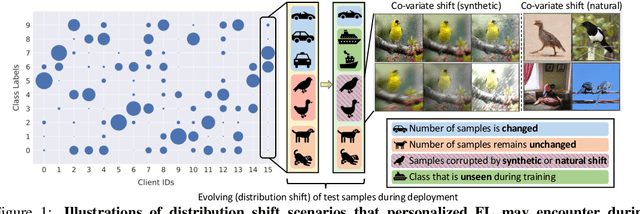
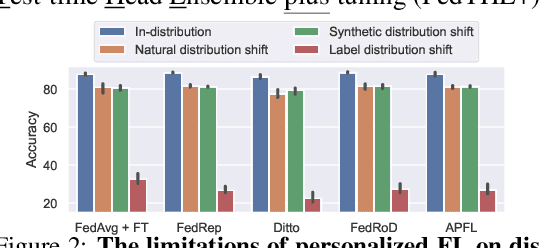

Federated Learning (FL) is a machine learning paradigm where many clients collaboratively learn a shared global model with decentralized training data. Personalization on FL model additionally adapts the global model to different clients, achieving promising results on consistent local training & test distributions. However, for real-world personalized FL applications, it is crucial to go one step further: robustifying FL models under evolving local test set during deployment, where various types of distribution shifts can arise. In this work, we identify the pitfalls of existing works under test-time distribution shifts and propose a novel test-time robust personalization method, namely Federated Test-time Head Ensemble plus tuning (FedTHE+). We illustrate the advancement of FedTHE+ (and its degraded computationally efficient variant FedTHE) over strong competitors, for training various neural architectures (CNN, ResNet, and Transformer) on CIFAR10 and ImageNet and evaluating on diverse test distributions. Along with this, we build a benchmark for assessing performance and robustness of personalized FL methods during deployment.